此为计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面。
1. Active Appearance Models
活动表观模型和活动轮廓模型基本思想来源 Snake,现在在人脸三维建模方 面得到了很成功的应用,这里列出了三篇最早最经典的文章。对这个领域有兴趣 的可以从这三篇文章开始入手。
[1998 ECCV] Active Appearance Models
[2001 PAMI] Active Appearance Models
2. Active Shape Models
[1995 CVIU]Active Shape Models-Their Training and Application
翻译
主动外观模型
摘要 -我们证明使用主动外观模型(AAM)解释图像的新方法。AAM中包含感兴趣对象的形状和灰度外观可推广到几乎任何有效的实施例的统计模型。在训练阶段,我们学习模型参数位移和训练图像和合成典范之间引起的剩余误差之间的关系。以匹配我们衡量当前残差和使用模型来预测从而更好地适应改变当前参数的图像。一个好的全面的比赛中甚至来自贫困起点估计几次迭代获得。我们详细描述了该技术,并给出定量的性能测试结果。我们预计,AAM算法将是在许多应用中定位可变形物体的一种重要方法。
1 介绍
基于模型的方法来可变对象的图像的解释,现在吸引相当大的兴趣[6] [8] [10] [11] [14] [16] [19] [20]。他们可以通过约束的解决方案是一个模型的有效实例实现稳定的结果。另外一组模型参数方面,以“解释”的图像的能力提供了现场演绎自然基础。为了实现这些好处,对象外观模型应该尽可能能够合成一个非常近似于目标对象的任何图像完全一样。
虽然基于模型的方法已经证明是成功的,几个现有的方法中使用的是直接通过最小化演绎下,一个由模型合成的图像之间的差异完全一致,照片般逼真的模型。 尽管存在适合逼真的模型(例如Edwards等[8]面),他们通常是为了应对在目标对象的变化涉及到大量的参数(50-100)。使用以上这样的高维空间的标准方法直接优化是可能的,但慢于[12]。
在本文中,我们展示了一个直接的优化方法导致的算法是快速,准确,稳健。在我们提出的方法,我们不尝试每次我们希望将模型拟合到一个新的图像时,解决了一般优化。相反,我们利用以下事实:优化问题是类似的每个我们可以学习这些相似的离线时间。这使得我们即使搜索空间具有非常高维度找到快速收敛的方向。这种方法类似于Sclaroff和 Isidoro [18],但使用的统计,而不是“物理”模型。
在本文中,我们将讨论合成图像解释的想法和以前的描述相关工作。在第2节中,我们说明我们如何建立对象的外观紧凑模型,其能够产生类似于在训练集合成的例子。该方法可在各种各样的应用中使用,但作为一个例子,我们将集中于解释面部图像。在第3节我们描述了主动外观模型算法的细节和在第4节中展示它的性能。
1.1 阐释合成
近年来为可变形物体的图像的解释许多基于模型的方法进行了说明。一个动机是通过使用模型来约束的解决方案是仿照对象的有效实例,实现强劲性能。模型也提供了通过在一个紧凑的组模型参数的术语“说明”的给定图像的外观为广泛的应用的基础。这些参数对于场景的更高水平的解释是有用的。例如,在分析它们可以被用于表征身份的人脸图像的情况下,姿态或面部的表达。为了解释新的图像时,需要寻找图像和模型之间的最佳匹配的有效方法。
各种方法建模的变化进行了描述。最常见的一般方法是允许一个原型根据一些物理模型而有所不同。 Bajsy和Kovacic [1]描述了一种体积模型(大脑的),其也弹性变形以产生新的例子。 Christensen等人[3]描述了变形的粘性流模型它们也适用于大脑,但计算量非常大。 Turk 和 Pentland [20]使用主成分分析来描述一组基函数,或“特征脸”的角度的人脸图像。虽然变化的有效模式是从训练组学习型,而更可能是比“物理”模型更合适,特征脸不稳健,塑造的变化,并不会与姿势和表情的变化处理好。然而,该模型可容易地使用基于相关的方法来匹配到的图像。
Poggio及其同事[10] [12]合成从一组示例视图的对象的新的视图。他们通过随机优化过程。这是缓慢的拟合模型,以看不见的看法,但可能由于合成图像的质量是稳健的。 Cootes等[5]描述了灰度级表面的3D模型,允许的形状和外观的全合成。然而,他们没有提出一个合理的搜索算法来匹配模型以全新的形象。Nastar等人[16]描述了三维灰度级表面的相关模式,结合变化的物理和统计模式。虽然他们描述的搜索算法,它需要一个很好的初始化。 Lades等人[13]模型的形状和使用Gabor特征向量一些灰度级信息。然而,他们不征收强形状的约束,不能轻易合成一个新的实例。
Cootes等人[6]模型形状和本地灰度外观,使用主动形状模型(ASMs)来定位在新的图像柔性物体。 Lanitis 等人[14]使用这种方法来解释面部图像。在发现使用ASM形状,面翘曲成归一化的帧,其中,所述自由形状面的强度的一个模型被用于解释图像。Edwards等人[8]扩展这项工作,以产生形状和灰度外观的组合模式,但再次依靠ASM定位在新的图像面。我们的新方法可以被看作是这一理念的进一步延伸,使用合并外观模型的所有信息,以适合图像。
在开发我们的新方法,我们通过前两次的论文提供的见解中受益。 Covell [7]表明,本征特性模型的参数可以被用于驱动形状模型点到正确的位置。这里描述的AAM这种想法的延伸。 Black 和Yacoob [2]使用本地的手工制作的模型图像流的跟踪面部特征,但不要试图全脸建模。AAM可以被认为是由于这一概括,其中对应于在每个模型参数变化的图像差异的图案被学习和用于修改的模型估计值。
在并行开发Sclaroff和 Isidoro 已经证明“有效斑点”来跟踪[18]。该方法是在它们使用图像的差异来驱动跟踪,学习在离线处理阶段偏移图像误差和参数之间的关系大体相似。主要的区别是,有源斑点从单个例如衍生,而主动外观模型使用的示例的训练集。前者使用单个例如作为原始模型模板,允许变形以低能量网格变形(使用有限元法得到的)相一致。一个简单多项式模型被用来允许在所述物体中的强度变化。AAMs学到什么是从他们的训练组有效的形状和强度的变化。
Sclaroff和Isidoro 建议采用一个强大的内核应用于图像的差异,我们将在以后的工作中使用的想法。另外,由于注释训练集是耗时构建AAM的一部分的时间最多,活动斑点的方法可以是用于从第一个例子“自举”是有用的。
2 外观造型
在这一节中,我们概述了如何生成我们的外观模型。该方法如下,在Edwards等人[8]所描述,而是包括额外正常化和加权的基本方法是需要了解新主动外观模型算法步骤的某些了解。
由形状变化的模型相结合,在一个形状归一化帧的外观变化的模型中生成的模型。我们需要标记的图像,其中重要的里程碑意义的点标记每个例子中的物体上的训练集。例如,建立一个脸部模型中,我们需要在关键位置标明点勾勒出的主要特点(图1)的人脸图像。

图1的面部图像的实施例标有122个标志点
鉴于这样的一组,我们可以产生形状变化的统计模型(见[6]的信息。一个单一的对象上的标记的点描述该对象的形状。我们对齐所有集到一个共同的坐标帧,并代表各通过一个矢量x我们然后应用主成分分析(PCA)对数据的任何示例然后,可以使用近似:

其中, 是均值形状。Ps为一组变异正交模式的和bs是一组的形状参数。
是均值形状。Ps为一组变异正交模式的和bs是一组的形状参数。
为了构建灰度外观我们翘曲各实施例图像的统计模型,使得它的控制点的平均形状匹配(使用三角测量算法)。然后,我们从采样在由平均形状所覆盖的区域中的形状归一化图像 的灰度级信息。为了尽量减少全局照明变化的影响,我们通过应用缩放
的灰度级信息。为了尽量减少全局照明变化的影响,我们通过应用缩放 和偏置
和偏置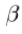 归一化的例子的样本。
归一化的例子的样本。

的和的值被选择到矢量最佳匹配的归一化平均值。设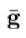 为归一化的数据,缩放和偏移的平均值,使得元素的总和是零和元素的方差是统一。 和的正常化所需的值然后由下式给出
为归一化的数据,缩放和偏移的平均值,使得元素的总和是零和元素的方差是统一。 和的正常化所需的值然后由下式给出

其中n是在矢量元素的数量。
当然,获得所述归一化的数据的平均值是接着一个递归的过程,作为归一化是在是指稳定的溶液可以发现来定义通过使用实施例为平均值的第一估计之一,对准他人它(使用2和3重新估计的均值和迭代。
通过应用PCA,以标准化的数据我们得到了一个线性模型:

其中是平均归一化灰度级矢量。Pg为一组变异正交模式的和bg是一组灰度级的参数。
形状和任何一例的外观因此可以通过矢量bs和bg进行总结。由于可能存在的形状和灰度级的变化之间的相关性,我们应用一个进一步PCA到如下所述的数据。对于每一个例子中,我们生成所串接的矢量

其中Ws为权重为每个形状参数的对角矩阵,从而允许在形状和灰度模型(见下文)之间的单位的差。我们应用PCA在这些向量,从而进一步模型

其中Q是特征向量,c是外观参数同时控制形状和模型的灰度等级的载体。由于形状和灰色模型参数具有零个均值C也会做。

请注意,该模型的线性性质允许我们直接表达的形状和灰度级为c的功能
一个示例图像能够用于通过生成从所述矢量g的自由形状的灰度级图像,并使用通过X中描述的控制点翘曲它一个给定的C来合成。
2.1形状参数权重的选择
bs的元素具有距离的单位,这些bg的具有强度的单位,所以它们不能被直接比较。因为Pg具有正交列,由一个单元改变bg由一个单元移动克。为了使bs和bg相称,我们必须估计不同的bs对样品g效果。要做到这一点,我们系统地给出的位移形状置换bs的每个元素从每个训练样例其最佳值,和采样图像。在g的RMS变化每单位变化的形状参数bs给出重量Ws在等式(5)被应用到该参数。
2.2实施例:面部外观型号
我们使用上述构建面部外观的模型的方法。我们使用了训练设定面400幅的图像,每一个标有围绕主特征点122(图1)。由此我们产生具有23个参数,具有114个参数的自由形状灰色模型,并用80只解释观察到的变化的98%所需的参数组合的外观模型的形状模型。该模型使用约10,000像素值来弥补面部的补丁。
图2和图3示出了通过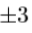 个标准偏差变化前两个形状和灰度级模型参数的影响,如从训练集来确定。第一个参数对应于协方差矩阵的最大特征值,这给它的整个训练集变化。图4示出不同的前四个外观模型参数,表示身份变化的影响,姿势和表情。
个标准偏差变化前两个形状和灰度级模型参数的影响,如从训练集来确定。第一个参数对应于协方差矩阵的最大特征值,这给它的整个训练集变化。图4示出不同的前四个外观模型参数,表示身份变化的影响,姿势和表情。

图2:形状变化的前两种模式 图三:灰度级变化的前两种模式

图4:外观变化的前四种模式
2.3逼近一个新实施例
给定一个新的形象,标有一组地标,我们可以生成与模型近似。我们按照上一节中的步骤以获得b,组合匹配例子的形状和灰度级的参数。由于Q是正交的,所述组合外观模型参数,c由下式给出

完整重建然后通过施加公式(7)中,反转的灰度级正规化给出的,施加适当的姿势的点和突出灰度矢量到图像中。
例如,图5示出了沿着面补丁(叠加在原始图像上)的模型重建一个以前看不见的图像。

图5:一个以前看不见的面部图像(左)的合并的模型表示(右)的实施例子
3 主动外观模型搜索
我们现在讨论的中心问题:我们已经哈,上面还有一个合理的起始近似描述的图像来解释,一个完整的外观模型。我们提出的方案用于有效地调整所述模型参数,从而产生合成的例子,其中新图像作为紧密匹配越好。我们首先概述的基本思想,给人算法的细节之前。
3.1概述AAM搜索
我们希望把解释为最优化问题中,我们尽量减少新的图像,并通过一个外观模型合成之间的差异。差矢量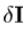 可以被定义:
可以被定义:

其中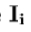 是灰度等级值的图像中的矢量,和
是灰度等级值的图像中的矢量,和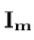 ,是灰度值的当前模型参数的向量。
,是灰度值的当前模型参数的向量。
要找到模型和图像之间的最佳匹配,我们希望通过改变模型参数,c,尽量减小差异向量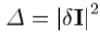 的幅度。由于外观模型可以有很多的参数,这似乎首先是一个艰难的啮合高维优化问题。我们注意到,但是,每次尝试匹配模型以全新的形象其实是一个类似的优化问题。我们建议学习一些关于如何解决这类问题提前。通过提供如何图像搜索时期间调整模型参数的先验知识,我们到达了一个高效的运行时间的算法。特别是,在我的空间格局
的幅度。由于外观模型可以有很多的参数,这似乎首先是一个艰难的啮合高维优化问题。我们注意到,但是,每次尝试匹配模型以全新的形象其实是一个类似的优化问题。我们建议学习一些关于如何解决这类问题提前。通过提供如何图像搜索时期间调整模型参数的先验知识,我们到达了一个高效的运行时间的算法。特别是,在我的空间格局 ,对关于如何对模型参数应以实现更好地适应改变的信息。在采用这种方法有两个部分的问题:学习模型中的参数,和误差之间的关系,并在迭代算法利用
,对关于如何对模型参数应以实现更好地适应改变的信息。在采用这种方法有两个部分的问题:学习模型中的参数,和误差之间的关系,并在迭代算法利用 和这些知识为减少
和这些知识为减少 .
.
3.2学习到正确的模型参数
我们可以选择对和(这需要进行,因此校正)模型参数的误差之间的关系最简单的模型是线性的:

这原来是一个足够好的近似实现可接受的结果。为了找到A,我们已知的模型位移,的样品进行多次多元线性回归,以及相应的差分图像。我们可以通过扰乱了它们被称为图像的“真实”模型参数生成这些套随机位移。这些可以是原始训练图像或与外观模型生成的合成图像。在后一种情况下,我们知道确切的参数和图像不被噪声干扰。
除了在模型参数的扰动,我们还模拟在2D位置,大小和方向小位移。这些四个额外参数包括在回归;对于符号的简单起见,它们可以被看作将向量c的简单地作为额外的元素。为了保持线性,我们表示使用姿势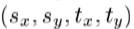 ,其中
,其中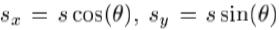 。为了获得声誉良好表现关系的是要仔细选择在其中计算出的图像的差的参考帧是很重要的。参考的最合适的帧是在部分2中描述的形状归一化的补丁。
。为了获得声誉良好表现关系的是要仔细选择在其中计算出的图像的差的参考帧是很重要的。参考的最合适的帧是在部分2中描述的形状归一化的补丁。
因此,我们计算差值:让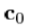 是当前图像与已知外观模型参数。我们通过已知的量,移位参数,以获得新的参数
是当前图像与已知外观模型参数。我们通过已知的量,移位参数,以获得新的参数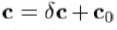 。对于这些参数我们生成的形状,x和标准化灰度级,gm,使用(7)。我们从图像样品,使用点中,x,以获得归一化的样品gs翘曲。样品误差为
。对于这些参数我们生成的形状,x和标准化灰度级,gm,使用(7)。我们从图像样品,使用点中,x,以获得归一化的样品gs翘曲。样品误差为 。
。
训练算法是然后简单地随机置换模型参数中的每个训练图像,记录和 。然后,我们进行多元回归获得的关系
。然后,我们进行多元回归获得的关系

训练期间要使用的值的最佳范围是由实验确定。理想情况下,我们力求model保存在尽可能大的范围内的误差作为尽可能的关系。然而,真正的关系被发现仅在值的有限范围内是线性的。我们对脸部模型实验表明,最佳扰动是为每个模型参数大约0.5标准偏差(在训练集),在尺度约10%和2个像素的翻译。
业绩面模型:我们应用上述算法,以在2.2节中描述的脸部模型。进行线性回归后,我们可以计算出一个 统计每个参数的扰动,
统计每个参数的扰动, 测量如何位移由误差矢量“预测”。为80个参数的平均值为0.82,最大为0.98(在第一参数)和最小的0.48。
测量如何位移由误差矢量“预测”。为80个参数的平均值为0.82,最大为0.98(在第一参数)和最小的0.48。
我们可以按如下可视化扰动的影响。如果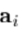 是回归矩阵A 的第 i 行,第 i 个参数的预测变化,是由下式给出
是回归矩阵A 的第 i 行,第 i 个参数的预测变化,是由下式给出

和给出估计位移时附接到取样贴片的不同的区域的重量。图6示出对应于姿态参数,的变化的权重。明亮的区域是正权,暗区为负。正如预期的那样,在x和y位移的权重类似于x和y衍生物图像。类似的结果为对应于所述外观模型参数的权重得到。

图6:对应于所述姿态参数的变化重量
扰动面模型:为了检查预测的性能,我们系统的位移在一组10个测试图像与真实位置的脸部模型,以及所使用的模型来预测给定的采样误差矢量的位移。图7和图8示出了针对实际的翻译的预测翻译。有在约4个像素的零良好的线性关系。虽然这打破了较大的位移,只要预测具有相同的符号为实际的错误,并且不会过高地预测太远,迭代更新方案应该收敛。在这种情况下高达x 20角像素的位移和在y中约10应该是可校正的。
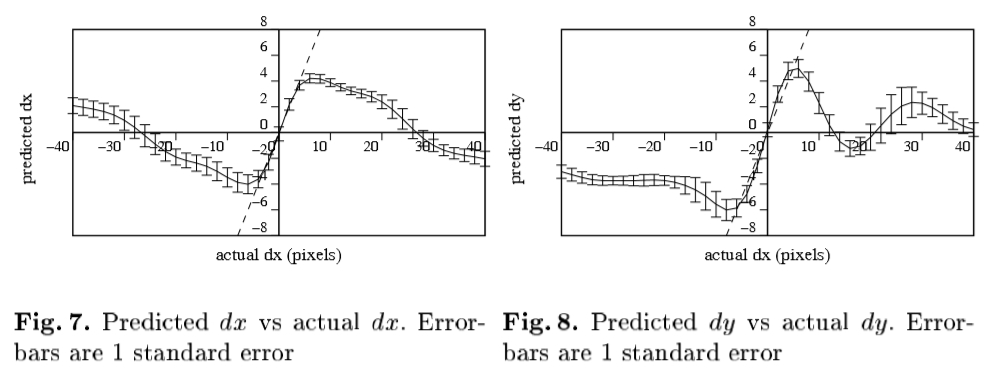
图7:预测DX和VS实际DX比较。 Errorbars是1个标准误差 图8:预测DY和VS实际DY比较。 Errorbars是1个标准误差
我们可以,但是,通过建立对象外观的多分辨率模式扩展这个范围。我们会为我们的每一个训练图像的高斯金字塔,并为金字塔的每一级的外观模型。图9显示在三个决议X流离失所模型的预测。 L0是基本模式,与约10000像素。 L1有大约2500个像素和L2大约600像素。
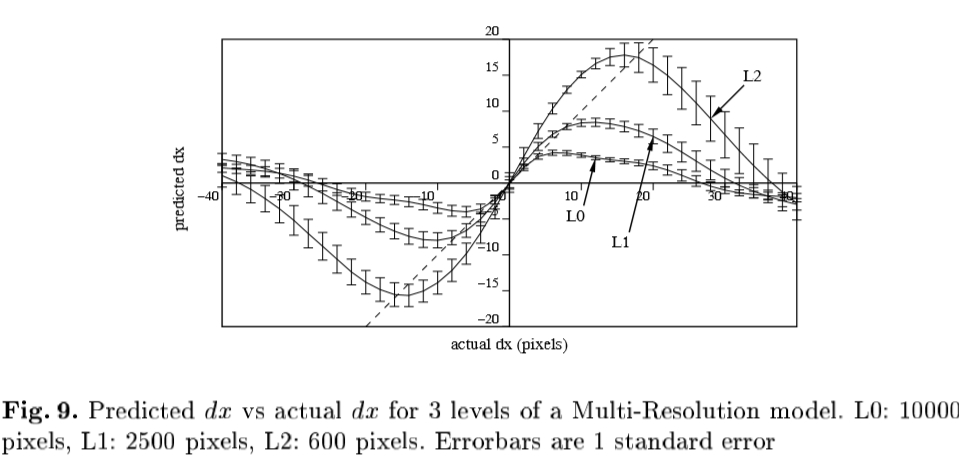
图9:预测DX VS为3个级别的多分辨率模型的实际DX。 L0:10000个像素,L1:2500个像素,L 2:600个像素。 Errorbars是1个标准误差
该曲线的线性区域延伸超过较粗分辨率更大的范围内,但是比在最精细分辨率不太准确。类似的结果在其他姿态参数变化和模型参数获得。
3.3迭代模型细化
鉴于预测其需要作出修正模型中的参数,我们可以构造一个迭代的方法解决我们的优化问题的方法。
给定模型参数,c0,并在当前估计的归一化图像样本,gs的当前估计,迭代过程的一个步骤如下:

—评估误差矢量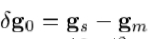
—评估当前误差
—计算预测位移
—设置
—让
—采样图像在这个新的预测,和计算一个新的误差向量,
—如果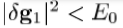 ,然后接受新的估计
,然后接受新的估计
—否则,尝试让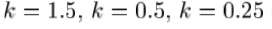 等等。
等等。
重复这个过程,直到没有改善的错误,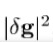 ,并且收敛声明。
,并且收敛声明。
我们使用了多分辨率的实施,我们遍历每个级别突出当前的解决方案,以模型的一个新的水平之前接轨。这是更,有效的,可以在一个单一的解决方案从更远低于搜索收敛到正确的解决方案。
主动外观模型搜索的例子:我们使用的面部AAM搜索的面孔以前看不到的影像图10显示给打上了手三面图像点模型的最佳选择。图11示出了从AAM搜索每个面帧,每个帧开始与来自真实面中心偏移的平均模型。
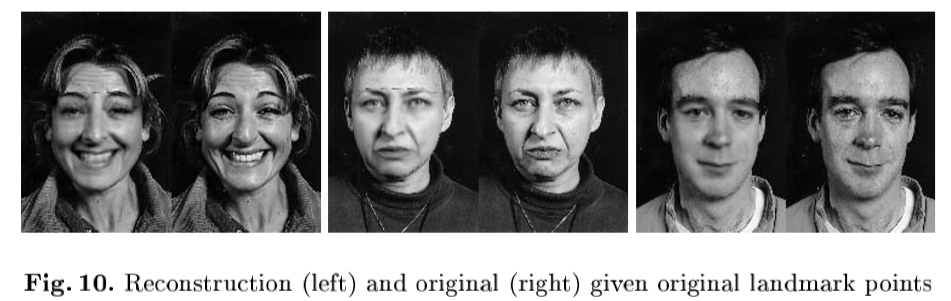
图10:重构(左)和原(右)输入的原地标点
如将该方法应用于医学图像的一个例子,我们建立的膝部的一部分的外观模型通过一个MR图像中的切片可见。该模型上训练30个的例子中,每个标记42个标志点。

图11:从移动后的位置多分辨率搜索
图12示出不同的前两个外观模型参数的效果。图13显示模式,以新的形象的最佳配合,给手打上标志点。图14示出从移位位置的AAM搜索帧。

图12:膝模型的外观变化的前两种模式 图13:膝关节模型的最佳匹配,以全新的形象给地标
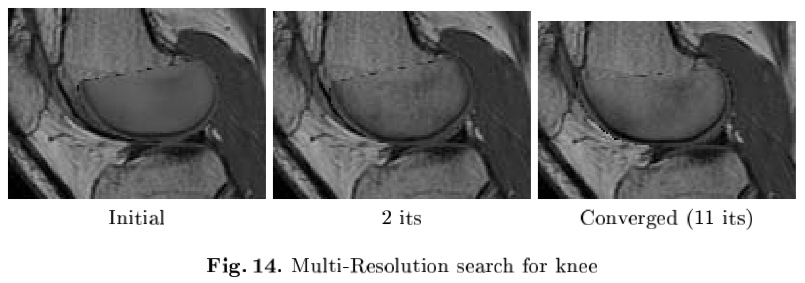
图14:多分辨率搜索膝盖
4 实验结果
为了获得算法的性能的定量评估我们培养88个上标记的手脸图像的模型,并测试其在不同的一组100个标记图像。每个面大约200像素宽。
上每一个测试图像,我们系统地在x和y  15个像素移位从真实位置的模型,并且通过10%改变其尺度。然后,我们跑了多分辨率搜索,从平均外观模型。 2700次搜查,共运行在Sun的超每次取4.1秒的平均。那些2700,519(19%)未能收敛到令人满意的结果(平均点的位置误差为每点大于7.5像素)。那些没有收敛的,模型中心与目标中心之间的RMS误差为(0.8,1.8)的像素。该S.D.模型规模误差为6%。相对于最佳模型的归一化帧在最终图像错误向量的平均量值拟合给定标记的点,为0.88(标准差:0.1),这表明该算法定位比由所标记的点提供更好的结果。因为它明确地最小化误差向量,它会如果导致灰度配合的整体改善妥协的形状。
15个像素移位从真实位置的模型,并且通过10%改变其尺度。然后,我们跑了多分辨率搜索,从平均外观模型。 2700次搜查,共运行在Sun的超每次取4.1秒的平均。那些2700,519(19%)未能收敛到令人满意的结果(平均点的位置误差为每点大于7.5像素)。那些没有收敛的,模型中心与目标中心之间的RMS误差为(0.8,1.8)的像素。该S.D.模型规模误差为6%。相对于最佳模型的归一化帧在最终图像错误向量的平均量值拟合给定标记的点,为0.88(标准差:0.1),这表明该算法定位比由所标记的点提供更好的结果。因为它明确地最小化误差向量,它会如果导致灰度配合的整体改善妥协的形状。
图15显示了每像素的平均强度误差(对于使用256个灰度级的图像)相对于迭代次数,平均超过在单一分辨率的一组搜索。在每种情况下,模型是由最多15个像素最初位移。虚线使用手标记标志点,这表明了良好的结果由搜索获得给出了平均重构误差。
图16示出的该融合型正确地给定由在x和y至多50个像素从真实位置移位的起始位置100的多分辨率搜索的比例。该模型显示具有高达20个像素的位移(面宽度的10%)良好的结果。
5讨论和结论
我们已经证明了安装的主动外观模型新图像的迭代方案。该方法利用了模型的位移和所得到的差图像之间的相关性学习的。给定一个合理的初始起始位置,搜索迅速收敛。虽然它不是一个主动形状模型慢[6],由于使用所有的图像证据,程序应该比单独ASM搜索更强劲。我们目前正在研究进一步改进追求效率,例如,子采样两种模型和图像。
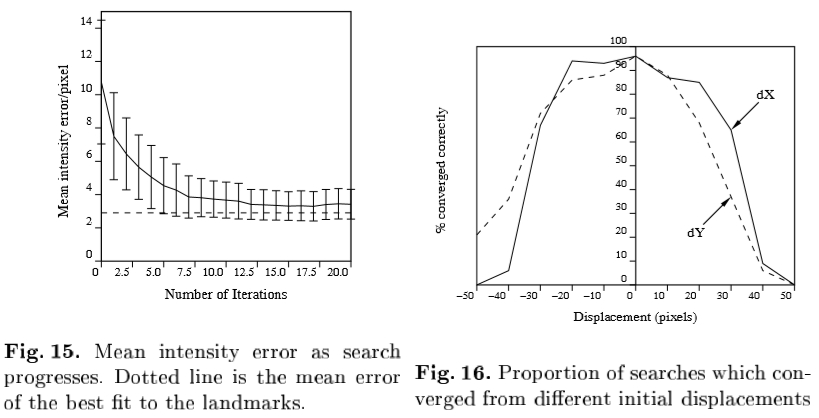
图15:平均强度误差作为搜索过程。虚线是最适合的标志性建筑的平均误差。 图16:搜索的比例从不同的初始位移会聚
该算法可以被认为是作为一个差动光流方法,其中,我们得知用改变每个参数相关联的变化的图案。像的差分光流,它只能以相对小的变化应付(虽然在训练阶段使它更健壮)。为了应对更大的位移,我们正在探索技术类似于基于相关的光流,在该模型的子区域进行了系统的位移找到当地最好的校正。
我们试图找到一些矢量值模型V(c),它最小化 ,其中为c变化
,其中为c变化 可能会发生变化的所述参数c。不包含其他信息,这将是艰难的啮合,但可以用通用算法,如鲍威尔,单层,模拟退火或遗传算法[17]加以解决。然而,通过获得衍生的估计,
可能会发生变化的所述参数c。不包含其他信息,这将是艰难的啮合,但可以用通用算法,如鲍威尔,单层,模拟退火或遗传算法[17]加以解决。然而,通过获得衍生的估计,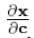 我们可以更有效地直接搜索。上述算法是最陡到梯度下降,在此我们使用我们的衍生物的估计,与电流误差矢量相结合,以确定下一个方向来搜索相关。有可能修改该算法更象一个共轭梯度下降法,或使用第二订货信息使用Levenberg-Marquardt算法[17],这可能导致更快的收敛。
我们可以更有效地直接搜索。上述算法是最陡到梯度下降,在此我们使用我们的衍生物的估计,与电流误差矢量相结合,以确定下一个方向来搜索相关。有可能修改该算法更象一个共轭梯度下降法,或使用第二订货信息使用Levenberg-Marquardt算法[17],这可能导致更快的收敛。
搜索算法的特性使得它适于跟踪对象在图像序列,其中可以示出,得到稳定的结果[10]。在实验中,上面我们已经审查了比较大的位移搜索。在实践中,一个良好的初始起点,可以通过多种方法来发现。我们可以使用一个ASM,它沿型材搜索可以从大的位移收敛。可替代地,我们可以训练的刚性固有特征类型的模型[15] [4],它被用来定位使用相关的对象。那么AAM的几个迭代将完善这一初步估计。
我们预计,AAM算法将在许多应用中定位变形对象的重要方法。
参考文献
1.Bajcsy and A.Kovacic.Multiresolution elastic matching.Computer Graphics and Image Processing,46:1-21,1989.
2.M.J.Black and Y.Yacoob.Recognizing facial expressions under rigid and nonrigid facial motions.In 1st International Workshop on Automatic Face and Gesture Recognition 1995,pages 12-17,Zurich,1995.
3.G.E.Christensen,R.D.Rabbitt,M.I.Miller,S.C.Joshi,U.Grenander,T.A.Coogan,and D.C.V.Essen.Topological Properties of Smooth Anatomic Maps, pages 101-112.Kluwer Academic Publishers,1995.
4.T.Cootes,G.Page,C.Jackson,and C.Taylor.Statistical grey-level models for object location and identification.Image and Vision Computing,14(8):533-540,
1996.
5.T.Cootes and C.Taylor.Modelling object appearance using the grey-level surface. In E.Hancock,editor,5th British Machine Vison Conference,pages 479-488,York, England,September 1994.BMVA Press.
6.T.F.Cootes,C.J.Taylor,D.H.Cooper,and J.Graham.Active shape models-their training and application.Computer Vision and Image Understanding, 61(1):38-59,January 1995.
7.M.Covell.Eigen-points:Control-point location using principal component analysis.In 2d International Conference on Automatic Face and Gesture Recognition 1997,pages 122-127,Killington,USA,1996.
8.G.J.Edwards,C.J.Taylor,and T.Cootes.Learning to identify and track faces in image sequences.In 8th British Machine Vison Conference,Colchester,UK,1997.
9.G.J.Edwards,C.J.Taylor,and T.Cootes.Face recognition using the active appearance model.In 5th European Conference on Computer Vision,1998.
10.T.Ezzat and T.Poggio.Facial analysis and synthesis using image-based models. In 2d International Conference on Automatic Face and Gesture Recognition 1997, pages 116-121,Killington,Vermont,1996.
11.U.Grenander and M.Miller.Representations of knowledge in complex systems. Journal of the Royal Statistical Society B,56:249-603,1993.
12.M.J.Jones and T.Poggio.Multidimensional morphable models.In 6th International Conference on Computer Vision,pages 683-688,1998.
13.M.Lades,J.Vorbruggen,J.Buhmann,J.Lange,C.von der Malsburt,R.Wurtz,and W.Konen.Distortion invariant object recognition in the dynamic link architecture.IEEE Transactions on Computers,42:300-311,1993.
14.A.Lanitis,C.Taylor,and T.Cootes.Automatic interpretation and coding of face images using flexible models.IEEE Transactions on Pattern Analysis and Machine Intelligence,19(7):743-756,1997.
15.B.Moghaddam and A.Pentland.Probabilistic visual learning for object recognition.In 5th International Conference on Computer Vision,pages 786-793,Cambridge,USA,1995.
16.C.Nastar,B.Moghaddam,and A.Pentland.Generalized image matching:Statistical learning of physically-based deformations.In 4th European Conference on Computer Vision,volume 1,pages 589-598,Cambridge,UK,1996.
17.W.Press,S.Teukolsky,W.Vetterling,and B.Flannery.Numerical Recipes in C (2nd Edition).Cambridge University Press,1992.
18.S.Sclaroff and J.Isidoro.Active blobs.In 6th International Conference on Computer Vision,pages 1146-53,1998.
19.L.H.Staib and J.S.Duncan.Boundary finding with parametrically deformable models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 14(11):1061-1075,1992.
20.M.Turk and A.Pentland.Eigenfaces for recognition.Journal of Cognitive Neu-roscience,3(1):71-86,1991.