神经网络学习笔记(2)
本文是神经网络学习笔记的第二部分,紧接着笔者的神经网络学习笔记(1),主要内容为对总结神经网络的常用配置方式,包括如下几点:(1)数据预处理;(2)权重初始化;(3)正则化与Dropout;(4)损失函数。
1、数据预处理
对于神经网络而言,数据的预处理常见的方法主要包括0-1归一化,主成分分析(PCA)及one-hot编码标签。
(1)0-1归一化:将样本所有维度的数据转变为以0为均值,1为标准差的新数据。处理方式为,对训练数据的每一个维度,分别计算其均值和标准差,然后将这一维度的数据分别减去均值然后除以标准差。至于为什么需要对数据进行这一处理,笔者也没有找到很好的解答,欢迎各位大牛在本文下面留言探讨;
注意:当我们在进行归一化处理的时候,我们处理所用的数值(例如:均值和方差)只能够从训练集上面获得,然后将从训练集上计算得到的值直接应用到验证集/测试集上,而不是在验证集/测试集上面重新计算新值,或者直接从整体的数据集上面计算均值和方差然后再划分数据集。我想这还是为了保证模型泛化能力检测的公正性,避免验证集/测试集中的任何数据泄露到训练过程中。
(2)主成分分析(PCA):对于神经网络而言,该方法主要用于对数据进行降维(也可用于数据的压缩)。网络上面已经有很多文章对PCA的基本过程进行解读,但是笔者觉得这些文章还是存在很多不严谨的地方,因此向各位读者推荐这一链接中对PCA的讲解。概括来说,该文中将PCA归结为求解一个矩阵,该矩阵能够对原始数据进行降维,同时利用这一矩阵又能够将降维后的数据最大化地还原回来,因此可将对这一矩阵的求解转化为一个优化问题,最后应用基本的线性代数知识就能得到了PCA的基本运算过程。
(3)one-hot编码:在进行多分类任务的时候,例如要将一个有十个维度的样本分到5个类别中,我们所得到的样本数据可能会是这样的:特征:[x1,x2,x3,x4,x5,x6,x7,x8,x9,x10],标记:[y],y属于{0,1,2,3,4},其中用0到4这5个数字来表示五种不同的类别。在应用神经网络完成这一分类任务的时候,我们往往会在输出层设置5个节点,每一个节点都与一个类别相对应。因此在进行模型训练的时候,为了保证标记与实际输出的数据之间的对应,我们需要将训练样本的标记转为one-hot编码的格式。上例中假如有一个样本被标记为“4”,那么转为one-hot编码就是[0,0,0,0,1]。在keras库中有一个函数“to_categorical”可以很方便地将标记转为one-hot格式。
2、权重初始化
我们知道在进行优化的过程中,对参数的初始化会影响最后的初始化结果,同样对神经网络参数的初始化也很重要,下面将介绍在神经网络应用的过程中常用的权重初始化方式和应该避免的错误方式。(下述内容主要摘自CS231n课程)
(1)小随机数
在初始化神经网络权重的时候,常见的做法是将神经元的权重初始化为非常小的随机数,这一过程被称之为“打破对称”。这样操作的原因是,如果神经元的权重一开始都是随机的并且不同的话,它们就会计算出不同的梯度,并且成为一个整体神经网络的多样组成部分。这一操作应用numpy的实现方法为:W=0.01*np.random.randn(D, H)。需要强调的一点是,并非越小的值就越好,因为如果权重值过小,那么在反向传播的过程中,每一个参数就只能够得到非常小的更新。
注意:不要将权重全部都设置为0。这会导致每一个神经元都计算出相同的输出,以至于在反向传播的过程中会对每一个参数计算出相同的权重值,结果就会导致同样的权重更新。换句话说,如果权重都初始化为同样的数的话,神经网络就没有了“非对称源”。
(2)偏置初始化
常见的偏置初始化方式是将偏置都设置为0,因为“打破对称”已经由权重初始化完成了。对于以ReLU作为非线性函数的神经元而言,有些人喜欢将偏置初始化为一个很小的常数,例如:0.01,因为这样能够确保神经元从一开始就能够有非0输出,也就能够从一开始就更新权重。然而还不清楚这种做法是否能够提供稳定的表现提升,我们一般更常用的方式是将偏置都设置为0.
(3)Batch Normalization
这一种技术是2015年被Ioffe和Szegedy所提出来的,在论文中对该技术有很详细的解读,在此仅仅对该技术做一个基本的解读。其基本过程为,在进行mini-Batch梯度下降训练的过程中,一次训练的过程就包含m个样本的数据。某个神经元对应的原始的线性激活x通过减去mini-Batch内m个实例的线性激活的均值E(x)并除以m个实例的线性激活的方差Var(x)来进行转换,表达如下式。很多的深度学习库已经提供了Batch Normalization的实现,例如:keras的BatchNormalization层。在实践中,Batch Normalization对于较差的初始化有着很强的鲁棒性,并且这一技术有助于提升神经网络的训练速度。

3、正则化与Dropout
下面将要介绍在神经网络中常用的可以有效避免过拟合问题的方法,即:正则化与Dropout
(1)正则化
L2正则化:该方法通过在最后的损失函数中添加一个惩罚项,即所有参数的平方,来避免过拟合。用公式表达就是在损失函数中添加一项1/2*λ*||W||2,其中λ是正则化系数,用来控制惩罚力度的大小。直觉上来说,这种正则化的方式倾向于惩罚过大或者过小的参数值。
L1正则化:该方法在损失函数中添加的惩罚项为,参数的绝对值,即1/2*λ*|W|。这一惩罚措施,导致模型会更偏爱接近于0的参数。
Max norm constraints(最大范数限制):直接对参数添加限制条件,如:||W||2<C,其中C为某个常数,典型的值为3或者4。
需要指出的是,我们很少对网络的偏置做正则化,虽然在实践中正则化偏置很少会导致更差的结果。
(2)Dropout
这是近些年来所提出来非常有效的避免过拟合问题的方法,源自于Srivastava et al的论文。简单来说,该方法基本思路为在训练的过程中以一定的概率p(一个超参数)来选择保留神经元的输出,或者直接将输出设定为0。如下图所示,Dropout可以被解释为,在训练过程中,对一个较大的全连接网络中的神经元抽取一个较小的网络进行训练。在测试阶段则不使用dropout,这样整体网络所得到的结果可解释多个采样网络的平均预测值。
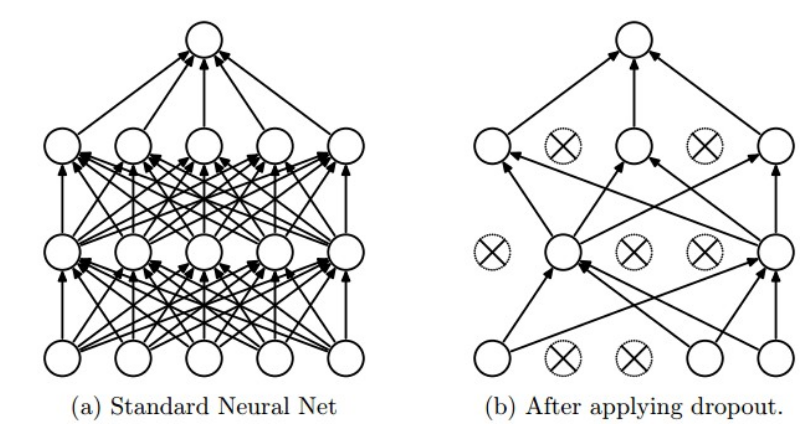
4、损失函数
损失函数用来衡量模型预测值与标记值之间的误差,一个数据集整体的损失就是所有样本的误差均值。根据所需要执行的任务的不同可以选择不同的的损失函数,在此主要介绍:(1)二分类问题;(2)多分类问题;(3)回归问题,这三类问题常用的损失函数。
(1)二分类
hinge loss(铰链误差):每一个样本的标记为要不为-1,要不为1,其表达式为:L=max(0, 1-y*l),其中y为预测值,l为标记值。直观上来看,如果预测值和标记值一致(同为-1或者1),那么函数就取小值0;而如果不一致,就会取较大值2,这样就会导致误差的增大。
binary cross-entropy loss(二分类交叉熵):用于以单个输出节点来预测分类问题,最后的输出范围在[0,1]之间。对这种模型,在最后预测的时候,会根据某个阈值来划分预测结果,例如:如果输出值大于阈值为0.5,那么预测类别为0,否则为1。该损失函数的表达式为:L=-l*log(y),其中l为标记值,y为模型输出值。简单理解一下,如果预测结果和标记是相当的话,例如:预测值为0.8,标记为1,那么该损失函数的值就会非常小;而如果不相当的话,例如,在标记为1的时候预测值为0.1,那么该损失函数就会非常大。
(2)多分类问题
该问题指的是将样本划分到两个以上的类别当中,典型的如Minist数据库,cifar-10数据库分类都属于这种类型。对于这种问题,在神经网络的最后会使用softmax层将最终的结果压缩到[0,1]范围内,这一做法可以解释为使得输出节点的输出值直接对应于样本属于某个类别的可能性大小。多分类问题的交叉熵表达式为:L=-l*log(y)-(1-l)*log(1-y)。
(3)回归问题
回归问题的本质在于拟合数据,使得模型预测的实数值与标记值之间的差距最小。对于这一类问题,常用的损失函数就是模型输出与标记之间的L2范数和L1范数,范数的概念可以参考这一篇文章。