- xgboost 基本方法和默认参数
- 实战经验中调参方法
- 基于实例具体分析
在训练过程中主要用到两个方法:xgboost.train()和xgboost.cv().
xgboost.train(params,dtrain,num_boost_round=10,evals=(),obj=None,feval=None,maximize=False,early_stopping_rounds=None, evals_result=None,verbose_eval=True,learning_rates=None,xgb_model=None)
- params 这是一个字典,里面包含着训练中的参数关键字和对应的值,形式是params = {‘booster’:’gbtree’,’eta’:0.1}
- dtrain 训练的数据
- evals 这是一个列表,用于对训练过程中进行评估列表中的元素。形式是evals = [(dtrain,’train’),(dval,’val’)]或者是evals = [(dtrain,’train’)],对于第一种情况,它使得我们可以在训练过程中观察验证集的效果。
- obj,自定义目的函数
- feval,自定义评估函数
- early_stopping_rounds,早期停止次数 ,假设为100,验证集的误差迭代到一定程度在100次内不能再继续降低,就停止迭代。这要求evals 里至少有 一个元素,如果有多个,按最后一个去执行。返回的是最后的迭代次数(不是最好的)。如果early_stopping_rounds 存在,则模型会生成三个属性,bst.best_score,bst.best_iteration,和bst.best_ntree_limit
- evals_result 字典,存储在watchlist 中的元素的评估结果。
- verbose_eval (可以输入布尔型或数值型),也要求evals 里至少有 一个元素。如果为True ,则对evals中元素的评估结果会输出在结果中;如果输入数字,假设为5,则每隔5个迭代输出一次。
-
xgb_model ,在训练之前用于加载的xgb model。
scale_pos_weight [默认 1]
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
max_delta_step[默认0]
- 这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。
- 通常,这个参数不需要设置。但是当各类别的样本十分不平衡时,它对逻辑回归是很有帮助的。
- 这个参数一般用不到,但是你可以挖掘出来它更多的用处。
params = {
'booster':'gbtree',
'objective':'binary:logistic',
'eta':0.1,
'max_depth':10,
'subsample':1.0,
'min_child_weight':5,
'colsample_bytree':0.2,
'scale_pos_weight':0.1,
'eval_metric':'auc',
'gamma':0.2,
'lambda':300
}
colsample_bytree 要依据特征个数来判断
objective 目标函数的选择要根据问题确定,如果是回归问题 ,一般是 reg:linear , reg:logistic , count:poisson 如果是分类问题,一般是binary:logistic ,rank:pairwise
参数初步定之后划分20%为验证集,准备一个watchlist 给train和validation set ,设置num_round 足够大(比如100000),以至于你能发现每一个round 的验证集预测结果,如果在某一个round后 validation set 的预测误差上升了,你就可以停止掉正在运行的程序了。
watchlist = [(dtrain,'train'),(dval,'val')] model = xgb.train(params,dtrain,num_boost_round=100000,evals = watchlist)
然后开始逐个调参了。
1、首先调整max_depth ,通常max_depth 这个参数与其他参数关系不大,初始值设置为10,找到一个最好的误差值,然后就可以调整参数与这个误差值进行对比。比如调整到8,如果此时最好的误差变高了,那么下次就调整到12;如果调整到12,误差值比10 的低,那么下次可以尝试调整到15.
2、在找到了最优的max_depth之后,可以开始调整subsample,初始值设置为1,然后调整到0.8 如果误差值变高,下次就调整到0.9,如果还是变高,就保持为1.0
3、接着开始调整min_child_weight , 方法与上面同理
4、再接着调整colsample_bytree
5、经过上面的调整,已经得到了一组参数,这时调整eta 到0.05,然后让程序运行来得到一个最佳的num_round,(在 误差值开始上升趋势的时候为最佳 )
另外:
很幸运的是,Scikit-learn中提供了一个函数可以帮助我们更好地进行调参:
sklearn.model_selection.GridSearchCV
常用参数解读:
estimator:所使用的分类器,如果比赛中使用的是XGBoost的话,就是生成的model。比如: model = xgb.XGBRegressor(**other_params)
param_grid:值为字典或者列表,即需要最优化的参数的取值。比如:cv_params = {‘n_estimators’: [550, 575, 600, 650, 675]}
scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring=’roc_auc’,根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。scoring参数选择如下:
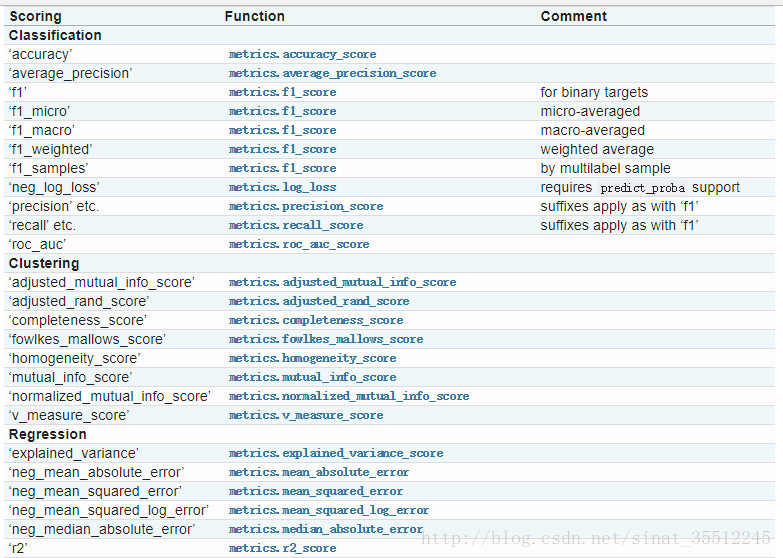
这次实战我使用的是r2这个得分函数,当然大家也可以根据自己的实际需要来选择。
调参刚开始的时候,一般要先初始化一些值:
learning_rate: 0.1
n_estimators: 500
max_depth: 5
min_child_weight: 1
subsample: 0.8
colsample_bytree:0.8
gamma: 0
reg_alpha: 0
reg_lambda: 1
你可以按照自己的实际情况来设置初始值,上面的也只是一些经验之谈吧。
调参的时候一般按照以下顺序来进行:
1、最佳迭代次数:n_estimators
if __name__ == '__main__':
trainFilePath = 'dataset/soccer/train.csv'
testFilePath = 'dataset/soccer/test.csv'
data = pd.read_csv(trainFilePath)
X_train, y_train = featureSet(data)
X_test = loadTestData(testFilePath)
cv_params = {'n_estimators': [400, 500, 600, 700, 800]}
other_params = {'learning_rate': 0.1, 'n_estimators': 500, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
model = xgb.XGBRegressor(**other_params)
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
optimized_GBM.fit(X_train, y_train)
evalute_result = optimized_GBM.grid_scores_
print('每轮迭代运行结果:{0}'.format(evalute_result))
print('参数的最佳取值:{0}'.format(optimized_GBM.best_params_))
print('最佳模型得分:{0}'.format(optimized_GBM.best_score_))
写到这里,需要提醒大家,在代码中有一处很关键:
model = xgb.XGBRegressor(**other_params)中两个*号千万不能省略!可能很多人不注意,再加上网上很多教程估计是从别人那里直接拷贝,没有运行结果,所以直接就用了model = xgb.XGBRegressor(other_params)。悲剧的是,如果直接这样运行的话,会报如下错误:
xgboost.core.XGBoostError: b"Invalid Parameter format for max_depth expect int but value...
不信,请看链接:xgboost issue
以上是血的教训啊,自己不运行一遍代码,永远不知道会出现什么Bug!
运行后的结果为:
[Parallel(n_jobs=4)]: Done 25 out of 25 | elapsed: 1.5min finished
每轮迭代运行结果:[mean: 0.94051, std: 0.01244, params: {'n_estimators': 400}, mean: 0.94057, std: 0.01244, params: {'n_estimators': 500}, mean: 0.94061, std: 0.01230, params: {'n_estimators': 600}, mean: 0.94060, std: 0.01223, params: {'n_estimators': 700}, mean: 0.94058, std: 0.01231, params: {'n_estimators': 800}]
参数的最佳取值:{'n_estimators': 600}
最佳模型得分:0.9406056804545407
由输出结果可知最佳迭代次数为600次。但是,我们还不能认为这是最终的结果,由于设置的间隔太大,所以,我又测试了一组参数,这次粒度小一些:
cv_params = {'n_estimators': [550, 575, 600, 650, 675]}
other_params = {'learning_rate': 0.1, 'n_estimators': 600, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
运行后的结果为:
每轮迭代运行结果:[mean: 0.94065, std: 0.01237, params: {'n_estimators': 550}, mean: 0.94064, std: 0.01234, params: {'n_estimators': 575}, mean: 0.94061, std: 0.01230, params: {'n_estimators': 600}, mean: 0.94060, std: 0.01226, params: {'n_estimators': 650}, mean: 0.94060, std: 0.01224, params: {'n_estimators': 675}]
参数的最佳取值:{'n_estimators': 550}
最佳模型得分:0.9406545392685364
果不其然,最佳迭代次数变成了550。有人可能会问,那还要不要继续缩小粒度测试下去呢?
这个我觉得可以看个人情况,如果你想要更高的精度,当然是粒度越小,结果越准确,大家可以自己慢慢去调试,我在这里就不一一去做了。
2、接下来要调试的参数是min_child_weight以及max_depth:
注意:每次调完一个参数,要把 other_params对应的参数更新为最优值。
cv_params = {'max_depth': [3, 4, 5, 6, 7, 8, 9, 10], 'min_child_weight': [1, 2, 3, 4, 5, 6]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
运行后的结果为:
[Parallel(n_jobs=4)]: Done 42 tasks | elapsed: 1.7min
[Parallel(n_jobs=4)]: Done 192 tasks | elapsed: 12.3min
[Parallel(n_jobs=4)]: Done 240 out of 240 | elapsed: 17.2min finished
每轮迭代运行结果:[mean: 0.93967, std: 0.01334, params: {'min_child_weight': 1, 'max_depth': 3}, mean: 0.93826, std: 0.01202, params: {'min_child_weight': 2, 'max_depth': 3}, mean: 0.93739, std: 0.01265, params: {'min_child_weight': 3, 'max_depth': 3}, mean: 0.93827, std: 0.01285, params: {'min_child_weight': 4, 'max_depth': 3}, mean: 0.93680, std: 0.01219, params: {'min_child_weight': 5, 'max_depth': 3}, mean: 0.93640, std: 0.01231, params: {'min_child_weight': 6, 'max_depth': 3}, mean: 0.94277, std: 0.01395, params: {'min_child_weight': 1, 'max_depth': 4}, mean: 0.94261, std: 0.01173, params: {'min_child_weight': 2, 'max_depth': 4}, mean: 0.94276, std: 0.01329...]
参数的最佳取值:{'min_child_weight': 5, 'max_depth': 4}
最佳模型得分:0.94369522247392
由输出结果可知参数的最佳取值:{'min_child_weight': 5, 'max_depth': 4}。(代码输出结果被我省略了一部分,因为结果太长了,以下也是如此)
3、接着我们就开始调试参数:gamma:
cv_params = {'gamma': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0, 'reg_alpha': 0, 'reg_lambda': 1}
[Parallel(n_jobs=4)]: Done 30 out of 30 | elapsed: 1.5min finished
每轮迭代运行结果:[mean: 0.94370, std: 0.01010, params: {'gamma': 0.1}, mean: 0.94370, std: 0.01010, params: {'gamma': 0.2}, mean: 0.94370, std: 0.01010, params: {'gamma': 0.3}, mean: 0.94370, std: 0.01010, params: {'gamma': 0.4}, mean: 0.94370, std: 0.01010, params: {'gamma': 0.5}, mean: 0.94370, std: 0.01010, params: {'gamma': 0.6}]
参数的最佳取值:{'gamma': 0.1}
最佳模型得分:0.94369522247392
由输出结果可知参数的最佳取值:{'gamma': 0.1}。
4、接着是subsample以及colsample_bytree:
cv_params = {'subsample': [0.6, 0.7, 0.8, 0.9], 'colsample_bytree': [0.6, 0.7, 0.8, 0.9]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.8, 'colsample_bytree': 0.8, 'gamma': 0.1, 'reg_alpha': 0, 'reg_lambda': 1}
运行后的结果显示参数的最佳取值:{'subsample': 0.7,'colsample_bytree': 0.7}
5、紧接着就是:reg_alpha以及reg_lambda:
cv_params = {'reg_alpha': [0.05, 0.1, 1, 2, 3], 'reg_lambda': [0.05, 0.1, 1, 2, 3]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.7, 'colsample_bytree': 0.7, 'gamma': 0.1, 'reg_alpha': 0, 'reg_lambda': 1}
运行后的结果为:
[Parallel(n_jobs=4)]: Done 42 tasks | elapsed: 2.0min
[Parallel(n_jobs=4)]: Done 125 out of 125 | elapsed: 5.6min finished
每轮迭代运行结果:[mean: 0.94169, std: 0.00997, params: {'reg_alpha': 0.01, 'reg_lambda': 0.01}, mean: 0.94112, std: 0.01086, params: {'reg_alpha': 0.01, 'reg_lambda': 0.05}, mean: 0.94153, std: 0.01093, params: {'reg_alpha': 0.01, 'reg_lambda': 0.1}, mean: 0.94400, std: 0.01090, params: {'reg_alpha': 0.01, 'reg_lambda': 1}, mean: 0.93820, std: 0.01177, params: {'reg_alpha': 0.01, 'reg_lambda': 100}, mean: 0.94194, std: 0.00936, params: {'reg_alpha': 0.05, 'reg_lambda': 0.01}, mean: 0.94136, std: 0.01122, params: {'reg_alpha': 0.05, 'reg_lambda': 0.05}, mean: 0.94164, std: 0.01120...]
参数的最佳取值:{'reg_alpha': 1, 'reg_lambda': 1}
最佳模型得分:0.9441561344357595
由输出结果可知参数的最佳取值:{'reg_alpha': 1, 'reg_lambda': 1}。
6、最后就是learning_rate,一般这时候要调小学习率来测试:
cv_params = {'learning_rate': [0.01, 0.05, 0.07, 0.1, 0.2]}
other_params = {'learning_rate': 0.1, 'n_estimators': 550, 'max_depth': 4, 'min_child_weight': 5, 'seed': 0,
'subsample': 0.7, 'colsample_bytree': 0.7, 'gamma': 0.1, 'reg_alpha': 1, 'reg_lambda': 1}
运行后的结果为:
[Parallel(n_jobs=4)]: Done 25 out of 25 | elapsed: 1.1min finished
每轮迭代运行结果:[mean: 0.93675, std: 0.01080, params: {'learning_rate': 0.01}, mean: 0.94229, std: 0.01138, params: {'learning_rate': 0.05}, mean: 0.94110, std: 0.01066, params: {'learning_rate': 0.07}, mean: 0.94416, std: 0.01037, params: {'learning_rate': 0.1}, mean: 0.93985, std: 0.01109, params: {'learning_rate': 0.2}]
参数的最佳取值:{'learning_rate': 0.1}
最佳模型得分:0.9441561344357595
由输出结果可知参数的最佳取值:{'learning_rate': 0.1}。
我们可以很清楚地看到,随着参数的调优,最佳模型得分是不断提高的,这也从另一方面验证了调优确实是起到了一定的作用。不过,我们也可以注意到,其实最佳分数并没有提升太多。提醒一点,这个分数是根据前面设置的得分函数算出来的,即:
optimized_GBM = GridSearchCV(estimator=model, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=4)
1
中的scoring='r2'。在实际情境中,我们可能需要利用各种不同的得分函数来评判模型的好坏。
最后,我们把得到的最佳参数组合扔到模型里训练,就可以得到预测的结果了:
def trainandTest(X_train, y_train, X_test):
# XGBoost训练过程,下面的参数就是刚才调试出来的最佳参数组合
model = xgb.XGBRegressor(learning_rate=0.1, n_estimators=550, max_depth=4, min_child_weight=5, seed=0,
subsample=0.7, colsample_bytree=0.7, gamma=0.1, reg_alpha=1, reg_lambda=1)
model.fit(X_train, y_train)
# 对测试集进行预测
ans = model.predict(X_test)
ans_len = len(ans)
id_list = np.arange(10441, 17441)
data_arr = []
for row in range(0, ans_len):
data_arr.append([int(id_list[row]), ans[row]])
np_data = np.array(data_arr)
# 写入文件
pd_data = pd.DataFrame(np_data, columns=['id', 'y'])
# print(pd_data)
pd_data.to_csv('submit.csv', index=None)
# 显示重要特征
# plot_importance(model)
# plt.show()
好了,调参的过程到这里就基本结束了。正如我在上面提到的一样,其实调参对于模型准确率的提高有一定的帮助,但这是有限的。
最重要的还是要通过数据清洗,特征选择,特征融合,模型融合等手段来进行改进!
原文:https://blog.csdn.net/sinat_35512245/article/details/79700029
参考文献
https://www.kaggle.com/c/bnp-paribas-cardif-claims-management/forums/t/19083/best-practices-for-parameter-tuning-on-models
https://github.com/dmlc/xgboost/tree/master/demo
http://xgboost.readthedocs.io/en/latest/python/python_api.html