古时候,人们是如何来传递消息的?
当年周幽王为博褒妃一笑,不顾众臣反对,竟数次无故点燃边关告急用的烽火台,使各路诸侯,长途跋涉,匆忙赶去救驾。
结果,被戏而回。
周幽王从此便失信于诸侯,最后,当边关真的告急之时,他点燃烽火却再也没人赶来救他了!
不久,便死于刀下,亡了西周。
西周第九代国君是周厉王,贪财好色,昏庸残暴,激起了公元前841年的“国人(平民)暴动”。
周朝从此衰落下去,社会动荡不安。
扯远了,我们说有城池A和城池B,城池B为前线,当城池B受到攻击的时候,需要城池A派来援兵。
这个时候城池B点着了防火台,如果只有一个烽火台,那么只有点着火和没点火两种状态。
无法准确表示攻击城池B的军队数量,这个时候,有人想到了一种表示方法。
我每一座烽火台都可以表示两种状态,点火和未点火,分别用0和1来表示。
![]()
0 1
那两座烽火台呢?
![]()
![]()
00 01
10 11
没有烽火台被点着火的时候,表示没有敌人,只点着第一座烽火台的时候,表示来了一个敌人,只点着第二座烽火台的时候,表示来了2个敌人。
当两座烽火台都被点着的时候,就表示来了3个人。表示数字 0-3。
如果有三座烽火台呢?
![]()
![]()
![]()
000 001 010 011
100 101 110 111
三座烽火台的时候表示了8中状态。 表述数字0 -7
如果有四座烽火台呢
![]()
![]()
![]()
![]()
0000 0001 0010 0011 0100 0101 0110 0111
1000 1001 1010 1011 1100 1101 1110 1111
以此类推:
当有8座烽火台的时候,最大可以表示多少?
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
0 1 2 3 4 5 6 7
1 2 4 8 16 32 64 128
如果敌人来了130个人,如何表示呢?
150人又如何表示?
咱们平时用的进制是10进制。在计算机中,还有另外两种进制八进制和十六进制
十进制: 逢十进一
表示数字: 0123456789
二进制:逢二进一
表示数字: 0 1
八进制: 逢八进一
01234567
作用: 在某些编程语言里提供了使用八进制符号来表示数字的能力,而且还是有一些比较古老的Unix应用在使用八进制。
和二进制之间的转换:
2-->8 : 取三合一 8-->2 : 取一分三
十六进制: 逢十六进一
表示数字: 01234567ABCDEF
二进制使用起来很不方便, 16进制或8进制可以解决这个问题。
因为,进制越大,数的表达长度也就越短。
不过,为什么偏偏是16或8进制,而不其它的?2、8、16,分别是2的1次方、3次方、4次方。
这一点使得三种进制之间可以非常直接地互相转换。
8进制或16进制缩短了二进制数,但保持了二进制数的表达特点。
计算机中的单位:
位 bit (比特)(Binary Digits):存放一位二进制数,即 0 或 1,最小的存储单位。
字节 byte:8个二进制位为一个字节(B),最常用的单位。
1B(bytes) = 8bit
1KB (Kilobyte 千字节)=1024B,
1MB (Megabyte 兆字节 简称“兆”)=1024KB,
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,
1TB(Trillionbyte 万亿字节 太字节)=1024GB,
1PB(Petabyte 千万亿字节 拍字节)=1024TB,
1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB,
1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
1BB (Brontobyte 一千亿亿亿字节)= 1024 YB
硬盘空间少比买的时候要少?
是因为 换算时他们将 1024 按照 1000来算
256G的硬盘: 256G= ? Bytes:按1000来算
256G 硬盘
1K = 1000B
1M = 1000K
1G = 1000M = 1000*1000*1000B =1000000000B
256G = 256000000000B
256000000000/1024/1024/1024 B = 238.4185791015625 G
500GB*1000*1000*1000/1024/1024/1024=465.66
百兆宽带,下载速度只能达到十多兆。
宽带运营商按照二进制来计算,所以要100M的宽带要除8才是下载的速度。
32位和64位 /31bit和64bit的区别
1. 对操作系统来说,64位和32位指最大内存寻址空间,32位最大4GB(2^32),64位理论上16EB(2^64),但现在一般都是2^48
2、对硬件来说,64位和32位指数据宽度,64位一次取8字节y也就是64bit,32取4字节也就是32bit,所以理论上64位比32位性能提高了一倍。
实际上的情况是,达不到,内存变大了,需要寻址更多。
3、对应用程序来说,应用程序基于操作系统 和硬件,其使用的指令宽度随系统和硬件变化。
32位和64位区别的最常见表现就是64万位操作系统可以支持4G以上的内存。缺点也是内存占用,64位代码比32位代码多占用空间,
现在来看64位操作系统兼容32位软件。反之则不行。
32位和64位最本质的区别是CPU来决定的,操作系统的位数是是看最大能把CPU的性能发挥到多高。我们现在在市面上见到的CPU都是64位的,32位的CPU已经是老古董了。
二进制的编码
计算机内部是由集成电路这种电子部件构成的,电路只可以表示两种状态——通电、断电
因为这个特性,计算机内部只能处理二进制。那为什么我们能在计算机上看到字母和特殊字符呢?
如果我们用一个二进制数字表示一个字符,比如说用“0100 0001”来表示A。
根据这个对应关系,我们制作一个表格,这个表格里一个二进制数字对应一个字符。

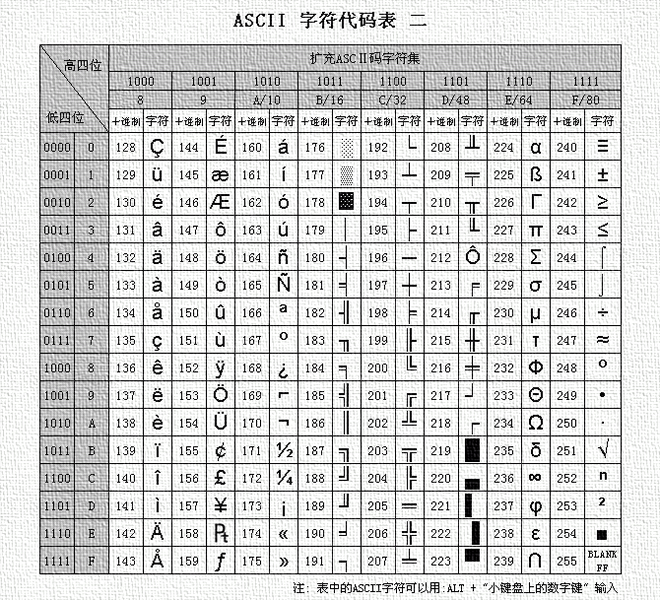
这就是编码。
这套编码叫ASCII(美国(国家)信息交换标准(代)码),使用7个或8个二进制位进行编码的方案,最多可以给256个字符。
使用了ASCII码,不同的计算机之间就可以实现数据的标准化。
但是ASCII使用的时候有一些限制。
他最多之可以表示256个字符。
如果有其他的字符就无能为力了。
ASCII只能表示26个基本的拉丁字母、阿拉伯数字和英式标点。
因此也只能用于显示现代美国英语。
后来计算机世界开始有了其他语言,ASCII码已经无法满足需求。
后来不同语言的人各自为自己定制了一套属于自己的编码,同时与ASCII保持兼容。
这些编码统称MBCS,到了这里大家都开始好似用双字节。
(中国的叫GB*,比如GBK)。
在后来有人开始觉得,这么多编码,有些编码之间还不兼容,太让人头大了,于是有这么一群人就坐在一起想出了一个办法:所有的语言都使用同一种编码,这种编码就是Unicode。
Unicode使用最少2个字节(1个字节=1BYTE=8bit=一个长度为8的二进制数) 来表示字母和符号等,有时候是4个字节。
这样就解决了上面遇到的问题。
Unicode又叫万国码,是业界的一种标准。
但是有人又觉得如果我要表示一个ASCII里的字符,使用unicode来表示不是太浪费空间了吗,于是就有人想出了另外一种解决方案——UTF-8。
UTF-8是对Unicode编码的压缩和优化,最大的特点是它采用了变长的编码方式,他不再是最少使用2个字节,而是将所有的字符进行分类。
ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存…
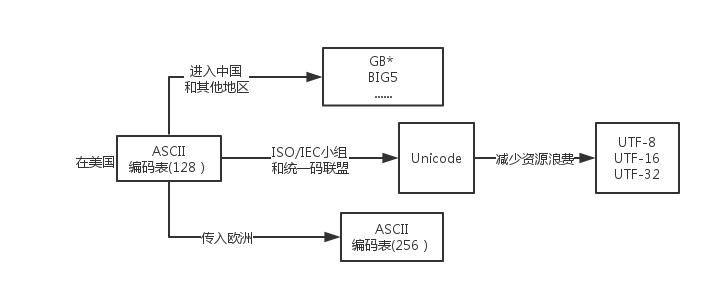
GB2312是1980年国家制定的汉字内码规范,收录了6千多汉字及符号,表示的符号有限 ;国家标准化委员会又制定了GB13000,GB13000制定的原则与GB2312不同,GB13000以国际化为目标, 该标准编码参照了Unicode 2.0 标准编码,与GB2312完全不兼容,因早期的计算机中的汉卡采用了GB2312,无法顺利向GB13000过渡,所以GB13000变成了一个纸面上的 标准,无法推广-;有了这个经验之后,国家标准化委员会制定了GBK标准,他兼容GB2312标准,同时在GB2312标准的基础上扩展了GB13000包含的字。