此部分是 计算机视觉中的信号处理与模式识别
与其说是讲述,不如说是一些经典文章的罗列以及自己的简单点评。与前一个版本不同的是,这次把所有的文章按类别归了类,并且增加了很多文献。分类的时候并没有按照传统的分类方法,而是划分成了一个个小的门类,比如SIFT,Harris都作为了单独的一类,虽然它们都可以划分到特征提取里面去。这样做的目的是希望能突出这些比较实用且比较流行的方法。为了以后维护的方便,按照字母顺序排的序。
15. RANSAC
随机抽样一致性方法,与传统的最小均方误差等完全是两个路子。在Sonka的书里面也有提到。
[1981 ACM] Random Sample Consensus
[2009 BMVC] Performance Evaluation of RANSAC Family
若引用文献:
翻译
RANSAC家族的绩效评估——http://tongtianta.site/paper/58281
作者:Sunglok Choi, Taemin Kim, Wonpil Yu
摘要 -RANSAC(随机样本共识)已在回归问题中受到异常值污染的样本的欢迎。它是许多关于鲁棒估计量的研究的里程碑,但是对它们进行了一些调查和性能分析。本文按目标进行分类:准确,快速和健壮。在各种数据分布的在线拟合中执行性能评估。平面单应性估计被用来表示真实数据的性能。
1引言
研究了从数据中对模型进行鲁棒估计的各种方法。在实践中,困难来自离群值,而其余数据则以异常值来观察。随机样本共识(RANSAC)[11]由于其简单的实现和鲁棒性而被广泛应用于此类问题。现在,它在许多计算机视觉教科书中都很常见,并且还举办了其生日研讨会,“ RANSAC 25年”,以及CVPR 2006。
在RANSAC之前有有意义的基础。在统计领域中提出了M估计量,L估计量,再估计量[15]和最小平方中位数(LMedS)[24]。他们将离群值表示为最小化问题。该公式与最小二乘法相似,该方法最小化平方误差值的总和。但是,它们使用非线性和相当复杂的损失函数,而不是误差平方。例如,LMedS尝试最小化误差值的中位数。他们需要一种数值优化算法来解决这种非线性最小化问题。在图像处理领域中还提出了霍夫变换[9]。它将数据空间中的数据(例如一条线的2D点)转换为参数空间(例如倾斜和截距)。它选择参数空间中最频繁的点作为其估计,因此需要大量内存才能保留参数空间。
RANSAC只需简单地重复两个步骤:从随机样本生成假设,然后将其验证为数据。它不需要复杂的优化算法和大量的内存。这些优势来自随机抽样,这将在第2节中进行探讨。它适用于许多问题:模型拟合,对极几何估计,运动估计/分段,运动移动设备的结构以及基于特征的定位。
已经从RANSAC派生了许多方法,并形成了它们的家族。 关于它们有一些古老的调查和比较[19,29,31]。 还需要对RANSAC家族有深刻见解的观点。 可以根据研究目标对它们进行分类:准确,快速和强大(图2)。 代表性作品在第3节中进行了简要说明。在第4部分中,通过线拟合和平面单应性估计来评估其性能。在第5部分中,总结性论述和进一步的研究方向。
2 再探RANSAC
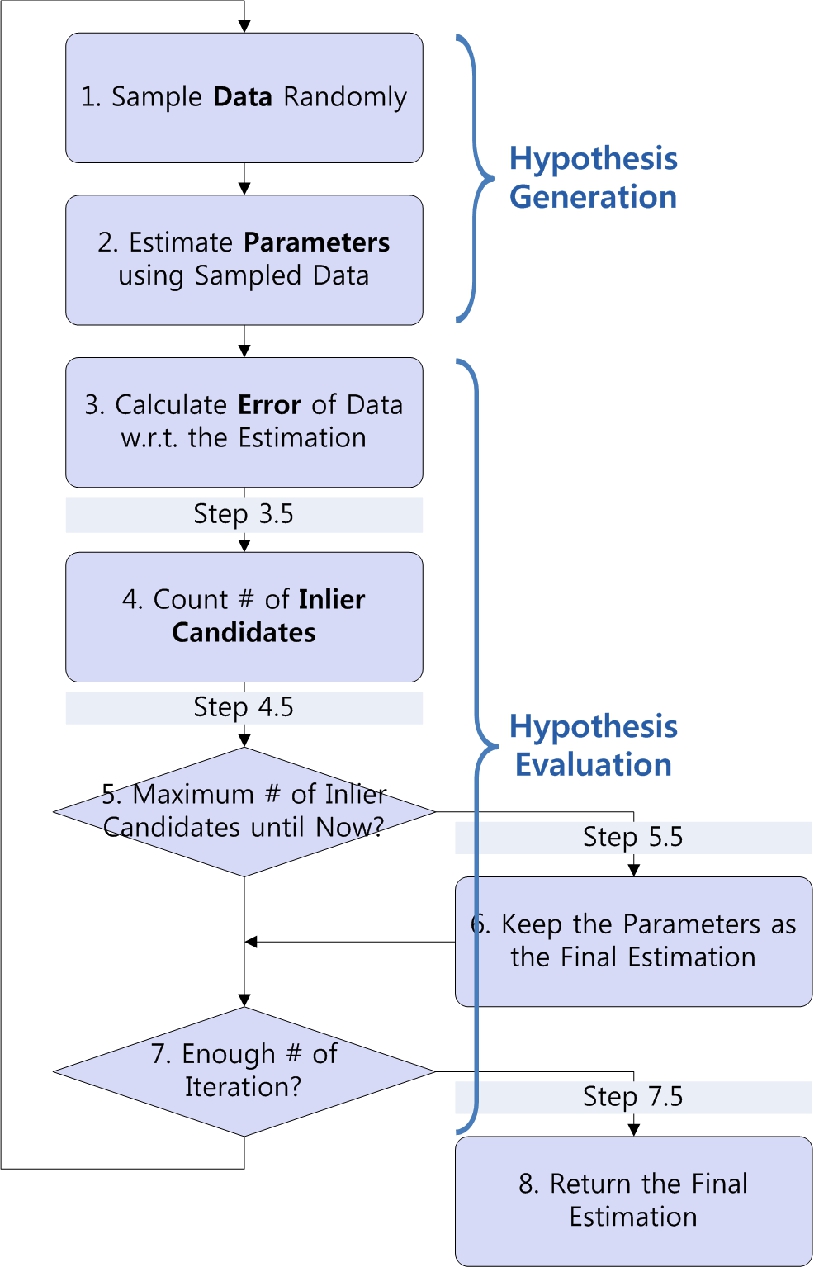
图1:RANSAC流程图
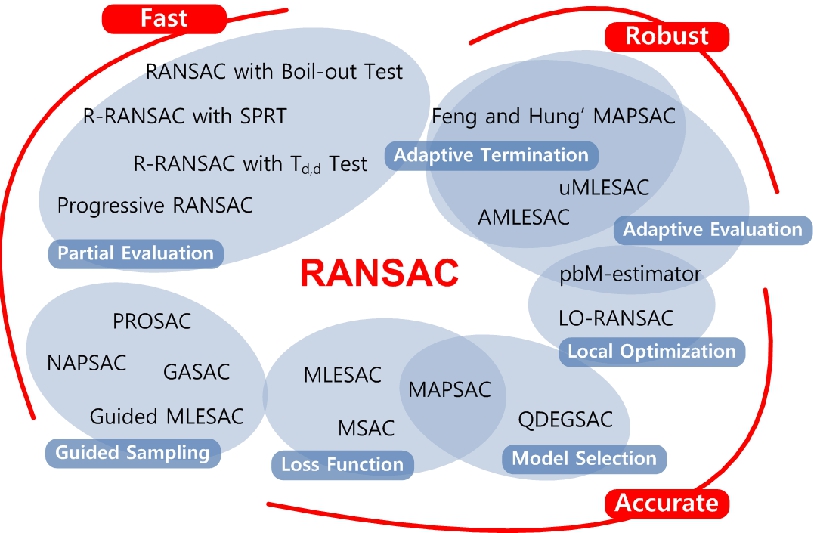
图2:RANSAC系列
RANSAC是一个包含两个阶段的迭代算法:假设生成和假设评估(图1)。
2.1假设产生
RANSAC随机采集数据的子集(步骤1),并从样本中估计参数(步骤2)。 如果给定模型是线,则ax + by + c = 0(a2 + b2 = 1),M = [a, b, c] T是要估计的参数,这是事实的假设。 RANSAC在其迭代过程中会生成许多假设。
RANSAC不是诸如最小二乘法和支持向量机之类的回归技术。 它使用它们来生成假设。 它包装并增强了它们,如果某些数据是异常值,则无法保持高精度。 RANSAC使用一部分数据,而不是全部数据。 如果选择的数据全部是内含物,则它们可能需要一个接近真相的假设。 该假设导致必要的迭代次数足以以失败概率α至少一次拾取所有内部样本,如下所示:
其中,m是生成假设的数据数量,γ是拾取一个常值的概率,即,常值与整个数据的比率(简称为常值比率)。 然而,在许多实际情况下,未知数比γ是未知的,这需要用户确定。
RANSAC将连续域中的估计问题转换为离散域中的选择问题。 例如,找到一条线有200个点,最小二乘法使用2个点。 有200C2 = 19, 900个可用对。 现在的问题是要在大量对中选择最合适的对。
2.2 假设评估
RANSAC最终选择最可能的假设,并由最靠后的候选者支持(步骤5和6)。数据被认为是内部候选项,其假设假设的误差在预定阈值之内(步骤4)。在进行线拟合的情况下,误差可能是从基准到估算线的几何距离。阈值是第二个调整变量,它与污染幅值的噪声幅度(不久即噪声幅度)高度相关。但是,在几乎所有应用中,噪声的大小也是未知的。
RANSAC将选择问题作为优化问题解决。公式为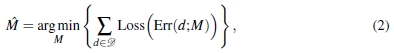
其中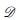 是数据,Loss是损失函数,而Err是误差函数,例如几何距离。 最小二乘法的损失函数表示为Loss(e)= e2。 相反,RANSAC使用
是数据,Loss是损失函数,而Err是误差函数,例如几何距离。 最小二乘法的损失函数表示为Loss(e)= e2。 相反,RANSAC使用
其中c是阈值。图3显示了两种损失函数的差异。 RANSAC在较大误差下具有恒定损耗,而最小二乘法则具有巨大损耗。离群值干扰最小二乘法,因为它们通常具有较大的误差。
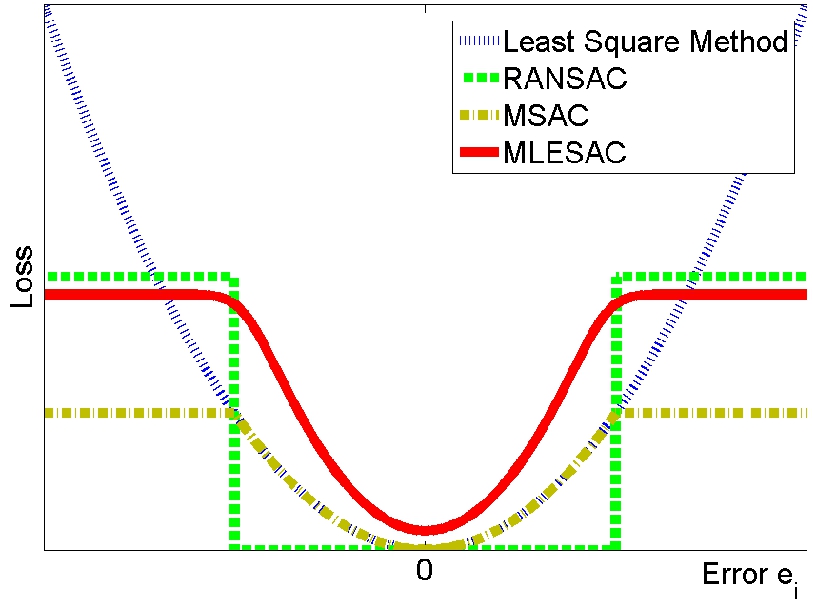
图3:损失函数
3 RANSAC的后裔
3.1要准确
损失函数损失函数用于评估假设(第4步),该假设选择最可能的假设。 MSAC(M估计器SAC)[30]采用RANSAC的有界损失如下: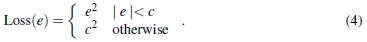
MLESAC(最大似然SAC)[30]利用内部和外部的错误概率分布来评估假设。 它将内部误差建模为无偏高斯分布,将外部误差建模为均匀分布,如下所示: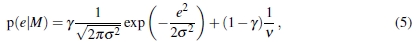
其中v是可用错误空间的大小。 γ为先验概率,即为(1)中的比率。 σ是高斯噪声的标准偏差,它是噪声幅度的常用度量。 MLESAC选择假设,该假设将给定数据的可能性最大化。 它使用负对数可能性进行计算可行性,因此损失函数变为
图3显示了RANSAC,MSAC和MLESAC的典型损失函数,它们非常相似。 RANSAC不在边界阈值内考虑误差量,因此其准确性比其他两种方法差。 MAPSAC(最大后验估计SAC)[28]与MLESAC相比采用了贝叶斯方法,但是其损失函数与MSAC和MLESAC相似,因为它假定先验统一。 与参数误差模型(5)相比,pbM-estimator(基于投影的Mestimator)[25]尝试了非参数方法。
本地优化:本地优化可以在步骤5.5或7.5附加本地优化以提高准确性。 LO-RANSAC(本地优化RANSAC)[8]在步骤5.5中添加了本地优化。 Chum报告说,在提出的优化方案中,带有迭代的内部RANSAC是最准确的。 他还证明,与没有RANSAC的情况相比,计算负担增加了logN倍,其中N是数据数。 pbM-estimator在步骤5.5中采用了复杂但功能强大的优化方案。 要使用pbM-estimator,应将给定的问题转换为EIV(变量误差)形式,如下所示: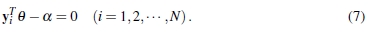
在进行线拟合的情况下,yi为[xi,yi] T,θ为[a,b] T,而α为-c。 给定的问题变为优化问题,如下所示:
其中κ是M核函数,而s是带宽。 有两种方法可以找到θ和α:θ的共轭梯度下降和α的均值漂移。 尽管初始估计略有错误,但优化方案仍可以准确找到θ和α。
模型选择:模型选择可以与RANSAC结合使用,即使对于给定模型的数据已退化,也可以进行合理的估计。 Torr提出了GRIC(几何鲁棒信息准则)[28]作为模型的适应性度量。 它考虑了模型和结构的复杂性。 GRIC的准确性高于AIC,BIC和MDL,后者的实验已与MAPSAC合并。 QDEGSAC(用于准简并数据的RANSAC)[12]在步骤8之后具有模型选择步骤。对于需要比给定模型更少参数的模型,模型选择步骤具有另一个RANSAC。 它不需要特定领域的知识,但是它使用内部候选者的数量来检查退化。
3.2要快
RANSAC的计算时间为
其中TG是从采样数据生成假设的时间,TE是评估每个数据的假设的时间。
引导采样:引导采样可以替代随机采样(第1步)以加快RANSAC的速度。与随机采样相比,引导减少了(9)中的必要迭代次数t。但是,由于额外的计算负担,它可能使RANSAC变得更慢,并且可能削弱全局搜索的潜力。引导的MLESAC [27]使用可用的提示来分配(5)中每个数据的先验概率。暂时的匹配分数可以用作估计平面单应性的线索。PROSAC(Progressive SAC)[6]更深入地利用了先验知识。它使用先验知识(例如匹配分数)对数据进行排序。在排名靠前的数据而不是整个数据中生成一个假设。PROSAC会逐步尝试排序较少的数据,极端情况是整个数据。与引导式MLESAC和PROSAC相比,NAPSAC(N个相邻点SAC)[20]和GASAC(遗传算法SAC [23])不使用先验信息。NAPSAC使用启发式方法,即离群值比离群值更趋向于其他离群值。它从随机选择的点在定义的半径内采样数据。GASAC基于遗传算法,其过程与RANSAC完全不同(图1)。它将数据子集作为基因进行管理,从而可以产生假设。每个基因因其产生的假设的丧失而受到惩罚。惩罚导致从当前基因进化出新基因库的机会减少。
部分评估:如果假设显然与事实相去甚远,则可以放弃评估假设,这会减少计算时间。部分评估会减少评估所需的数据数量,即(9)中的N。R-RANSAC(随机化RANSAC)[5]在步骤3.5进行初步测试Td,d 测试。仅当生成的假设通过初步检验时才执行全面评估。如果随机选择的d数据中的所有d数据均与假设一致,则通过Td,d检验。另一个R-RANSAC [18]使用SPRT(顺序概率比测试),代替了步骤4和5。当似然比低于最佳阈值时,SPRT终止,其迭代解在[18]中得出。救援测试[3]同样也替代了步骤4和5。抢占式RANSAC [21]执行并行评估,而RANSAC进行串行评估。在评估阶段之前,它会生成足够数量的假设,并在每个数据处一起评估所有假设。对于时间限制有限的应用程序很有用。
3.3要坚固
RANSAC需要针对给定数据调整两个变量:用于评估假设的阈值c和用于生成足够假设的迭代次数t。
自适应评估:需要自动调整阈值c,以在变化的数据中保持高精度。 LMedS不需要任何调整变量,因为它试图使中位数平方误差最小。 但是,由于中位数来自离群值,因此,当离群值比率低于0.5时,情况会变得更糟。 MLESAC及其后代基于参数概率分布(5),需要s和g来评估假设。 冯和洪’
MAPSAC [10](不是原始的MAPSAC [28])和uMLESAC [4]在步骤3.5中通过EM(期望最大化)进行计算。AMLESAC [16]对σ使用均匀搜索和梯度下降,对γ使用EM。 pbM估计器的优化步骤也需要带宽s(8)。 它确定为N-0.2 * MAD,其中MAD是中位数绝对偏差。
自适应终端:迭代次数t表示生成的假设的数量,这些假设的自动分配可以在变化的数据中实现高精度和较少的计算时间。 Feng和Hung的MAPSAC在步骤5.5中通过1更新了迭代次数,其中γ来自EM。 但是,它可能终止得太早,因为错误的假设有时会导致γ大且σ大(请参见图4(a)和4(d)的歧义)。 uMLESAC通过γ和σ一起更新数字,如下所示:
其中erf是高斯误差函数,用于计算高斯cdf的值。 变量k在物理上是指采样数据属于误差置信度β的概率。 uMLESAC使用α和β控制精度和计算时间之间的折衷。 具有SPRT的RRANSAC的折现系数也与k相似,这是拒绝SPRT中的良好假设的概率。
图4:线拟合数据示例
4实验
4.1线拟合:综合数据
4.1.1配置
解决了线路拟合问题,以评估RANSAC系列的性能。 产生了200点。 内点来自真实线,即0.8x + 0.6y-1.0 = 0,且没有高斯噪声。 离群值均匀分布在给定区域中(图4)。 实验对各种组的固有比率γ*和噪声大小σ*(图4)进行了实验。 每种配置重复1000次以获得统计学上的代表性结果。 使用使用3点的最小二乘法估计一条直线,并将几何距离用作误差函数。 在12个鲁棒估计量上进行了实验。 除了RANSAC *和MLESAC *(仅在(γ*,σ*)=(0.7,0.25)时进行调整以比较鲁棒性而不进行调整之外,每个估计器都在每种配置下进行调整。 每个估算器的性能都通过准确性和计算时间来衡量。 准确度是通过归一化的平方误差(NSE)来量化的,
其中M* 和M是真实线及其估计,in是一组inliers。 NSE来自Choi和Kim的问题定义[4]。 当估计线的误差幅度接近真值的误差幅度时,NSE接近1。 使用Intel Core 2 CPU 2.13GHz上的MATLAB时钟功能测量了计算时间。 可以通过在不同配置下改变精度来观察鲁棒性。
4.1.2结果与讨论
图5和图6显示了基于变化的inlier比率和噪声幅度的准确性和计算时间。

图5:改变γ*和σ*的精度(NSE)

图6:在不同的γ*和σ*上进行计算
在准确性方面:在几乎所有配置中,MLESAC的精度都比RANSAC高出5%。 MLESAC考虑了误差的大小,而RANSAC则不管大小如何都具有恒定的损耗。 它可以对假设进行更好的评估,但是比RANSAC慢15%。 由于局部优化,LO-RANSAC的精度比RANSAC高约10%。 与RANSAC相比,它的计算负担增加了约5%。 同样,GASAC和pbM估计器的准确度分别比RANSAC高出14%和7%,但慢了6%和16倍。
关于计算时间:带有Tdd测试的R-RANSAC的精度与RANSAC相似,但是尽管迭代次数较多,但速度稍快。 由于它在评估步骤中使用了一部分数据,因此可以减少时间。 带有SPRT的R-RANSAC比RANSAC更为准确,但是由于其自适应终止,它没有减少计算时间。 它的自适应方案决定了其端接比调整后的RANSAC更长(图7(c))。
在健壮性:MLESAC,Feng和Hung的MAPSAC,AMLESAC,u-MLESAC基于误差模型,该模型是高斯分布和均匀分布的混合。图7(a)和7(b)显示了误差模型的估计变量g和s,图7显示了迭代次数。 Feng和Hung的MAPSAC,AMLESAC和u-MLESAC估计误差模型大约是低误码率。因此,它们在接近0.3的内部比率时具有较低的精度,但是在较低的内部比率下,它们比以0.7的内部比率进行调整的RANSAC *和MLESAC *更准确。 LMedS和GASAC在0.5线规比率下变得不太准确。它是由它们的损失函数(平方误差的中位数)产生的,当异常值超过一半时,误差函数将由异常值选择平方误差。特别是,Feng 和 Hung的MAPSAC和u-MLESAC由于自适应匹配,在以0.7的固有比率进行转换后比RANSAC *和MLESAC *快得多。由于错误模型的估计不正确,它们在0.3线性比率处的迭代次数与使用1调整的迭代次数显着不同。带有SPRT的R-RANSAC高估了几乎所有配置中的迭代次数。
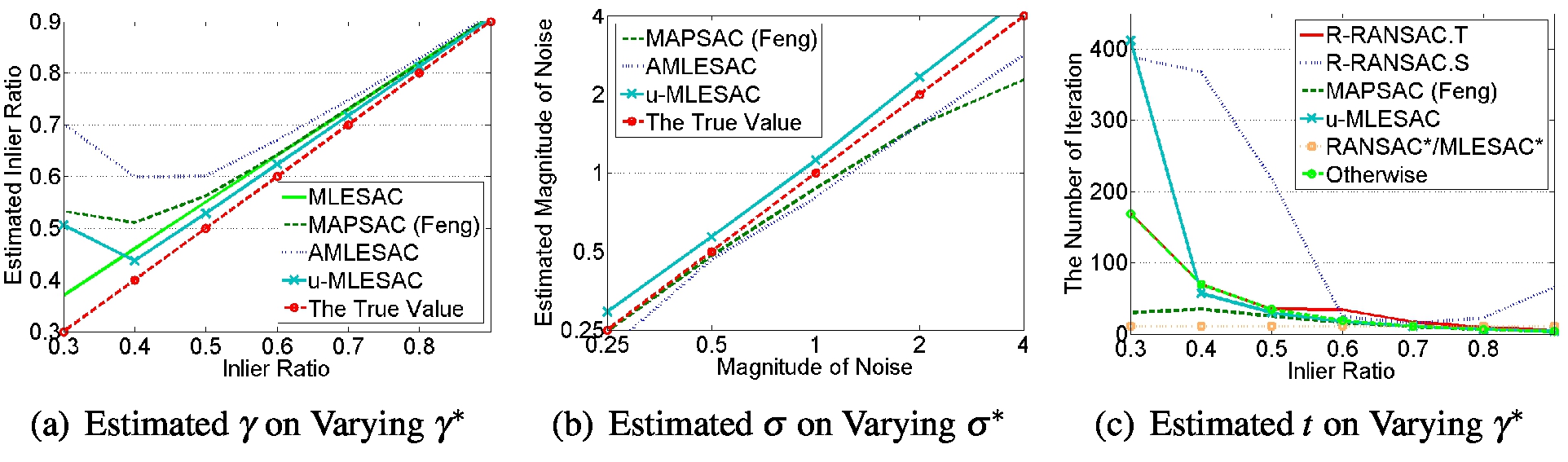
图7:不同配置的结果
4.2 2D单应估计:真实数据
4.2.1配置
平面单应性估计还用于评估估计器的性能。 牛津VGG涂鸦图像集(图8)用于实验。 SIFT [17]被用来产生试探性的对应点。 四点算法[13]使用四组匹配点估计平面单应性。 精度和时间测量与线路拟合实验相同。 误差函数Err是点与其匹配点的投影之间的欧几里得距离。 通过真实单应性在暂定匹配中识别出内含子,该单应性与Graffiti图像集合并。 由于很难将单应性约束转换为EIV问题形式,因此pbM估计器并未用于实验。对每个图像对进行100次实验,以获得具有统计意义的结果。

图8:牛津VGG涂鸦图像[2]
4.2.2结果与讨论
图9显示了三个图像对的准确性和计算时间,分别为图像1至图像2(1640对点),图像1至图像3(888对点)和图像1至图像4(426对点)。 图9中的破折号(-)表示其NSE大于50,即平均失败。在估计从图像1到图像3的单应性时,对RANSAC *和MLESAC *进行了调整。

图9:三个图像对的准确性(NSE)和计算时间
RANSAC,MSAC和MLESAC的准确性相差近4%。在三个估计量中,MSAC最准确,而MLESAC最差。LORANSAC中的局部优化将精度提高了近20%,而计算负担却只有7%。GASAC还显着提高了准确性,但其计算时间是RANSAC的5倍。
与RANSAC相比,子集评估通过Td,d测试将R-RANSAC加速了约6倍,而RANSAC也保持了类似的准确性。它比生产线拟合实验有显着改善。带有SPRT的R-RANSAC在估计从图像1到图像2的单应性方面也具有类似的性能。但是,它在其他两个实验中均失败了,这与在线拟合实验中的0.3线性比率相似。
Feng 和 Hung的MAPSAC的性能与线路拟合实验相似。其准确性与RANSAC相似,但在严重情况下会失败,例如从图1到图4的单应性。尽管u-MLESAC在这种情况下没有失败,但是它也使更严重的图像对失败,这使RANSAC可以正确估计单应性。与RANSAC *和MLESAC *相比,他们从图1到图2的单应花费的时间更少。LMedS和GASAC无法估计从图1到图4的单应性,因为其内在比率小于0.5。
5结论
RANSAC及其后代从三个角度进行了概述:准确性,计算时间和鲁棒性。本文还描述了完全不同的方法具有相同的想法。例如,R-RANSAC和抢先式RANSAC通过部分评估来加速RANSAC。这种见解对于分析以前的工作和开发新方法很有用。还从三个角度分析了两个实验的结果。结果表明了准确性/鲁棒性和计算时间之间的权衡。例如,uMLESAC在变化的数据中保持高精度,但是由于其自适应性,它需要的时间是RANSAC的1.5倍。
在RANSAC家族中已经进行了有意义的研究,但是还需要进一步研究。通过合并先前的工作或新的突破,可以实现平衡的准确性/鲁棒性和计算时间。适应各种数据是一个具有挑战性的问题,因为先前的工作无法以较低的误群率保持准确性。 MLESAC是从概率角度重新定义原始RANSAC的第一个突破。对问题的新解释可以带来另一个突破。该问题可以与其他问题(例如模型选择)结合在一起。对于当前的单个结果公式而言,具有多个模型的数据是一个有吸引力的问题。新工具可以刺激这一领域,例如GASAC的遗传算法。包括近期工作[7、14、26]在内的调查和性能评估有助于用户选择适合其应用的方法。 Middlebury计算机视觉页面[1]是一个很好的例子。
致谢
作者要感谢牛津VGG的涂鸦图片。 这项工作得到了韩国知识经济部(MKE)和韩国工业技术评估研究所(KEIT)的R&D计划的部分支持。 (2008-S-031-01,为无处不在的城市开发混合式u机器人服务系统技术)
参考文献
[1] Middlebury计算机视觉页面。网址http://vision.middlebury.edu/。
[2]牛津视觉几何组亲属协变区域数据集。网址http:// www.robots.ox.ac.uk/~vgg/data/data-aff.html。
[3] David Capel. An effective bail-out test for RANSAC consensus scoring. In Proceedings of the British Machine Vision Conference (BMVC), September 2005.
[4] Sunglok Choi and Jong-Hwan Kim. Robust regression to varying data distribution and its application to landmark-based localization. In Proceedings of the IEEE Conference on Systems, Man, and Cybernetics, October 2008.
[5] O. Chum and J Matas. Randomized RANSAC with Td;d test. In Preceedings of the 13th British Machine Vision Conference (BMVC), pages 448–457, 2002.
[6] Ondrej Chum and Jiri Matas. Matching with PROSAC - Progressive Sample Consensus. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2005.
[7] Ondrej Chum and Jiri Matas. Optimal randomized ransac. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30(8):1472–1482, August 2008.
[8] Ondrej Chum, Jiri Matas, and Stepan Obdrzalek. Enhancing RANSAC by generalized model optimization. In Proceedings of the Asian Conference on Computer Vision (ACCV), 2004.
[9] R. O. Duda and P. E. Hart. Use of the Hough transformation to detect lines and curves in pictures. Communications of the ACM, 15:11–15, January 1972.
[10] C.L. Feng and Y.S. Hung. A robust method for estimating the fundamental matrix. In Proceedings of the 7th Digital Image Computing: Techniques and Applications, number 633–642, December 2003.
[11] M. A. Fischler and R. C. Bolles. Random Sample Consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM, 24(6):381–395, June 1981.
[12] Jan-Micheal Frahm and Marc Pollefeys. RANSAC for (quasi-)degenerate data (QDEGSAC). In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2006.
[13] Richard Hartley and Andrew Zisserman. Multiple View Geometry in Computer Vision. Combridge, 2 edition, 2003.
[14] Richard J. M. Den Hollander and Alan Hanjalic. A combined ransac-hough transform algorithm for fundamental matrix estimation. In Proceedings of the British Machine Vision Conference (BMVC), 2007.
[15] P. J. Huber. Robust Statistics. John Wiley and Sons, 1981.
[16] Anton Konouchine, Victor Gaganov, and Vladimir Veznevets. AMLESAC: A new maximum likelihood robust estimator. In Proceedings of the International Conference on Computer Graphics and Vision (GrapiCon), 2005.
[17] David G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2):91–110, 2004.
[18] J. Matas and O. Chum. Randomized RANSAC with sequential probability ratio test. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV), 2005.
[19] Peter Meer, Doran Mintz, Azriel Rosenfeld, and Dong Yoon Kim. Robust regression methods for computer vision: A review. International Journal of Computer Vision, 6 (1):59–70, 1991.
[20] D.R. Myatt, P.H.S Torr, S.J. Nasuto, J.M. Bishop, and R. Craddock. NAPSAC: High noise, high dimensional robust estimation - it’s in the bag. In Preceedings of the 13th British Machine Vision Conference (BMVC), pages 458-467, 2002.
[21] David Nister. Preemptive RANSAC for live structure and motion estimation. In Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV), pages 199–206, 2003.
[22] Rahul Raguram, Jan-Michael Frahm, and Marc Pollefeys. A comparative analysis of ransac techniques leading to adaptive real-time random sample consensus. In Proceedings of the European Conference on Computer Vision (ECCV), 2008.
[23] Volker Rodehorst and Olaf Hellwich. Genetic Algorithm SAmple Consensus (GASAC)- a parallel strategy for robust parameter estimation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2006.
[24] P.J. Rousseeuw. Least median of squares regression. Journal of the American Statistical Association, 79(388):871–880, 1984.
[25] R. Subbarao and P. Meer. Subspace estimation using projection-based M-estimator over grassmann manifolds. In Proceedings of the 9th European Conference on Computer Vision (ECCV), pages 301–312, May 2006.
[26] Raghav Subbarao and Peter Meer. Beyond RANSAC: User independent robust regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshop (CVPRW), 2006.
[27] Ben J. Tordoff and David W. Murray. Guided-mlesac: Faster image transform estimation by using matching priors. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(10):1523–1535, October 2005.
[28] P.H.S. Torr. Bayesian model estimation and selection for epipolar geometry and generic manifold fitting. International Journal of Computer Vision, 50(1):35–61, 2002.
[29] P.H.S Torr and D.W. Murray. The development and comparison of robust methods for estimating the fundamental matrix. International Journal of Computer Vision, 24(3): 271–300, 1997.
[30] P.H.S. Torr and A. Zisserman. MLESAC: A new robust estimator with application to
estimating image geometry. Computer Vision and Image Understanding, 78:138–156, 2000.
[31] Zhengyou Zhang. Parameter estimation technique: A tutorial with application to conic fitting. Image and Vision Computing, 15(1):59–76, 1997.