一、GIL定义
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once.
在CPython中,全局解释器锁(global interpreter lock,GIL)是一个互斥锁,它防止多个本机线程同时执行Python字节码。
This lock is necessary mainly because CPython’s memory management is not thread-safe.
这个锁是必要的,主要是因为CPython的内存管理不是线程安全的。
(However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
(然而,由于GIL存在,其他特征已经发展成依赖于它所实施的保证。)
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。
就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。
有名的编译器例如GCC,INTEL C++,Visual C++等。
Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。
像其中的JPython就没有GIL。
然而因为CPython是大部分环境下默认的Python执行环境,所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。
所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
二、GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。
在一个python的进程内,不仅有该进程的主线程和由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程。
总之,所有线程都运行在这一个进程内,所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(主进程的所有代码以及Cpython解释器的所有代码)。

所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先要能够访问到解释器的代码。
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码。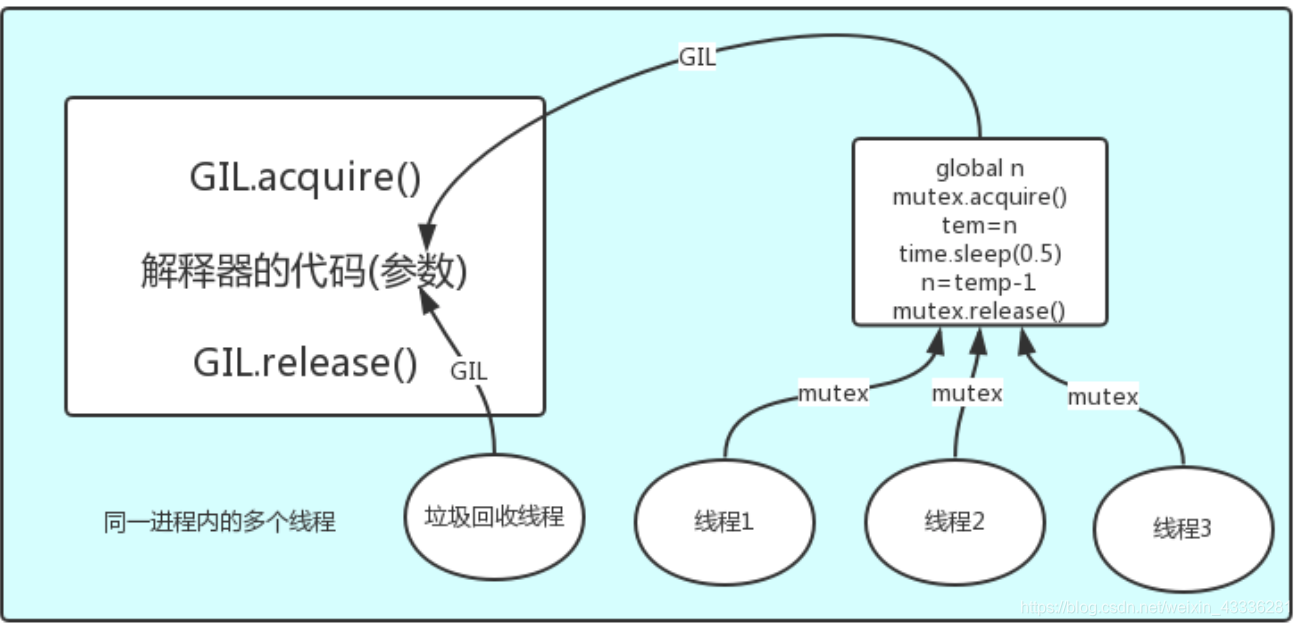
三、GIL和Lock
现在你可能想,既然已经有GIL了,同一时间只能有一个线程执行,那我还自己加锁干啥?
首先,我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock,如下图,按照数字顺序看:
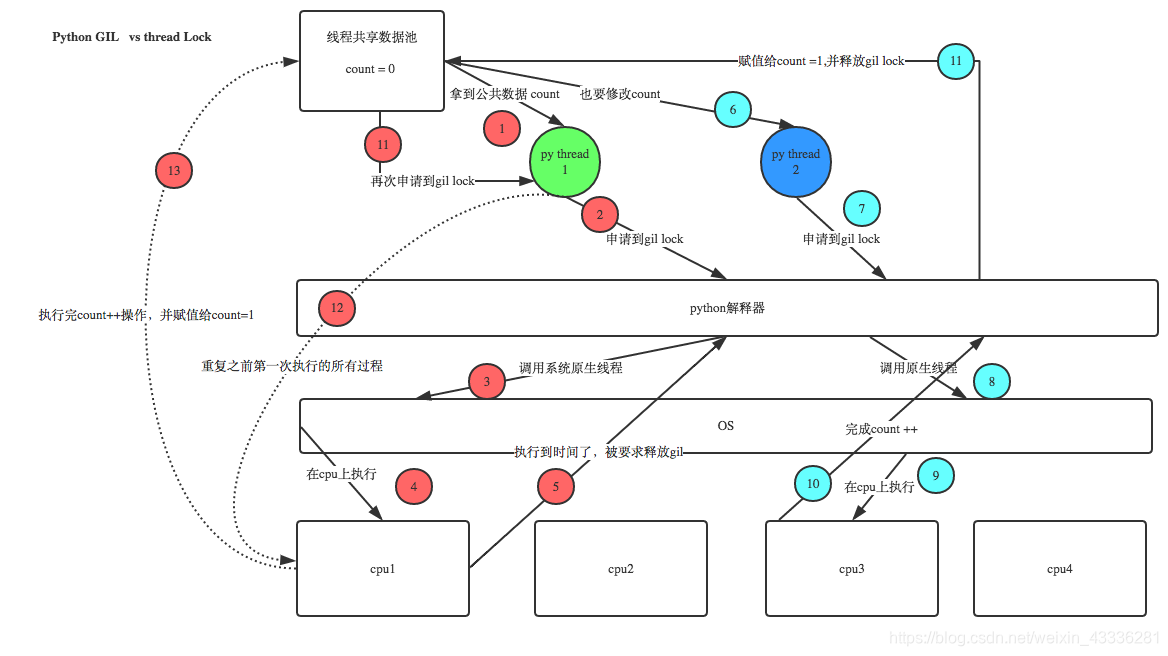
分析:
1、100个线程去抢GIL锁,即抢执行权限
2、肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
3、极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
4、直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
来看一个例子:
import time
from threading import Lock
from threading import Thread
number = 100
def task():
global number
mutex.acquire()
temp = number
time.sleep(0.1)
number = temp - 10
mutex.release()
if __name__ == '__main__':
mutex = Lock()
thread_list = []
for i in range(10):
thread = Thread(target=task)
thread_list.append(thread)
thread.start()
for thread in thread_list:
thread.join()
print("After thread number = ", number)
首先我们开启十个线程,每个线程的任务是将number-10,但是在相减操作前会先睡0.1秒,这0.1秒就是精妙所在,来一点一点分析:
开启第一个线程,假设叫线程1,因为是第一个开启的,所以会率先拿到mutex锁并上锁,然后继续往下执行。
在线程1沉睡0.1秒的时间内,剩余的九个线程也都开启了,但是因为没有拿到mutex锁,所以九个线程都被阻塞在mutex.acquire()这一行。
线程1沉睡完之后,释放mutex锁,此时线程2到线程10都开始抢mutex锁,只有一个能抢到,这时就会循环线程1的遭遇,number-10的操作就相当于串行,所以最后的输出结果为:
After thread number = 0
如果说没有锁的话:
import time
from threading import Lock
from threading import Thread
number = 100
def task():
global number
# mutex.acquire()
temp = number
time.sleep(0.1)
number = temp - 10
# mutex.release()
if __name__ == '__main__':
mutex = Lock()
thread_list = []
for i in range(10):
thread = Thread(target=task)
thread_list.append(thread)
thread.start()
for thread in thread_list:
thread.join()
print("After thread number = ", number)
开启第一个线程,假设叫线程1,因为是第一个开启的,率先走到sleep(0.1),此后的九个线程也都被阻塞在这一行,此时,十个线程拿到的temp都是100,沉睡完之后执行下一步number=100-10=90,所以最后的输出结果为:
After thread number = 90
所以、所以、所以,重点来了GIL保护的是解释器的数据,并不是自己的共享数据。
四、GIL与多线程
有了GIL的存在,同一时刻同一个进程中只有一个线程被执行。
那这老子就不干了,进程可以利用多核优势,但是开销太大了,线程虽然开销小,但是又不能利用多核优势,还学个屁的并发编程。
别急啊,既然讲了就肯定有用,再继续讲之前,先搞明白一个问题:CPU到底是用来做计算的还是用来做IO的?
显然,CPU是运算器,当然是做计算的,那么多个CPU意味着可以有多个核并行完成计算,所以多核提升的计算性能。
当CPU遇到IO操作时会阻塞,仍然需要等待,所以多核对IO操作没有什么卵用。
所以,对于计算来说,CPU越多越好,但是对于IO来说,再多的CPU也没用。
当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地。
假设我们有四个人物需要并发进行,有两种解决方案:
1.开启四个进程
2.一个进程开启四个线程
| 单核 | 多核 | |
|---|---|---|
| 计算密集型 | 没有多核并行计算,方案1还徒增创建进程的开销,方案2获胜 | 领用多核优势计算,方案1获胜 |
| IO密集型 | 进程的切换远不如线程,方案2获胜 | 再多核也没法解决IO问题,方案2获胜 |
结论:
现在的计算机基本上都是多核,python对于计算密集型的任务开多线程的效率并不能带来多大性能上的提升,甚至不如串行(没有大量切换),但是,对于IO密集型的任务效率还是有显著提升的。
五、多进程与多线程性能测试
如果并发的多个任务是计算密集型:多进程效率高。
import os
import time
from threading import Thread
from multiprocessing import Process
def work():
res = 0
for item in range(10000000):
res *= item
if __name__ == '__main__':
print("CPU counts =", os.cpu_count())
processes = []
start = time.time()
for i in range(os.cpu_count()):
process = Process(target=work)
processes.append(process)
process.start()
for process in processes:
process.join()
stop = time.time()
print('Process run time is %s' % (stop - start))
threads = []
start = time.time()
for i in range(os.cpu_count()):
thread = Thread(target=work)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
stop = time.time()
print('Thread run time is %s' % (stop - start))
输出结果为:
CPU counts = 8
Process run time is 1.1259636878967285
Thread run time is 4.476061105728149
如果并发的多个任务是I/O密集型:多线程效率高。
import os
import time
from threading import Thread
from multiprocessing import Process
def work():
time.sleep(3) # 模拟IO操作
if __name__ == '__main__':
print("CPU counts =", os.cpu_count())
processes = []
start = time.time()
for i in range(os.cpu_count()):
process = Process(target=work)
processes.append(process)
process.start()
for process in processes:
process.join()
stop = time.time()
print('Process run time is %s' % (stop - start))
threads = []
start = time.time()
for i in range(os.cpu_count()):
thread = Thread(target=work)
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
stop = time.time()
print('Thread run time is %s' % (stop - start))
输出结果为:
CPU counts = 8
Process run time is 3.1772778034210205
Thread run time is 3.0032496452331543