最大似然估计、最大后验估计与朴素贝叶斯分类算法
目录
一、前言
二、概率论基础
三、最大似然估计
四、最大后验估计
五、朴素贝叶斯分类
六、参考文献
一、前言
本篇文章的主要内容为笔者对概率论基础内容的回顾,及个人对其中一些知识点的解读。另外,在这些上述知识的基础之上,回顾了概率推断的基础内容最大似然估计与最大后验估计。最后,文章的结尾回顾了朴素贝叶斯分类方法的基本流程,并且用一个小案例来帮助读者更好地掌握该方法的基本流程。
二、概率论基础
(1)概率
定义[1]:设E是随机实验,S是它的样本空间。对于E的每一个事件A赋予一个实数,记为P(A),称为事件A的概率,如果集和函数P(.)满足如下条件:
(1)非负性:对每一个事件A,有P(A)>=0;
(2)规范性:对于必然事件S,有p(S)=1;
(3)可列可加性:设A1,A2,...是两两互不相容的事件,即对于AiAj=Ø,i≠j,i,j=1,2,...,有:
P(A1∪A2∪A3...)=P(A1)+P(A2)+P(A3)+....
(2)随机变量
一个随机变量指的是一个可以随机地取多种数值的的变量,本文中使用大写字母来表示随机变量,其取值则用小写字母表示,如:随机变量X,可以取值为{x1,x2,x3,...}。随机变量只是一种对随机现象所有可能状态的表示,其取值并不一定为实数,并且随机变量还需要搭配后面将会讲到的概率分布来确切地表达每一种状态可能发生的概率。例如,抛掷一枚硬币,硬币最后落地可能出现的结果是一个随机事件,我们可以用一个随机变量X来表示最后可能出现的结果,那么随机变量可能的取值为{正面,反面};抛掷一个骰子,我们将落地后正面的取值用随机变量Y来表示,其可能的取值为{1,2,3,4,5,6}。
(3)随机变量的概率分布
随机变量的概率分布用来说明随机变量所有可能取值的概率大小。由于随机变量的取值可以是离散的,如上述抛掷硬币和骰子例子;也可以是连续的,即随机变量所有的可能取值无法逐一列举出来,其取值可以为实数轴内某一区间内的任意一个点[2],例如:一个人双十一在淘宝上的消费数额,一个人每天的运动时长等等。对于离散型随机变量与连续型随机变量,分别使用概率质量函数与概率密度函数来描述其概率分布。
概率质量函数:一个随机变量X的概率质量函数将随机变量的每一个取值都映射到随机变量取该值时所对应的概率上,我们使用X~P(X)来表达”随机变量X服从P(X)分布“。一个随机变量X的概率质量函数P(X)需要满足如下性质:
(1)定义域必须是随机变量X所有可能的取值;
(2)对X的任意取值x,P(x)>=0 并且P(x)<=1
(3)Σx∈X P(X)=1
还是以抛硬币来作为例子,我们使用随机变量X来表示抛硬币最后可能的结果,该随机变量的所有可能取值为{正面,反面},根据我们的经验,一枚硬币的抛掷结果为正面或者反面的概率均为0.5,那么随机变量X所服从的概率质量分布为:P(X=正面)=0.5,P(X=反面)=0.5。
概率密度函数:由于连续型随机变量的所有可能取值无法逐一列举,其概率分布的描述方式与离散性随机变量不同,使用的是概率密度函数。对于一个概率密度函数F(X)而言,需要满足如下性质:
(1)其值域必须是随机变量所有可能取值的集和
(2)对X的任意取值x,F(x)>=0
(3)∫F(x)dx=1
对于连续型随机变量X而言,其取某一个值的概率为0,即P(X=x1)=0。常见的概率密度函数有均匀分布和正态分布。
(4)联合概率分布
联合分布指的是两个或者多个随机变量同时取某些值的概率分布。例如,对于随机变量X和Y而言,当X=x1,同时Y=y1时,其联合概率分布为P(X=x1,Y=y1)。下面以一个更为具体的例子来说明一下联合概率分布。一个盒子中有两红一白的三个球,现在从中不放回取出两个球,求下面的概率:
(1)第一次取出红球的概率;
(2)第二次取出红球的概率;
(3)两次同时取出红球的概率。
解答:
(1)以随机变量X来表示第一次取球的结果,显然P(X=红球)=2/3;
(2)以随机变量Y来表示第二次取球的结果,本问求的时P(Y=红球)。需要注意的是采取的是“不放回”的取球方式,第一次的取球结果会影响到盒子中红白球的比例,也就影响到了第二次取球的概率,因此需要根据第一次的取球结果来分情况探讨第二次取红球的所有可能的情况。如果第一次从两个红球中取出一个红球的话,那么第二次取出红球的所有可能情况为{红红,红红};如果第一次取出白球的话,那么第二次就可以从剩余的两个红球中取,因此所有可能的情况为{白红,白红}。总体的样本空间为{红白,红红,红白,红红,白红,白红},共6种情况,那么P(Y=红球)=2/3;
(3)第三问求的是当X=红球时,同时Y=红球的概率,是一个联合分布。根据上一问中所得出的样本空间的情况,可知满足条件的情况只有两种,因此P(X=红球,Y=红球)=1/3。
如果两个随机变量相互之间是独立的,那么我们就可以得到如下结论:对任意的x∈X,y∈Y,有P(X=x, Y=y)=P(X=x)*P(Y=Y)。借用上面的例子,这一次变为有放回的抽取方式,再求第三问。由于第一次抽样的结果不会影响第二次抽样的时盒子中球的比例,因此可以将两个随机变量视为独立的,根据上述结论,可以求得P(X=红球,Y=红球)=(2/3)*(2/3)=4/9。现在使用传统的分析样本空间的方式来求这个问题,两次有放回抽样的所有可能情况为{红红,红红,红白,红红,红红,红白,白红,白红,白白},其中满足条件的样本点数来为四个,所以所求概率为4/9,这一结果与根据独立性所得出的结果是一致的。
(5)条件概率
条件概率指的是在某一个事件发生的基础之上,另一个事件发生的概率。条件概率的符号表达为P(Y=y1|X=x1),可解释为在随机变量X取x1的情况下,Y取y1的概率。笔者以为条件概率其实是根据这一条件对总的样本空间取了一个子集,然后在这一子集中再讨论另外一个事件发生的概率。还是以上述取球的题目为例子,现在添加一个问题:在第一次取出红球的情况下,第二次取出红球的概率。本题所要求的概率为P(Y=红球|X=红球),总的样本空间为{红白,红红,红白,红红,白红,白红},根据条件“X=红球“从总体的样本空间中划分出一个满足条件的子集为{红白,红红,红白,红红},其中第二次为红球的样本数为2,因此P(Y=红球|X=红球)=1/2。求解条件概率还可以使用条件概率的定义,即:如果P(X=x)≠0的话,P(Y=y|X=x)=P(Y=y, X=x)/P(X=x),读者们可以尝试一下应用定义计算的结果也是1/2。
(6)全概率公式
如果B1,B2,B3...是对样本空间S的一个划分,即B1,B2,B3...这些事件不为空,两两不相交,且B1∪B2∪B3∪...=S,那么对于事件A,有:
P(A)=P(A|B1)P(B1)+P(A|B2)P(B2)+P(A|B3)P(B3)...。
这个式子被称为全概率公式。结合条件概率的定义,该公式还可以变为:P(A)=P(A,B1)+P(A,B2)+P(A,B3)...。现在我们用全概率公式来求取球问题中的第二问。第一次取球的随机变量可取的值为:X=红球 或者 白球,可以将第一次取球视为对样本空间的一种划分,那么P(Y=红球)=P(X=红球,Y=红球)+P(X=白球,Y=红球)。其中P(X=红球,Y=红球)的答案在第三问中已经解答过了,为1/3。样本空间为{红白,红红,红白,红红,白红,白红},而第一次取白球,第二次取红球的样本点只有两个,因此P(X=白球,Y=红球)=1/3,所以P(Y=红球)=2/3。
(6)贝叶斯法则
贝叶斯法则在笔者看来,其实就是将条件概率与全概率公式组合在一起了。其定义如下:如果B1,B2,B3...是对样本空间S的一个划分,且P(A)>0,对任意的i,P(Bi)>0,则有P(Bi|A)=P(A|Bi)*P(Bi)/P(A)=P(A|Bi)*P(Bi)/∑P(A|Bi)。
三、最大似然估计
最大似然估计是统计推断的一部分内容,主要目的为通过有限的样本来估计整体的分布情况。接下来,先给出一个应用最大似然估计的例子,然后再说明更普遍意义上的最大似然估计。假设现在有一枚不均匀的硬币,由于硬币是不均匀的,所以其正反面出现的概率是不一样的,现在将硬币抛掷10次,其结果为{正,正,正,负,负,正,正,正,负,正},现在需要求抛掷该硬币所出现结果的概率分布。现在以随机变量Xi来代表第i次抛掷硬币可能出现的结果,依据我们的经验可知,抛掷一枚硬币的可能的结果只有正面和反面,因此可以假设Xi服从贝努利分布,即: P(Xi=正面; θ)=θ;P(Xi=反面; θ)=1-θ,θ>0 且 θ<1,并且每一次抛掷都互不相关。设x={X1=正,X2=正,X3=正,X4=负,...,X10=正},根据我们所假设的分布,十次实验要得到我们现有结果的可能性为:P(x)=θ7(1-θ)3,这个函数也被称为似然函数,可记为L(θ|x)。最大似然估计所需要求的θ值就是使得似然函数最大的θ值。以θ为自变量,绘制L(θ|x)函数的图像,如下图所示。我们可以用微积分的知识来求得θ=argmax(L(θ|x))。似然函数在一阶导数为0的位置取得最值,似然函数对参数θ的导数为:7*θ6(1-θ)3-3*θ7(1-θ)2=0,解得θ=0.7。
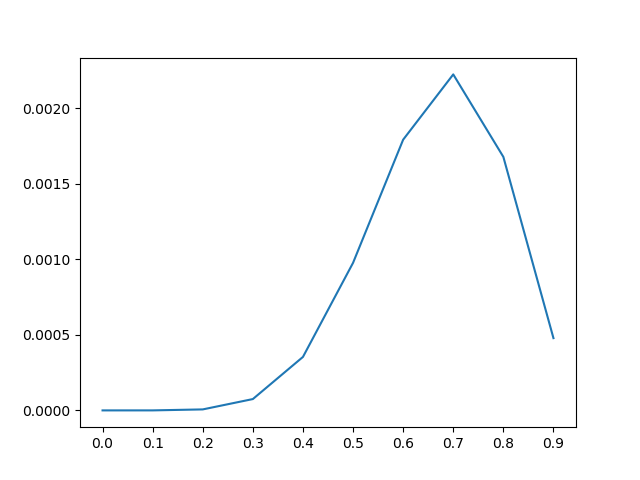
下面摘录一段对最大似然估计的概括性描述[3]:
假设X1,X2,X3,...Xn是n个独立同分布(两两之间相互独立,并且都服从统一概率分布)的随机变量,所服从的概率分布为f(Xi;θ),i=1,2,...,n,以θ作为概率分布的参数。现在假设x1, x2,..., xn,是上述n个随机变量所取的值,设x=(x1, x2,..., xn)。似然函数为L(θ|x)=∏f(xi;θ),i=1,2,...,n,使得似然函数最大的θ被称之为θ的最大似然估计。
对于所假设的分布是贝努利分布的最大似然估计而言,在计算最大似然估计的时候可以对似然函数取自然底数的对数,设t为n个样本中为正例数量,得到:In(L(θ|x))=t*In(θ)+(n-t)*In(1-θ),通过求导,可以得到一般结论即其最大似然估计为:θ=t/n。
四、最大后验估计
在最大似然估计中,我们将概率分布的参数视为一个固定的常数值,然而在最大后验估计中,该参数也被视为一个随机变量。以最大似然估计中所说的硬币为例,不同于在最大似然估计中所假设的第i次抛掷的结果是随机变量Xi,在θ为随机变量的情况下,第i次抛掷的结果变为服从在θ取某一个值的条件下的条件概率分布。依旧假设该条件概率分布服从贝努利分布:P(Xi=正面|θ)=θ;P(Xi=反面|θ)=1-θ,θ>0 且 θ<1,并且假设每次抛掷的结果是以θ为条件相互独立的,设硬币为正面的概率θ服从分布:P(θ)。在现有样本所出现结果的情况下,θ取某个值的概率为:P(θ|x),使得这个概率最大的θ就是所需要求的。根据条件概率公式可得:P(θ|x)=P(x, θ)/P(x)=P(x|θ)*P(θ)/P(x),其中P(x)为抛掷结果在不考虑θ的情况下的先验概率。由于P(x)和θ无关,在计算最大后验估计的时候可以不考虑,因此所要求的结果为:θ=argmax P(x|θ)*P(θ)。现在假设P(θ)为μ为0.5,σ为0.1的正态分布,即:10/√2π*exp(-50(θ-0.5)2)。P(x|θ)*P(θ)=P(X1=正|θ)*P(X2=正|θ)*P(X3=正|θ)*...*P(X10=正|θ)*P(θ)=θ7(1-θ)3*10/√2π*exp(-50(θ-0.5)2),应用类似于最大似然估计中的求最值的方法,可以得到最终的θ的值。
五、朴素贝叶斯算法
下面的内容会通过一个案例来介绍朴素贝叶斯算法在分类中的应用,该样例摘自参考文献4。
现有如下样本:

求样本{2,S}属于某一类别的概率?
将特征1视作视为随机变量X1,取值范围为{1,2,3};将特征2视为随机变量X2,取值范围为{S,M,L};类别视为随机变量Y,取值范围为{-1,1}。根据题意,可知所需要求概率为P(Y=-1|X1=2,X2=S)及P(Y=1|X1=2,X2=S),下面我们来求第一个概率,第二个概率的求法与第一个是一样。
根据条件概率公式,上述概率可转化为:P(Y=-1|X1=2,X2=S)= P(X1=2,X2=S|Y=-1)*P(Y=-1)/P(X1=2,X2=S)。在应用朴素贝叶斯方法的时候,有一个很重要的假设,那就是条件独立假设:在表示类别特征的随机变量取某个值的条件下,表示各个特征的随机变量是相互独立的。于是就有:
P(Y=-1|X1=2,X2=S)= P(X1=2,X2=S|Y=-1)*P(Y=-1)/P(X1=2,X2=S)=P(X1=2|Y=-1)*P(X2=S|Y=-1)*P(Y=-1)/P(X1=2,X2=S)。(1)
我们可以将类别作为条件,对总体的样本空间进行一次完备划分,根据全概率公式和条件独立假设,可将等式(1)中的分母转为:
P(X1=2,X2=S)=P(X1=2,X2=S|Y=-1)*P(Y=-1)+P(X1=2,X2=S|Y=1)*P(Y=1)=P(X1=2|Y=-1)*P(X2=S|Y=-1)*P(Y=-1)+P(X1=2|Y=1)*P(X2=S|Y=1)*P(Y=1)。 (2)
接下来我们只需要求出:P(X1=2|Y=-1),P(X2=S|Y=-1),P(Y=-1),P(Y=1),P(X1=2|Y=1),P(X2=S|Y=1)。
直觉上,我们会通过计算现有样本中所有符合条件的样本所占的比例来计算上述六个概率值,虽然最后得到的结果是对的,但是李航老师在[4]中提到了使用最大似然估计来求解上面这四个概率的方法,具体读者可以参考该书所对应的的内容。笔者以为书上的结论,是基于P(X1|Y),P(X2|Y),P(Y)这三个分布是贝努利分布这一假设得来的。接下来直接使用该结论,计算上述四个概率值。
P(X1=2|Y=-1)可理解为:当类别为-1的样本时,X1为2的可能性,结果为:P(X1=2|Y=-1)=2/6;同理,P(X1=2|Y=1)=3/9
P(X2=S|Y=-1)可理解为:当类别为-1的样本时,X2为S的可能性,结果为:P(X2=S|Y=-1)=3/6;同理,P(X1=S|Y=1)=1/9
P(Y=-1)可理解为:样本为-1类的概率,结果为:P(Y=-1)=6/15;
P(Y=1)可理解为:样本为1类的概率,结果为:P(Y=1)=9/15;
最终得到:P(Y=-1|X1=2,X2=S)=3/4。
以上就是笔者对最大似然估计、最大后验概率及贝叶斯分类的一个简单总结。笔者水平有限,有错误的地方还请各位读者批评指正。
六、参考文献
[1]概率论与数理统计(第四版),浙江大学;
[2]https://baike.baidu.com/item/%E8%BF%9E%E7%BB%AD%E5%9E%8B%E9%9A%8F%E6%9C%BA%E5%8F%98%E9%87%8F;
[3]《Introduction to Probability and Statistical Inference》 by George Roussas;
[4]《统计学习方法》,李航著。