方案一:
一个表,里面有个tags字段,存放以空格或逗号分隔的标签。缺点是长度受限,tag个数受限,查询like ‘%abc%’效率低
方案二:
同方案一,支持全文索引,或者用Lucence索引查询
方案三:
两个表,第一个表存储对应的文章等,第二个是tags表,存放第一个表的外键和tag的名称。解决了第一个方案的个数受限问题,不过这样的话会有冗余,比如两个表都有同样的tag名,则会出现两次。
方案三:
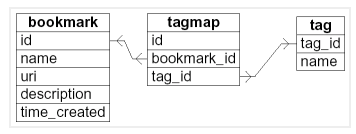
三个表,第二个tags表,第三个关联表,典型的3NF,最常规的设计,tag支持树状层级,缺点是千万级数据量的话关联表会非常大!
还有第五种第六种方案,比如增加缓存层,把例如针对”TagA+TagB”的查询缓存1小时,增加冗余列,例如TagA, TagANumber(内容个数), TagB, TagBNumber …
参考:http://www.ifanybug.com/article/00119.html