使用序列拆分操作符(*)来提供位置参数。
例如函数heron的参数存放于一个列表sides中,可以:heron(sides[0],sides[1],sides[2]) 也可以进行拆分:heron(*sides)。如果列表包含比函数参数更多的项数,就可以使用分片提取出合适的参数。
1.在使用可变数量的位置参数的函数时,可使用
序列拆分操作符(*)。
#1.此时,args是一个完整的序列,*args表示将一个序列中的所有元素拆分出来作为函数的参数
>>> def product(*args): result = 1 for arg in args: result *= arg return result #2.因此,传参时应该传同属于一个序列的拆分后的元素 >>> product(1,2,3,4) 24 >>> product(5,3) 15
可以将关键字参数放在位置参数后面,即def sum_of_power(*args,poewer=1):...
* 本身作为参数:表明在*后面不应该再出现位置参数,但关键字参数是允许的:def heron(a,b,c,*,unit="meters"):.....
如果将* 作为第一个参数,那么不允许使用任何位置参数,并强制调用该函数时使用关键字参数:def print_set(*,paper="Letter",copies=1,color=False):...。可以不使用任何参数调用 print_set(),也可以改变某些或全部默认值。但如果使用位置参数,就会产生TypeError异常,比如print_set(“A4”)就会产 生异常。
2.对映射进行拆分时,可使用
映射拆分操作符(**)
例如使用**将字典传递给print_set()函数:
options = dict(paper="A4",color=True)
pritn_set(**options)
将字典的键值对进行拆分,每个键的值被赋予适当的参数,参数名称与键相同。
在参数中使用**,创建的函数可以接受给定的任意数量的关键字参数:
>>> def add_person_details(ssn,surname,**kwargs):
print ("SSN=",ssn)
print ("surname=",surname)
for key in sorted(kwargs):
print ("{0}={1}".format(key,kwargs[key]))
>>> add_person_details(123,"Luce",forename="Lexis",age=47)
SSN= 123
surname= Luce
age=47
forename=Lexis
>>> add_person_details(123,"Luce")
SSN= 123
surname= Luce
序列拆分符与映射拆分符举例:
#此处,args是一个序列,*表示将args拆分,所以*args作为函数的第一参数时,表示print_args第一个参数的位置可以
#接受任意多个元素(同属于一个序列的),对于**kwargs参数也是同样的道理
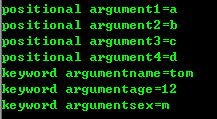
>>> def print_args(*args, **kwargs): for i,arg in enumerate(args): print "positional argument{0}={1}".format(i,arg) for key in kwargs: print "keyword argument{0}={1}".format(key,kwargs[key]) >>> print_args('a','b','c','d',name='Tom',age=12,sex='f')
结果:
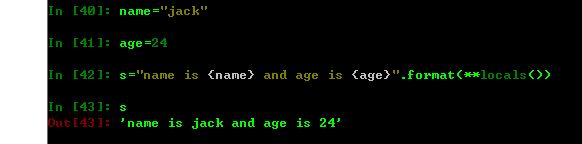
映射拆分举例:
name="jack"
age=24
s="name is {name} and age is {age}".format(**locals())
print s
结果:
参考文献:Mark Summerfield.《Python3程序开发指南》.149-151.