一、ArrayList
1、ArrayList构造函数

1.1如果指定了容量大小,创建该大小的数组
1.2如果没有指定大小,默认创建空数组
1.3如果是指定小于0的大小,抛出异常
无参构造:创建空数组,在添加第一个元素时候才会扩容到10的容量。

!只有在jdk6中会一开始就创建一个数组大小为10的数组。
2、添加元素是添加在数组末尾。(先确保数组容量)

第一次加入元素,才会扩容为10.
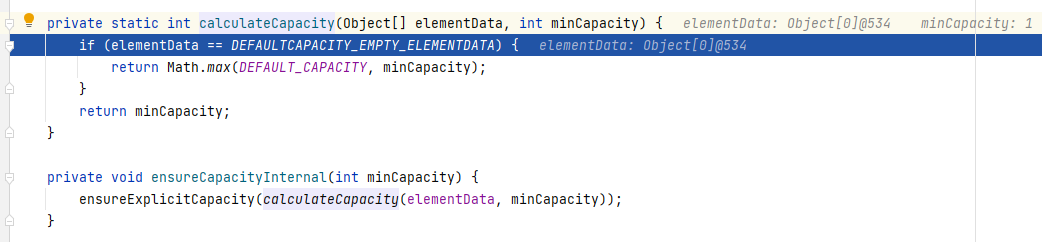
3、ensureExplicitCapacity判断是否需要扩容。

4、grow()方法
得到旧容量,将旧容量扩大1.5倍(大约)。
比如说原始大小是oldCapacity=7,7+7>>1=7+3=10.

如果扩容后的容量还不够,就用需要的容量当做最新的容量。
补充:
数组是length。
字符串是length()。
泛型集合是size()。
二、HashMap
主要存放键值对,是非线程安全的
key和value都可以存储空值,只能存一个空值key和多个空值value。
HashmapJDK1.8以前是数组+链表结合使用。1.8会在扩容机制变化后,演变为红黑树。
1、JDK1.8hashMap的hash方法源码:
JDK7中的hash算法全是取余。

JDK取得了hashcode,还会右移,为了加入扰动,降低hash冲突
2、loadFactory加载因子是控制数组存放疏密程度。
越趋近于1,越容易冲突。
给定的负载因子是0.75是官方给定的。
初始容量是16,当加入到12时,会进行扩容。
扩容会涉及到rehash、复制数据等操作。
(这个地方发现put中调用的putValue方法,这个是default权限的方法,访问权限是本包类中,除开本包类就变成了private权限)
Hashmap默认是没有大小,只会第一次使用put->putVal中的resize才会初始化。一开始new HashMap();
putVal()方法流程:
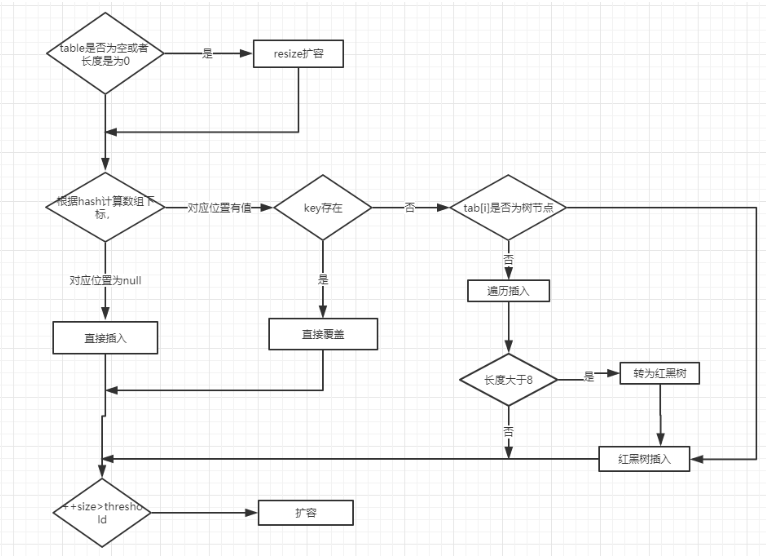
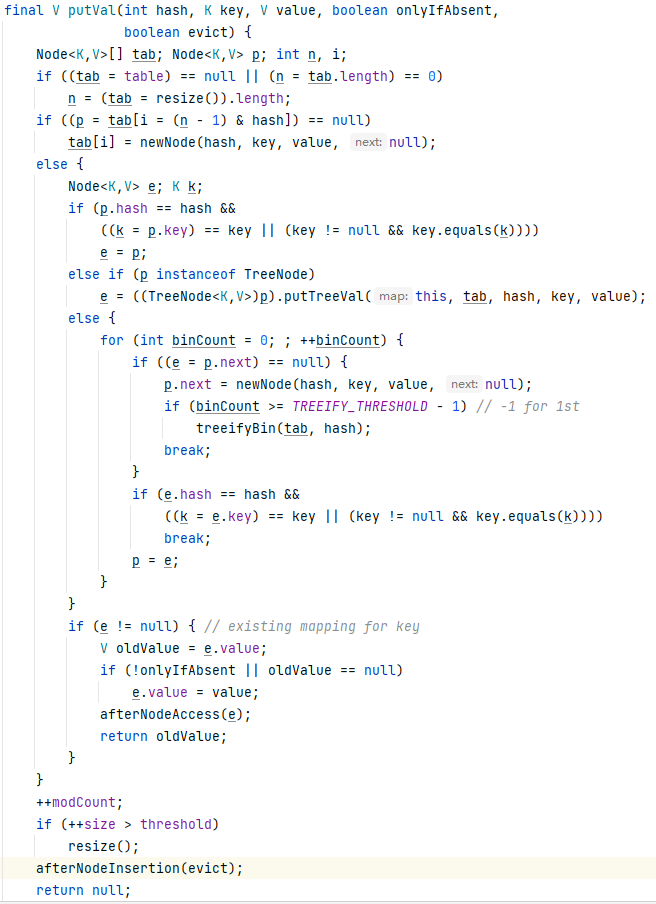
1、当前如果table是第一次使用,如果table是null,resize(),这个时候才会第一次分配默认的16个空间给它
2、判断判断当前数组下标((n-1)&hash)对应是否为null,如果为null直接插入
3
3.1、判断当前是否存在冲突,并且key相等,相等直接替换。
3.2、判断当前是否是红黑树的子类,直接插入。
3.3、遍历链表,如果找到尾节点直接进行插入,插入后检测,是否treebin化,如果链表大于8,并且数组长度大于64红黑树化,否则进行数组扩容,数组扩容(产生一个两倍的新数组,按照尾插重新插入到数组中)。遍历过程中发现了相等的key直接替换
并且return 返回oldValue。hashmap中
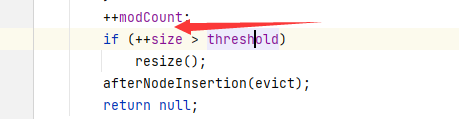
4、++modCount更改次数用在了迭代器快速判断失败
5、++size如果当前size大于阈值,扩容。
jdk8的扩容操作:产生一个二倍新数组,利用尾插法,依次rehash到新的数组中,并且rehash产生的下标位置,只会在当前位置,或者是老位置下标+扩容值。
功劳源于下面:
问题:为什么hashmap长度是2的幂次方
Hash值范围Integer.Max -2147483648到2147483647但是内存装不下。
数组下标的计算方法是当前hash&(n-1)。 hash计算是
(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
优点:
1、(n-1)的目的是因为2的n次方是 1000....0000,这种二进制数,减掉1过后是1111...1111这样可以降低hash冲突,并且降低空间浪费。
如果是其他数可能会造成某些数组空间永远存不上值。
例子5的二进制 00000000 00000000 00000000 00000101
发现任何一个数&上5,倒数第二低位永远是0,
2、在求数组下标的时候,本身就应该对数组长度求余,但是,取余运算会更快,key.hashcode%arr.length==key.hashcode&(arr.length-1) 只有当arr.length是2的次幂才会相等。
3、hashmap 扩容rehash过后,元素新的位置,要么在原角标位置,要么在原角标+扩容位置上。因为扩容长度是将长度左移1。
比如扩容前长度是8,扩容后长度是16
第一种情况:
扩容前:
00000000 00000000 00000000 00000101
&00000000 00000000 00000000 00000111 8-1=7
-------------------------------------
101 ===== 5 原来脚标位是5
扩容后:
00000000 00000000 00000000 00000101
&00000000 00000000 00000000 00001111 16-1=15
-------------------------------------
101 ===== 5 扩容后脚标位是5(原脚标位)
第二种情况:
扩容前:
00000000 00000000 00000000 00001101
&00000000 00000000 00000000 00000111 8-1=7
-------------------------------------
101 ===== 5 原来脚标位是5
扩容后:
00000000 00000000 00000000 00001101
&00000000 00000000 00000000 00001111 16-1=15
-------------------------------------
1101 ===== 13 扩容后脚标位是13(原脚标位+扩容长度)
2、resize()方法:
1、如果当前oldTable容量是否为空,如果为空,指定为0。
1.1 老容量大于0,如果大于指定的最大值Integer.MaxVALUE就不会扩容了。
1.2 如果没有超过最大值,就扩充为原来的两倍。并且新阈值也要扩充为两倍。
2、如果当前为空,并且老阈值不为0,新的容量等于老的阈值。
3、新的容量为16,阈值=默认为16*负载因子0.75
4、再进行rehash
JDK7 JDK8 HashMap线程不安全的原因:
JDK7:由于多线程对HashMap扩容,resize方法的transfer方法中,采用的头插法。
某个线程执行中,挂起,其他线程完成了数据迁移,等CPU释放资源后被挂起的线程重新执行逻辑,会造成链表的死循环。
先put插入元素,调用addEntry方法,判断是否超过阈值,超过就会调用resize,resize再调用transfer

在最后三行,造成循环链表。
rehash过程,先扩容2倍的新空间
再头插法,移动元素。
真实案例:
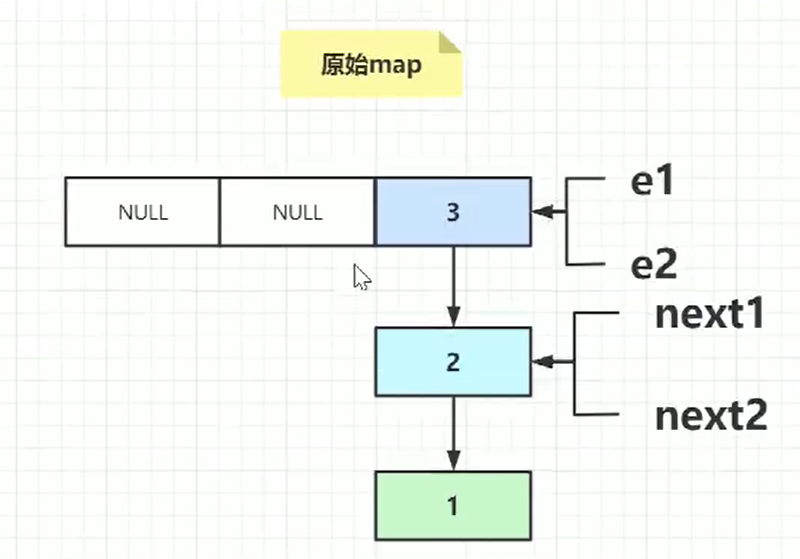
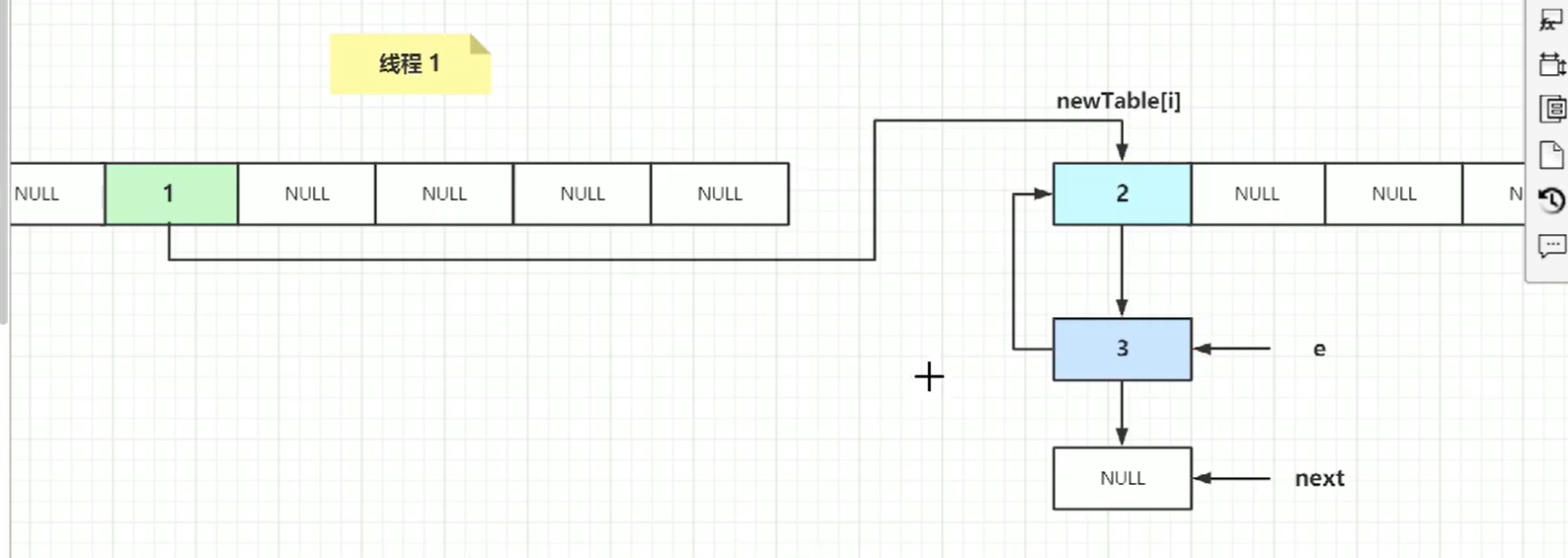
两个线程目前都要扩容,线程A执行e1指针指向3,线程B执行e2指向3,并且线程A,B的next1,、next2都指向2。
假如这个时候线程B时间片消耗完了,if(hash)代码后挂起,线程A目前扩容已经完成了:
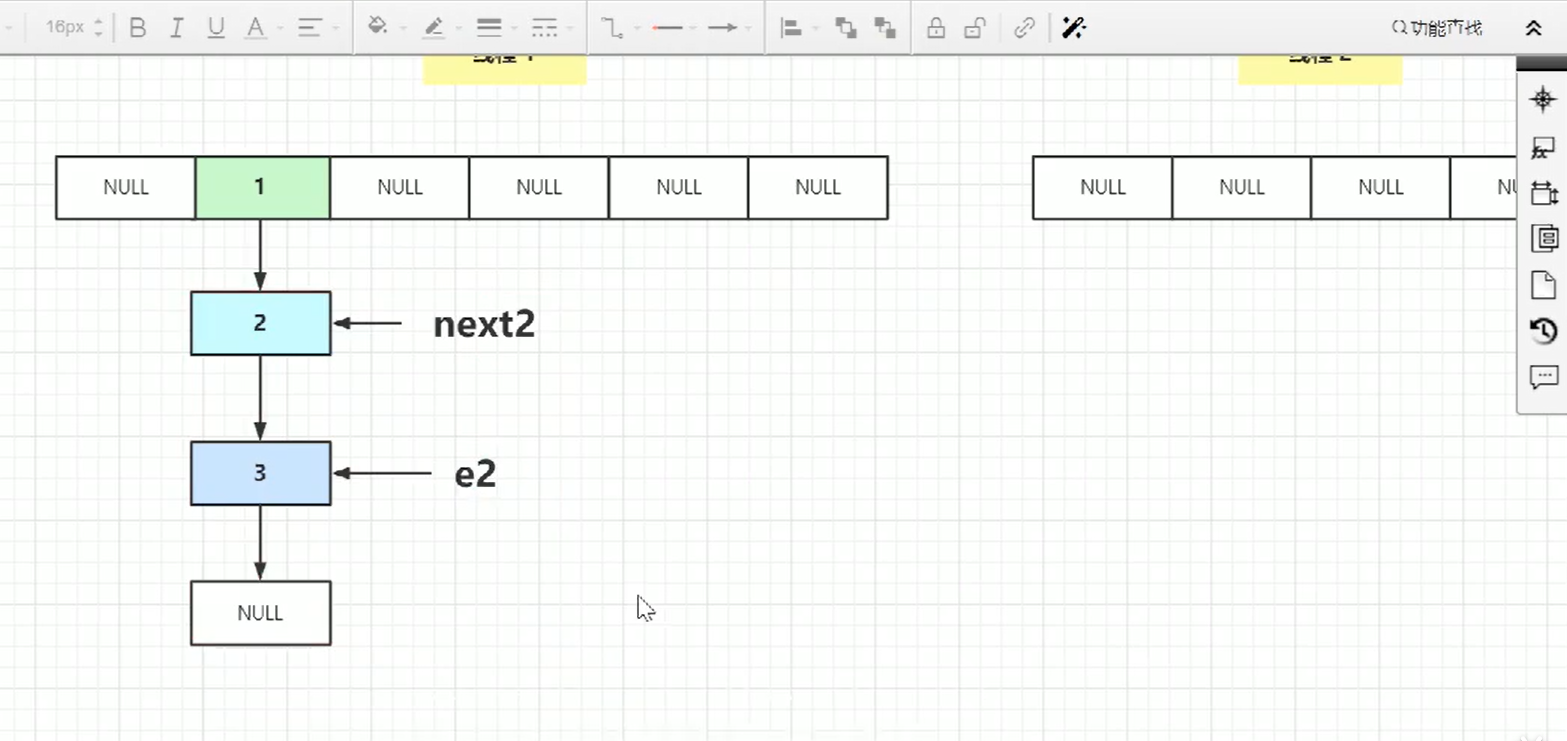
并且这个时候线程B也是有个新数组的,长度同样是之前的2倍。
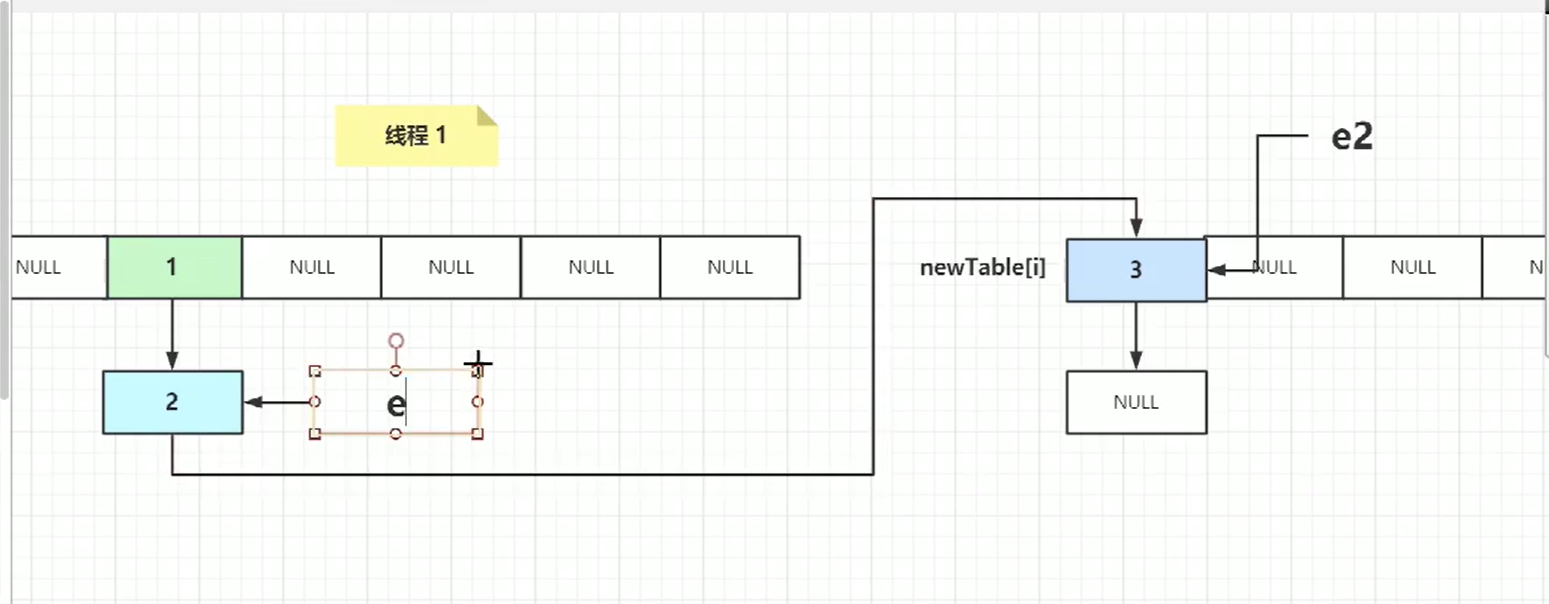
new table[i]=e,e称为了第一个节点,e指针指向了next所以
左边next变成了e。
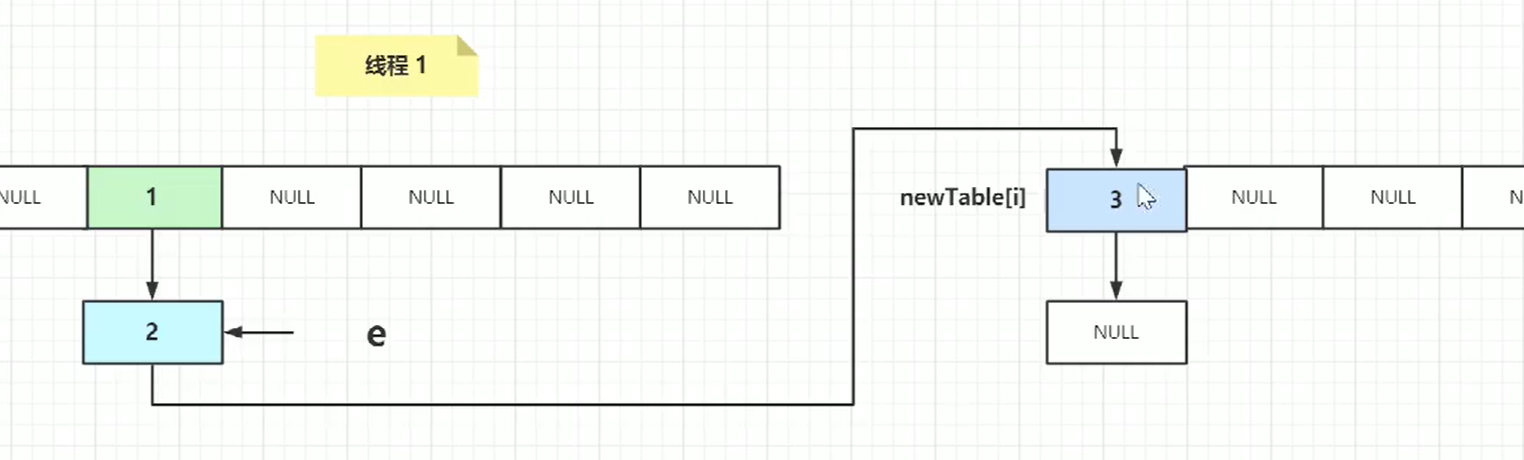
下次遍历:
e.next取到3这个节点
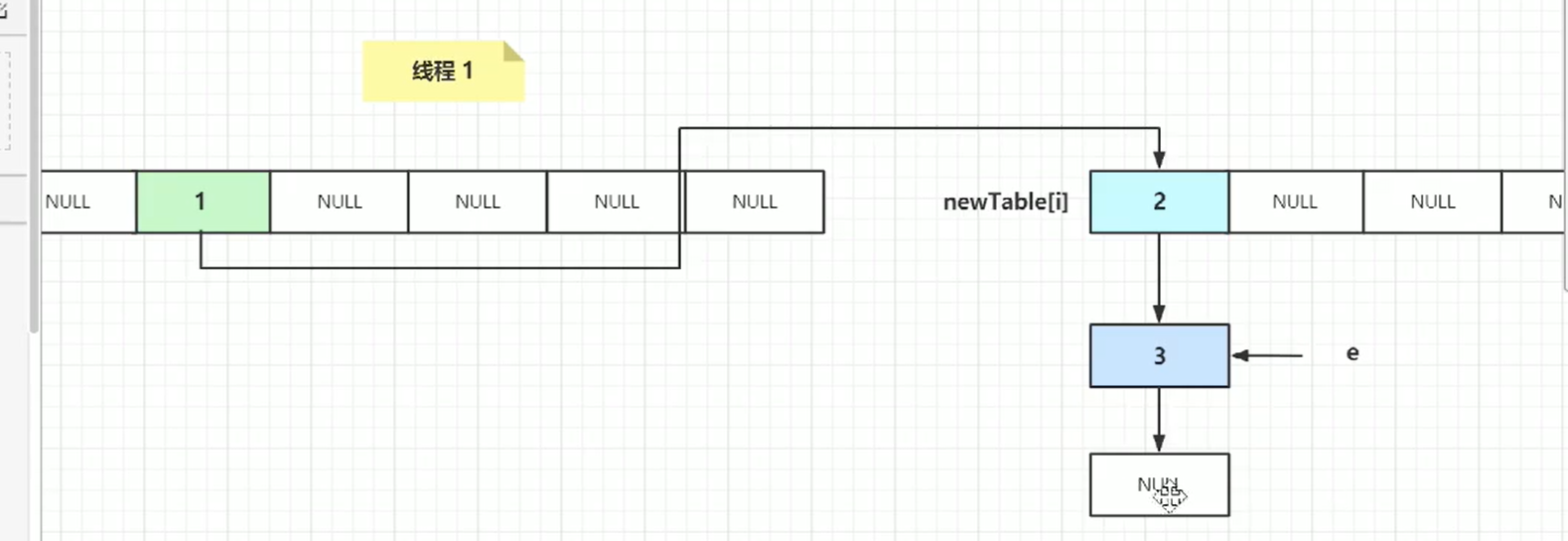

e.next=newtable[i] 就出现环状。
JDK8:
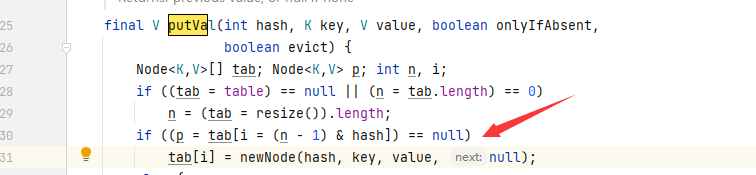
1、线程不安全的原因,假设A,B线程都在进行put操作,并且hash函数计算出来插入的下标都是一样的。当线程A执行完该句代码(if()没有碰撞)时间片消耗完挂起,而线程B刚好获得时间片插入元素,
完成了正常的插入,然后线程A获得时间片,因为A已经判断了hash碰撞,会再次插入。这样A插入的值就会覆盖B线程的值
2、++size操作,经典的线程并发问题。
ConcurrentHashMap 1.7
Java 1.7中的ConcurrentHashmap由默认的16个segment+hashEntry+链表组成,可以认为是支持16个线程并发。
默认segment数量为16,并发数量也是16,负载因子是0.75
1、put流程:
1.1、检查计算得到的位置的segment是否为null
1.2、初始化segment流程:
1.3.1检查计算得到的位置的segment是否为null
1.3.2为null继续初始化,使用segment[0]的容量和负载因子创建一个hashEntry数组
1.3.3再次检查计算得到的指定位置的segment是否为null
1.3.4使用创建的hashentry数组初始化这个segment
1.3.5自炫判断segment是否为null,使用cas给segment赋值
1.3segment.put插入key,value值
扩容rehash
ConcurrentHashMap的扩容,只会扩容到原来的两倍。老数组的数据移动到新的数组时,位置要么不变,要么变为index+oldSize
参数里会在扩容之后进行头插法。
Java8中的ConcurrentHashmap是由Node数组+链表/红黑树组成
1、concurrentHashMap的初始化通过自旋和CAS操作完成。
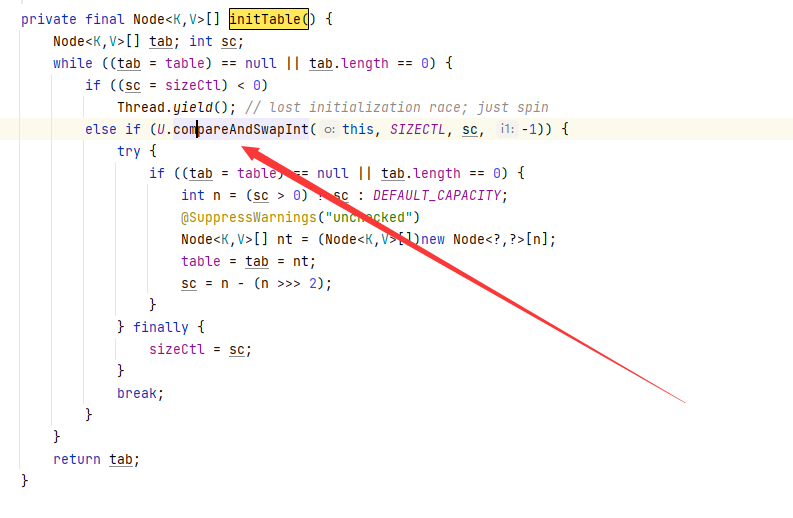
sizeCtl表示初始化状态
-1 正在初始化
-N 表示有N-1线程正在扩容
3 表示table初始化大小如果table没有初始化
4 表示table容量,如果table 已经初始化。
知识点:
coucurrentHashMap和hashmap一样没有用,都不会初始化。 所以注释还是建议给一个容量32,因为扩容rehash会很消耗时间。
1、默认容量是16。
ConcurrentHashMap 1.8

初始化通过自旋和CAS操作完成。
while循环+cas操作
sizeCtl决定目前初始化的状态
1、-1说明正在初始化
2、-N说明有N-1个线程正在进行扩容
3、表示table初始化大小,如果table没有初始化。
4、表示table容量,如果table,已经初始化。
put过程:
1、算出hash值
2、数组。
3、如果当前数组为空,初始化iniTable()
3.1、判断当前如果table为空,是否sizeCtl<0让出线程使用权。或者再进行扩容,扩容为两倍,再修改sizeCtrl的值
4、如果当前hash是否为空,为空进行Cas插入
5、如果当前节点正在发生迁移,进行协助迁移
6、进行插入。synchronize加锁。(与hashmap是差不多的)
7、判断是否进行扩容。
8、添加baseCount算size,for循环,用的一个数组,累加sumCount。
。
红黑树:
不要求左右子树严格的平衡性,所以插入删除效率+查询中总体性能比较稳定,而光查询不插入删除,二叉平衡树效率更高。
红黑树是对2-3-4树的一种实现,在二叉树属性加入一种颜色属性表示2-3-4不同节点。
2-3-4,树中2节点对应着红黑树的黑色节点,而2-3-4非2节点是以红节点+黑节点的方式存在
红节点的意义是与黑色父节点相结合,表示2-3-4树中的3,4节点。
1、根节点必须是黑色的。
2、红色节点的孩子必须是黑色的。父亲子女不能连续红色。
3、任何一个节点,到它叶子节点,所以路径黑色节点数目是相同的。
4、 红黑树最大的高度是2*log(n+1)