File对象可以表示存在的文件或文件夹,也可以表示不存在的。我们想要得到文件的内容怎么办,File只是操作文件,文件的内容如何处理就需要使用io流技术了。例如在C盘下有一个名称为a.txt的文本文件.想要通过Java程序读出来文件中的内容,需要使用IO流技术.同样想要将程序中的数据,保存到硬盘的文件中,也需要IO流技术.
IO流简介:(Input/Output)
I/O类库中使用“流”这个抽象概念。Java对设备中数据的操作是通过流的方式。表示任何有能力产出数据的数据源对象,或者是有能力接受数据的接收端对象。“流”屏蔽了实际的I/O设备中处理数据的细节。IO流用来处理设备之间的数据传输。设备是指硬盘、内存、键盘录入、网络等。Java用于操作流的对象都在IO包中。IO流技术主要用来处理设备之间的数据传输。由于Java用于操作流的对象都在IO包中。所以使用IO流需要导包如:import java.io.*;
IO流的分类
字节流: 字节流读取得都是文件中二进制数据,读取到二进制数据不会经过任何的处理。
字符流: 字符流读取的数据是以字符为单位的 。 字符流也是读取文件中的二进制数据,不过会把这些二进制数据转换成我们能 识别的字符。 字符流 = 字节流 + 解码

输入字节流:
--------| InputStream 所有输入字节流的基类 抽象类
------------| FileInputStream 读取文件数据的输入字节流
使用流就像使用水管一样,要打开就要关闭。所以打开流和关闭流的动作是比不可少的。如何关闭流?使用close方法即可,当完成流的读写时,应该通过调用close方法来关闭它,这个方法会释放掉十分有限的操作系统资源.如果一个应用程序打开了过多的流而没有关闭它们,那么系统资源将被耗尽.
使用FileInputStream读取文件数据的步骤:
1. 找到目标文件
2. 建立数据的输入通道。
3. 读取文件中的数据。
4. 关闭 资源.
四种方式读取文件内容:
方法一:
public static void readFile01() throws IOException {//不能读到完整的文件内容 File file=new File("D:\java\传智java\day03\day03流程控制语句.doc");//找到目标文件 FileInputStream fileInputStream=new FileInputStream(file);//建立文件输入通道 int count =fileInputStream.read();//读取文件。 System.out.println(count); fileInputStream.close();//关闭资源 }
此方法确定:只能读取一个字节,不能读取完整的数据。
将上述方法进行优化,FileInputStream的read方法当字节已经到达末尾处时,就不进行读取了。

方法二:
import java.io.File; import java.io.FileInputStream; import java.io.IOException; public class Demo03 { public static void main(String[] args) throws IOException { readFile(); } public static void readFile() throws IOException{ File file =new File("C:\a.txt"); FileInputStream fileInputStream=new FileInputStream(file); int conent=0; while ((conent=fileInputStream.read())!=-1) { System.out.print((char)conent); }
fileInputStream.close(); } }
当字节已经到达末尾处时,就不进行读取了。
读取的内容是:abc
方式三:
//方式3:使用缓冲 数组 读取。 缺点: 无法读取完整一个文件的数据。 public static void readFile3() throws IOException{ //找到目标文件 File file = new File("C:\a.txt"); //建立数据的输入通道 FileInputStream fileInputStream = new FileInputStream(file); //建立缓冲字节数组,读取文件的数据。 byte[] buf = new byte[1024]; //相当于超市里面的购物车。当文件大于1024字节时,后面的内容就无法获取了。 int length = fileInputStream.read(buf); // 如果使用read读取数据传入字节数组,那么数据是存储到字节数组中的,而这时
//候read方法的返回值是表示的是本次读取了几个字节数据到字节数组中。 System.out.println("length:"+ length); //使用字节数组构建字符串 String content = new String(buf,0,length); System.out.println("内容:"+ content); //关闭资源 fileInputStream.close(); }
此处使用1024长度构建数组,但有时读取数据时没1024,而此时构造字符串时,依然使用的1024字节区构建。我们可以写成,读取多少个字节就存储多少个字节。
int length = fileInputStream.read(buf);
byte[] buf = new byte[1024]; //相当于超市里面的购物车。当文件大于1024字节时,后面的内容就无法获取了。
String content = new String(buf,0,length);
方式4:
//方式4:使用缓冲数组配合循环一起读取。28 public static void readTest4() throws IOException{ long startTime = System.currentTimeMillis(); //找到目标文件 File file = new File("C:\a.txt"); //建立数据的输入通道 FileInputStream fileInputStream = new FileInputStream(file); //建立缓冲数组配合循环读取文件的数据。 int length = 0; //保存每次读取到的字节个数。 byte[] buf = new byte[1024]; //存储读取到的数据 缓冲数组 的长度一般是1024的倍数,因为与计算机的处理单位。 理论上缓冲数组越大,效率越高 while((length = fileInputStream.read(buf))!=-1){ // read方法如果读取到了文件的末尾,那么会返回-1表示。 System.out.print(new String(buf,0,length)); } //关闭资源 fileInputStream.close(); long endTime = System.currentTimeMillis(); System.out.println("读取的时间是:"+ (endTime-startTime)); //446 }
一般使用第四种方式读取,效率比较高,既能读取完整数据,又能将内容存储到缓冲数据。
字节数据存取的特点:覆盖,
byte [] buff=new byte [4];
new String(buf,0,length)
比如文件存储的内容是aaaabbb
每次读取4个字节。结果是:[97,97,97,97][98,98,98,97],当读取bbb的内容时,最后被97覆盖。
如果此时写成new string(buf)时,读取的内容是aaaabbba;
我们清楚读取文件数据使用缓冲数组读取效率更高,sun也知道使用缓冲数组读取效率更高,那么
这时候sun给我们提供了一个------缓冲输入字节流对象,让我们可以更高效率读取文件。
输入字节流体系:
----| InputStream 输入字节流的基类。 抽象
----------| FileInputStream 读取文件数据的输入字节流
----------| BufferedInputStream 缓冲输入字节流 缓冲输入字节流的出现主要是为了提高读取文件数据的效率。
其实该类内部只不过是维护了一个8kb的字节数组而已。
注意: 凡是缓冲流都不具备读写文件的能力。
使用BufferedInputStream的步骤 :
1. 找到目标文件。
2. 建立数据 的输入通道
3. 建立缓冲 输入字节流流
4. 关闭资源
public static void readTest2() throws IOException{ //找到目标文件 File file = new File("F:\a.txt"); FileInputStream fileInputStream= new FileInputStream(file); BufferedInputStream bufferedInputStream= new BufferedInputStream(fileInputStream); //读取文件数据 int content = 0 ; //疑问二:BufferedInputStream出现 的目的是了提高读取文件的效率,但是BufferedInputStream的read方法每次读取一个字节的数据 //而FileInputStreram每次也是读取一个字节的数据,那么BufferedInputStream效率高从何而来? while((content =bufferedInputStream.read())!=-1){ System.out.print((char)content); } //关闭资源
bufferedInputStream.close();//调用BufferedInputStream的close方法实际上关闭的是FileinputStream. }
bufferinputstream 的close方法源码,调用BufferedInputStream的close方法实际上关闭的是FileinputStream.
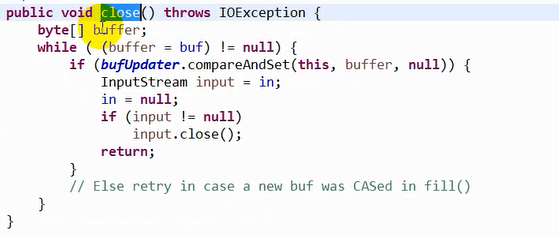
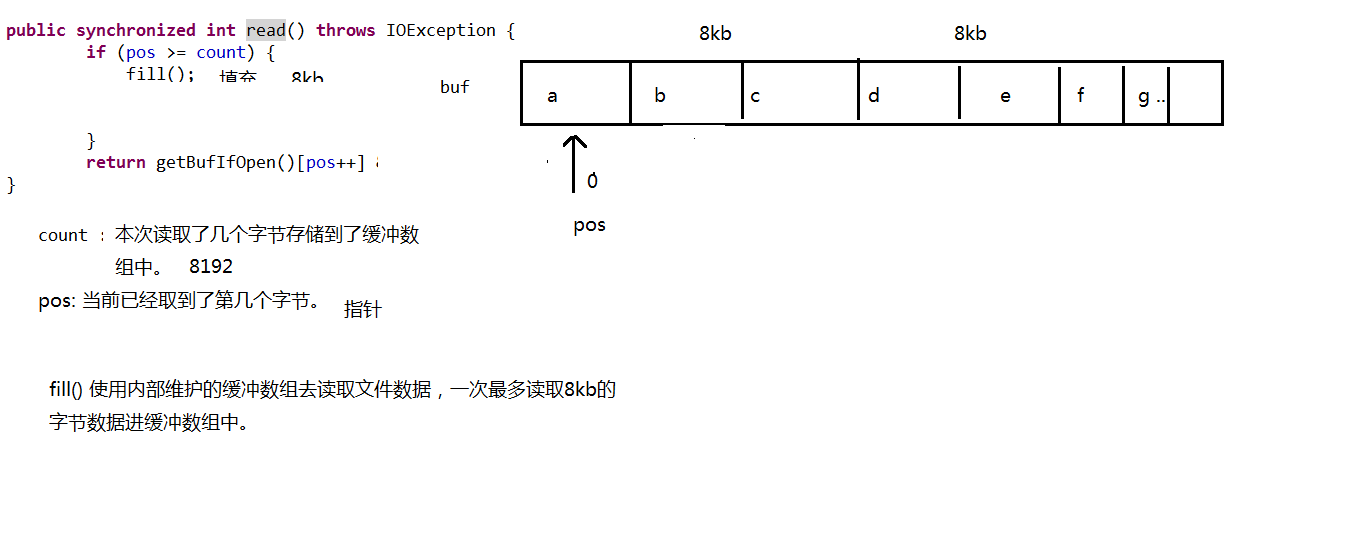
bufferinputstream的出现是底层维护一个8kb的字节数据,相对于byte []buff=new byte[1024*8];但是也要new bufferinputstream
2种方式的使用看个人爱好。。