作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3223
作业要求:
1.安装Linux,MySql
- Linux安装过程略;
- Mysql已安装,运行过程如图:

2.安装Hadoop
还不能从windows复制文件的,可在虚拟机里用浏览器下载安装文件,课件:
提取文件:hadoop-2.7.1.tar.gz
链接: https://pan.baidu.com/s/1HIVd9JCZstWm0k7sAbXQCg
提取码: 2thj
- (1)创建的hadoop用户进行登陆
-
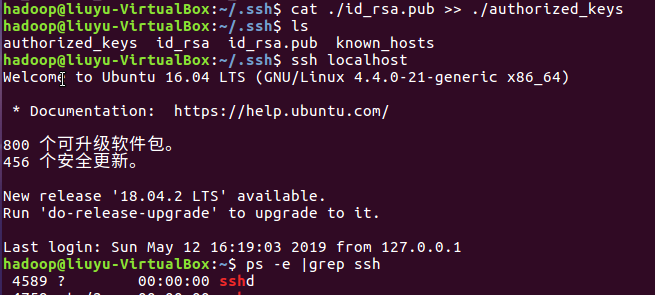
(2)更新apt后,安装SSH、配置SSH无密码登陆
安装SSH server,使用ssh localhost命令登录本机并查看是否安装成功:
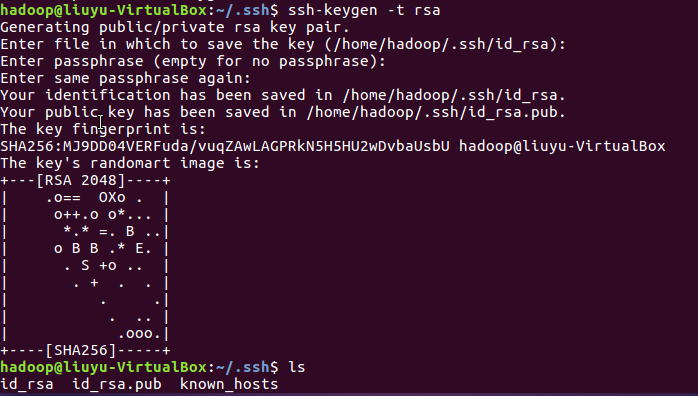
配置无密码登陆,生成密钥并将密钥加入到授权中 :
- (3)安装JAVA环境
安装JDK:
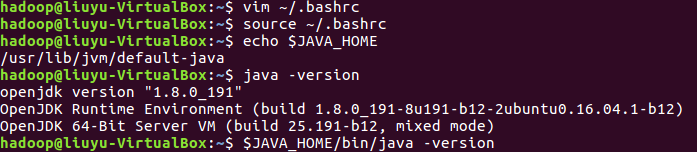
设置变量使其生效,检验变量值:
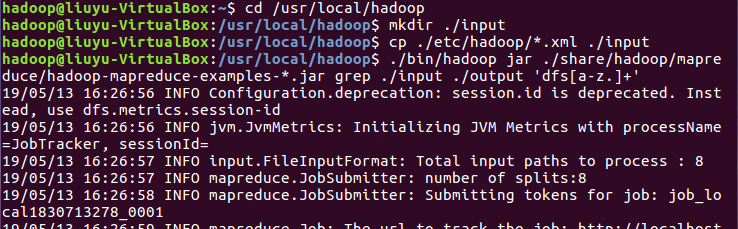
- (4)Hadoop单机配置(grep例子)
运行grep例子,筛选符合正值表达式正值表达式dfs[a-z.]+的单词并统计次数:
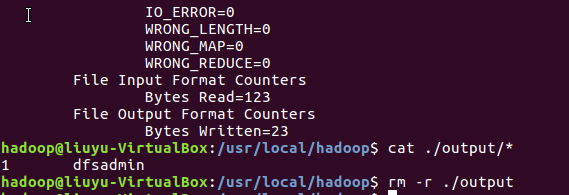
程序运行成功,执行结果符合正则的单词fsadmin出现1次,删除 ./output:
- (5)Hadoop伪分布式配置
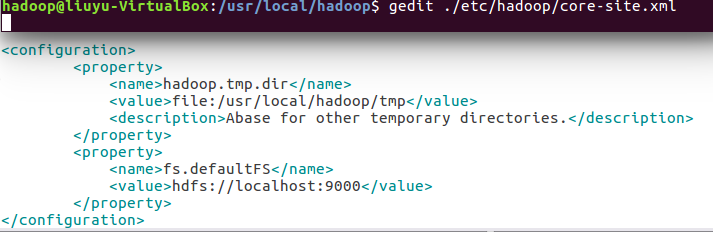
配置core-site.xml文件:
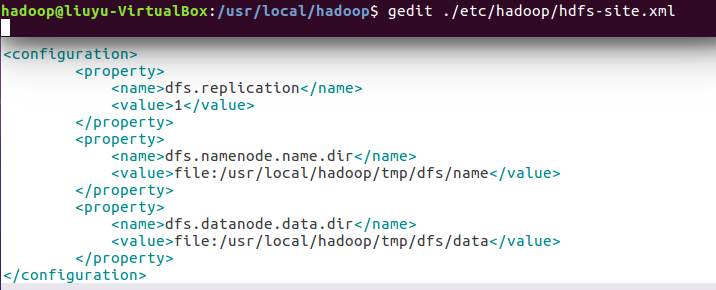
配置hdfs-site.xml文件:
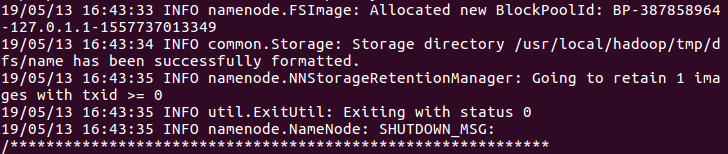
执行NameNode格式化:
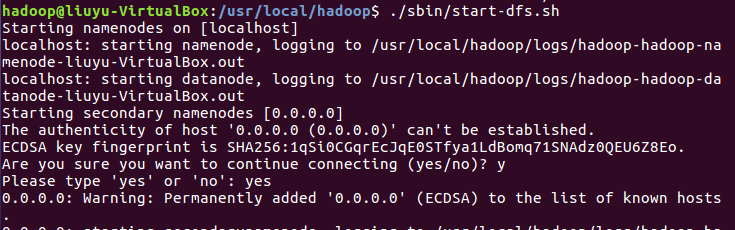
开启NameNode和DataNode守护进程:

- (6)伪分布式运行MapReduce作业
创建目录 input,将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中,查看文件列表并伪分布式运行 MapReduce 作业 :

![]()
运行上述命令后出现错误,主要原因是swap交换空间内存不够分配,因此运行失败,此过程跳过。
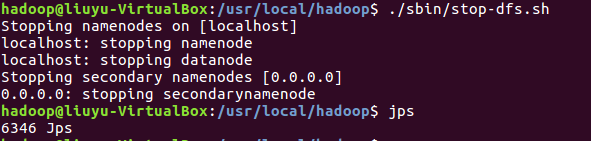
完成后关闭Hadoop: