在处理数据的时候,很多时候会遇到批量替换的情况,如果一个一个去修改效率过低,也容易出错。replace()是很好的方法。
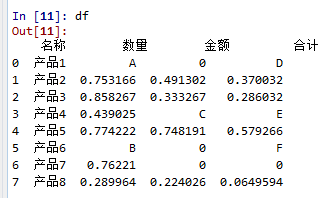
1.基本结构:
df.replace(to_replace, value) 前面是需要替换的值,后面是替换后的值。

这样会搜索整个DataFrame, 并将所有符合条件的元素全部替换。
进行上述操作之后,其实原DataFrame是并没有改变的。改变的只是一个复制品。
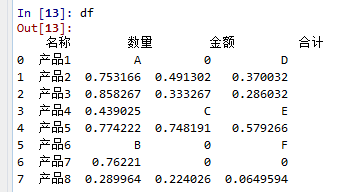
2. 如果需要改变原数据,需要添加常用参数 inplace=True

这个参数在一般情况没多大用处,但是如果只替换部分区域时,inplace参数就有用了。
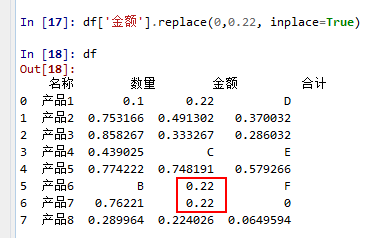
在上面这个操作中,‘合计’这一列中的0,并没有被替换。只有‘金额’这一列的0被替换,而且,替换后的结果不需要我们再和原数据进行合并操作,直接体现在原数据中。
只对某一列特定的值进行替换:
result['prediction'].replace([0,1,2,3,4,5,6,7,8],[870,870,880,898,1300,13117,13298,13690,13691],inplace=True)
BTW: 在pyspark 中的 replace() 函数
result.na.replace([0,1,2,3,4,5,6,7,8], [870,878,880,898,1300,13117,13298,13690,13691], 'prediction')
https://www.cnblogs.com/nshuai/articles/5762343.html