参考原博客: https://blog.csdn.net/weixin_44516305/article/details/90258883
1 需求分析
使用Flink对实时数据流进行实时处理,并将处理后的结果保存到Elasticsearch中,在Elasticsearch中使用IK Analyzer中文分词器对指定字段进行分词。
为了模拟获取流式数据,自定义一个流式并行数据源,每隔10ms生成一个Customer类型的数据对象并返回给Flink进行处理。
Flink处理后的结果保存在Elasticsearch中的index_customer索引的type_customer类型中,并且对description字段的数据使用IK Analyzer中文分词器进行分词。
2 Flink实时处理
2.1 版本说明
- Flink:1.8.0
- Elasticsearch:6.5.4
- JDK:1.8
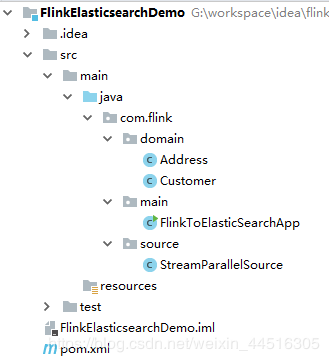
使用IDEA创建一个名称为FlinkElasticsearchDemo的Maven工程,目录结构如下图所示:
2.3 程序代码
- 在pom.xml中引入flink以及flink连接elasticsearch相关的依赖,代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.flink</groupId>
<artifactId>flink-elasticsearch-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.11</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.56</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2. 创建两个具有依赖关系的实体类Customer和Address,用于封装实时数据,代码如下所示:
package com.flink.domain;
import java.util.Date;
/**
* 客户实体类
*/
public class Customer {
private Long id;
private String name;
private Boolean gender;
private Date birth;
private Address address;
private String description;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Boolean getGender() {
return gender;
}
public void setGender(Boolean gender) {
this.gender = gender;
}
public Date getBirth() {
return birth;
}
public void setBirth(Date birth) {
this.birth = birth;
}
public Address getAddress() {
return address;
}
public void setAddress(Address address) {
this.address = address;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
}
package com.flink.domain;
/**
* 地址实体类
*/
public class Address {
private Integer id;
private String province;
private String city;
public Address(Integer id, String province, String city) {
this.id = id;
this.province = province;
this.city = city;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getProvince() {
return province;
}
public void setProvince(String province) {
this.province = province;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
}
3. 自定义一个获取流式实时数据的Flink数据源,如下所示:
package com.flink.source;
import com.flink.domain.Address;
import com.flink.domain.Customer;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import java.util.Date;
import java.util.Random;
/**
* 自定义的流式并行数据源
*/
public class StreamParallelSource implements ParallelSourceFunction<Customer> {
private boolean isRunning = true;
private String[] names = new String[5];
private Address[] addresses = new Address[5];
private Random random = new Random();
private Long id = 1L;
public void init() {
names[0] = "刘备";
names[1] = "关羽";
names[2] = "张飞";
names[3] = "曹操";
names[4] = "诸葛亮";
addresses[0]= new Address(1, "湖北省", "武汉市");
addresses[1]= new Address(2, "湖北省", "黄冈市");
addresses[2]= new Address(3, "广东省", "广州市");
addresses[3]= new Address(4, "广东省", "深圳市");
addresses[4]= new Address(5, "浙江省", "杭州市");
}
/**
* 每隔10ms生成一个Customer数据对象(模拟获取实时数据)
*/
@Override
public void run(SourceContext sourceContext) throws Exception {
init();
while(isRunning) {
int nameIndex = random.nextInt(5);
int addressIndex = random.nextInt(5);
Customer customer = new Customer();
customer.setId(id++);
customer.setName(names[nameIndex]);
customer.setGender(random.nextBoolean());
customer.setBirth(new Date());
customer.setAddress(addresses[addressIndex]);
customer.setDescription("" + names[nameIndex] + "来自" + addresses[addressIndex].getProvince() + addresses[addressIndex].getCity());
/**
* 把创建的数据返回给Flink进行处理
*/
sourceContext.collect(customer);
Thread.sleep(10);
}
}
@Override
public void cancel() {
this.isRunning = false;
}
}
4. 编写一个Flink实时处理流式数据的主程序,代码如下所示:
package com.flink.main;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.serializer.SerializerFeature;
import com.flink.domain.Customer;
import com.flink.source.StreamParallelSource;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch6.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.client.Requests;
import java.util.ArrayList;
import java.util.List;
/**
* Flink实时处理并将结果写入到ElasticSearch主程序
*/
public class FlinkToElasticSearchApp {
public static void main(String[] args) throws Exception {
/**
* 获取流处理环境并设置并行度
*/
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
/**
* 指定数据源为自定义的流式并行数据源
*/
DataStream<Customer> source = env.addSource(new StreamParallelSource());
/**
* 对数据进行过滤
*/
DataStream<Customer> filterSource = source.filter(new FilterFunction<Customer>() {
@Override
public boolean filter(Customer customer) throws Exception {
if (customer.getName().equals("曹操") && customer.getAddress().getProvince().equals("湖北省")) {
return false;
}
return true;
}
});
/**
* 对过滤后的数据进行转换
*/
DataStream<JSONObject> transSource = filterSource.map(new MapFunction<Customer, JSONObject>() {
@Override
public JSONObject map(Customer customer) throws Exception {
String jsonString = JSONObject.toJSONString(customer, SerializerFeature.WriteDateUseDateFormat);
System.out.println("当前正在处理:" + jsonString);
JSONObject jsonObject = JSONObject.parseObject(jsonString);
return jsonObject;
}
});
/**
* 创建一个ElasticSearchSink对象
*/
List<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("localhost", 9200, "http"));
ElasticsearchSink.Builder<JSONObject> esSinkBuilder = new ElasticsearchSink.Builder<JSONObject>(
httpHosts,
new ElasticsearchSinkFunction<JSONObject>() {
@Override
public void process(JSONObject customer, RuntimeContext ctx, RequestIndexer indexer) {
// 数据保存在Elasticsearch中名称为index_customer的索引中,保存的类型名称为type_customer
indexer.add(Requests.indexRequest().index("index_customer").type("type_customer").id(String.valueOf(customer.getLong("id"))).source(customer));
}
}
);
// 设置批量写数据的缓冲区大小
esSinkBuilder.setBulkFlushMaxActions(50);
/**
* 把转换后的数据写入到ElasticSearch中
*/
transSource.addSink(esSinkBuilder.build());
/**
* 执行
*/
env.execute("execute FlinkElasticsearchDemo");
}
}
至此,使用Flink对流式数据进行实时处理并将处理结果保存到Elasticsearch中的程序已经全部完成。
说明:Flink把数据保存到Elasticsearch时,如果Elasticsearch中没有提前创建对应名称的索引,则会自动创建对应名称的索引。
如果不需要在Elasticsearch中对指定字段使用IK Analyzer中文分词器进行分词,则不需要阅读第3节内容,直接阅读第4节即可。
3 Elasticsearch准备
如果希望对Elasticsearch中指定索引中的数据的指定字段使用中文分词器进行分词,则需要先在Elasticsearch中创建索引并指定分词器,所以需要先确保Elasticsearch中已经安装了分词器插件。
说明:本文使用Elasticsearch可视化插件操作Elasticsearch。
3.1 安装IK Analyzer中文分词器
本文中使用的是IK Analyzer中文分词器,并且基于Window 10操作系统,具体的安装过程如下图所示:
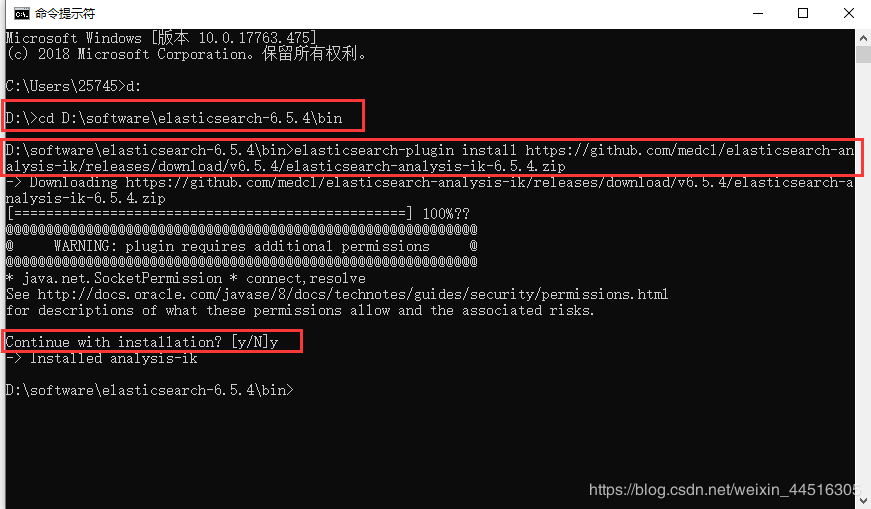
1 打开CMD命令窗口并切换到Elasticsearch安装目录下的bin目录中。
2 运行以下命令下载elasticsearch 6.5.4版本对应的IK Analyzer中文分词器:
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
3 下载完成后提示是否安装,直接输入y进行安装,完整的过程如下图所示:
4 安装完成后,在Elasticsearch的安装目录的plugins目录下会有一个analysis-ik目录,则表示安装完成,如下所示:

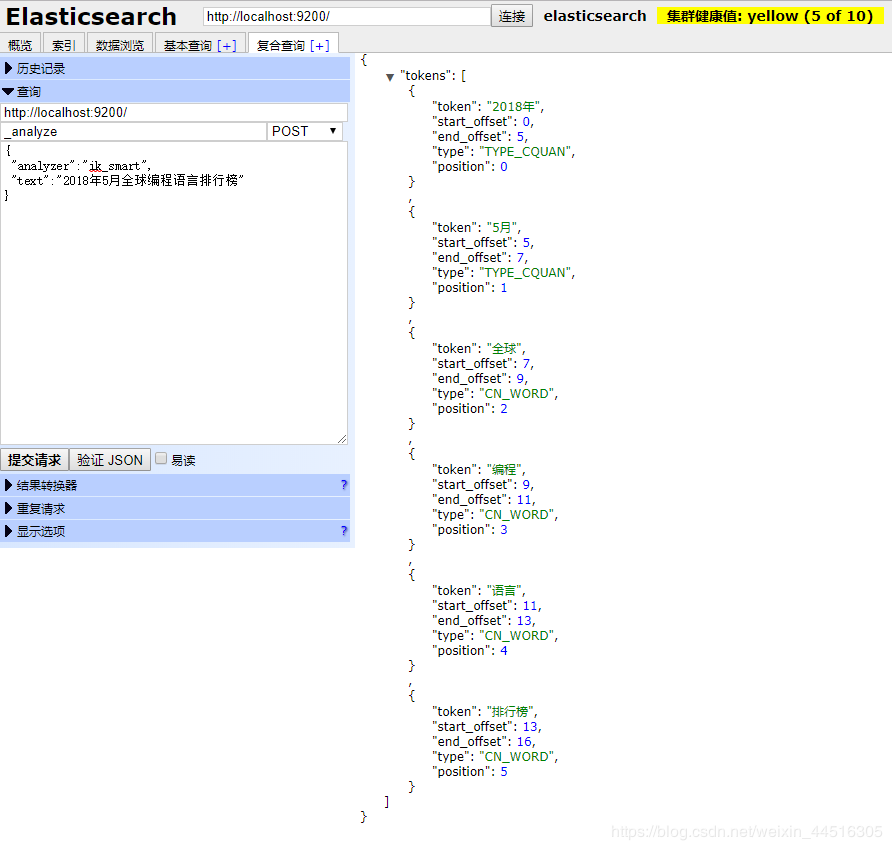
5 重启elasticsearch,并通过elasticsearch-head插件来检验IK Analyzer中文分词器是否已安装成功,在复合查询页面输入如下图所示内容,然后提交请求,如果出现如右图所示的分词结果就表明IK Analyzer中文分词器安装成功:
3.2 在Elasticsearch中创建索引
本文是要把过滤后符合条件的Customer类型的数据保存到ElasticSearch中,并能够对Customer中的description字段进行中文分词,
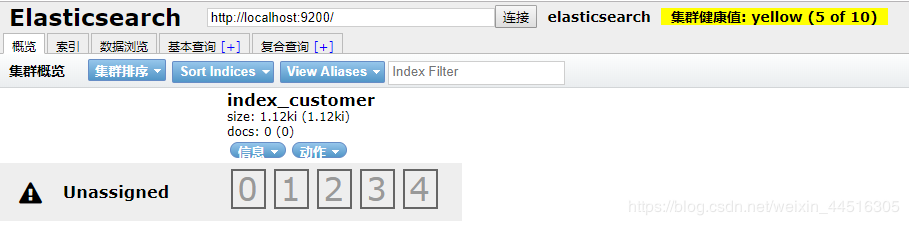
所以需要在Elasticsearch中创建一个索引,通过elasticsearch-head插件创建索引如下图所示,提交请求后如果如下图右边所示则创建成功:
创建索引index_customer的具体json体如下所示:
{
"settings": {
"index": {
"number_of_shards": "5",
"number_of_replicas": "1"
},
"analysis":{
"analyzer":{
"ik":{
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"type_customer": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text"
},
"gender": {
"type": "boolean"
},
"birth": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"address": {
"properties": {
"id": {
"type": "integer"
},
"province": {
"type": "keyword"
},
"city": {
"type": "keyword"
}
}
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
}
创建成功后在概览页面可以查看到如下信息:
4 测试Flink实时处理
启动Elasticsearch并成功创建索引后,直接运行程序中的FlinkToElasticSearchApp程序,在IDEA的控制台就可以看到如下输出信息,则表示Flink程序正在运行并进行实时处理:
此时,在Elasticsearch-head插件中可以查看到index_customer索引中的数据如下图所示,则表示Flink程序实时处理的结果已经正常保存到了Elasticsearch中:
由于本文在创建index_customer索引时,指定了对description字段使用IK Analyzer中文分词器,所以,在左侧的description字段索引框中输入查询内容之后,右边就会快速查询出description字段中包含了查询内容的所有的数据.
Flink写入数据到ElasticSearch (ElasticSearch详细使用指南及采坑记录)
https://blog.csdn.net/lisongjia123/article/details/81121994
Flink 写入数据到 ElasticSearch
https://blog.csdn.net/weixin_44876457/article/details/89398743