数据组织主要从以下二方面着手
逻辑设计:文档、类型、索引
物理设计:节点、分片
倒排索引
前言
逻辑设计:我们把elasticsearch与关系型数据库做个客观对比
| Relational DB | Elasticsearch |
| 数据库(database) | 索引(indices) |
| 表(tables) | 类型(types) |
| 行(rows) | 文档(documents) |
| 字段(columns) | 字段(fields) |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引可以包含多个类型(表),每个类型可以包含多个文档(行),每个文档可以包含多个字段(列)。
注意:在之前版本中每个文档存储在一个索引中,并分配多个映射类型,映射类型用来表示被索引的文档或者实体的类型,这也带来一个问题(),导致后来版本6.0.0中一个文档只能包含一个映射类型,7.0.0中映射类型被弃用,到8.0.0中完全被删除。
逻辑设计:文档、类型、索引
文档属性
elasticsearch是面向文档操作,也就是最小单位就是文档
自我包含:一篇文档同时包含字段和对应的值 key:vaule形式
可以是层次型的:一个文档中包含自文档
灵活的结构:在关系型数据库中都要预先设计表才能对其操作,而elasticsearch中,有时候可以忽略某个字段或者动态的去添加一个字段(但是这样可能导致脏数据的出现,我们可以预定字段,之后不再改变字段)
无模式:字段对应值得类型可以是不限类型的
类型
文档的逻辑容器,就像关系型数据库一样,表格是行的容器
类型中对于字段的定义称为映射,比如name映射为字符串类型
索引
索引是映射类型的容器,索引是非常大的文档集合,它们都存在各个分片上
物理设计:节点和分片
节点
一个集群至少包含一个节点,而一个节点就是一个elasticsearch进程。节点内可以有多个索引。
默认的,如果你创建一个索引,那么这个索引将会有5个分片(primary shard,又称主分片)构成,而每个分片又有一个副本(replica shard,又称复制分片),这样,就有了10个分片。
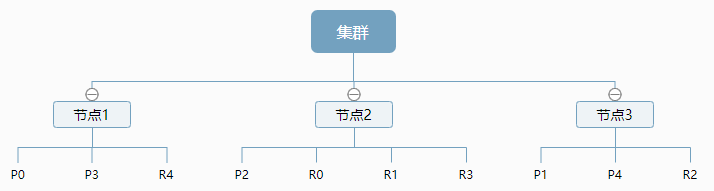
上图我们可以看到是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
1 Study every day, good good up to forever # 文档1包含的内容 2 To forever, study every day, good good up # 文档2包含的内容
| term | doc_1 | doc_2 |
| Study | √ | × |
| To | × | √ |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | × |
| up | √ | √ |
若我们搜索 to forever包含每个词条的文档
| term | doc_1 | doc_2 |
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
elasticsearch的索引和Lucene的索引对比
elasticsearch将索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。