1 from bs4 import BeautifulSoup 2 import urllib.request,urllib.error 3 import urllib.parse 4 5 6 count=0 7 def askURL():#获取当前页的智能合约地址 8 head={ #模拟浏览器头部信息 9 "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" 10 } 11 #用户代理,告诉豆瓣服务器机器类型。 12 baseurl="https://etherscan.io/contractsVerified/" #获取智能合约地址页面 基地址 13 for i in range(1,10): 14 url=baseurl+str(i)#1-9页 加在基地址后面 15 print(url) 16 request = urllib.request.Request(url,headers=head,method="GET")#封装访问信息 17 response = urllib.request.urlopen(request,timeout=30)#访问网页,必须设置 访问时间超过多少,否则会被拒绝访问 18 html=response.read().decode("gbk")#以gbk的方式解码,添加在列表里 19 Parse_html(html)#在每一个合约中抓取源代码 20 21 def Parse_html(html): 22 bs = BeautifulSoup(html,"html.parser")#解析每个html文件, 23 head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息 24 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36" 25 } 26 t_list=bs.find_all(class_="hash-tag text-truncate") #将每个页面中的25个合约地址获取到 27 str1="https://etherscan.io/address/" #合约页面基地址 28 str2="#code"#合约页面地址的最后部分,合约地址在str1、str2中间 29 30 for item in t_list: 31 global count #全局变量 文件名 32 url=str1+item.string+str2 #拼全合约地址 33 request = urllib.request.Request(url, headers=head, method="GET") #打包访问信息 34 print("contract:"+url) 35 response = urllib.request.urlopen(request,timeout=30) #访问合约页面 36 contract = response.read().decode("utf-8") #解析合约页面 37 ds = BeautifulSoup(contract, "html.parser")#用html解析打开 38 contract = ds.find_all(class_="js-sourcecopyarea editor") #定位页面中的合约信息 39 text=contract[0]#只取合约 去除标签 40 result=text.get_text()# 转成string返回给result 因为write只能写string 41 filename = str(count) + 'sourceCode.txt' 42 count=count+1 43 with open(filename, 'w',encoding='utf-8') as file_object: 44 file_object.write(str(result)) 45 askURL()
最近由于科研需要,今天手撸了一个爬取etherscan.io官网上最新的500个智能合约代码。
maybe爬虫或者代码架构有些不合理,但是我是一只能抓老鼠的猫!
因为etherscan.io官网是国外的,所以需要FQ才能访问。所以该代码的运行必须保证本机能够FQ。
代码中没有设置国外代理,博主是没有找到个free的国外代理,用的本机的FQ软件。
下面教程,教你一步一步的设置python程序在你本机能够FQ的情况下,从你本地FQ出去爬取智能合约。
First:
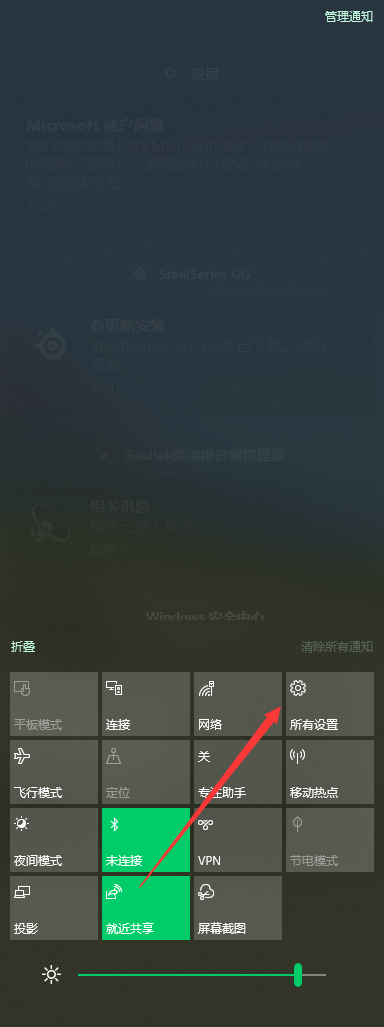
Second:
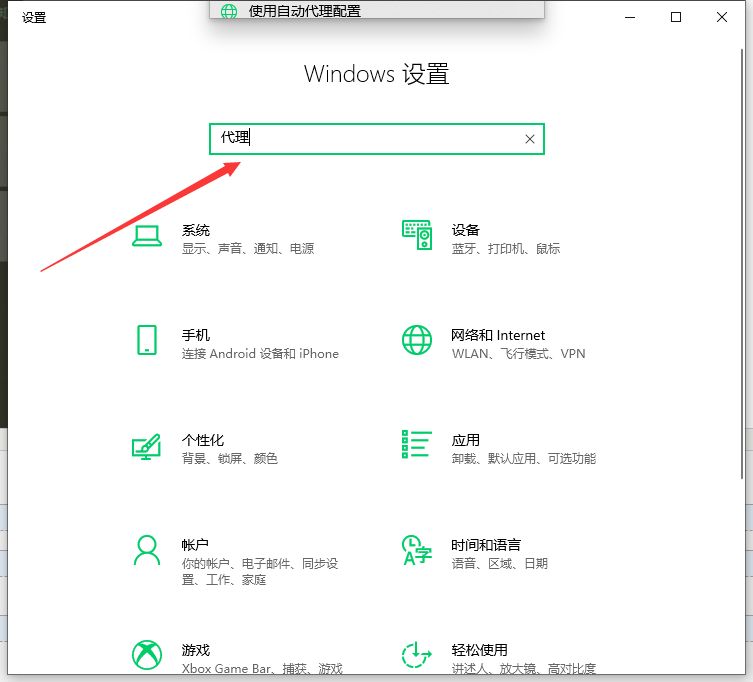
Third:
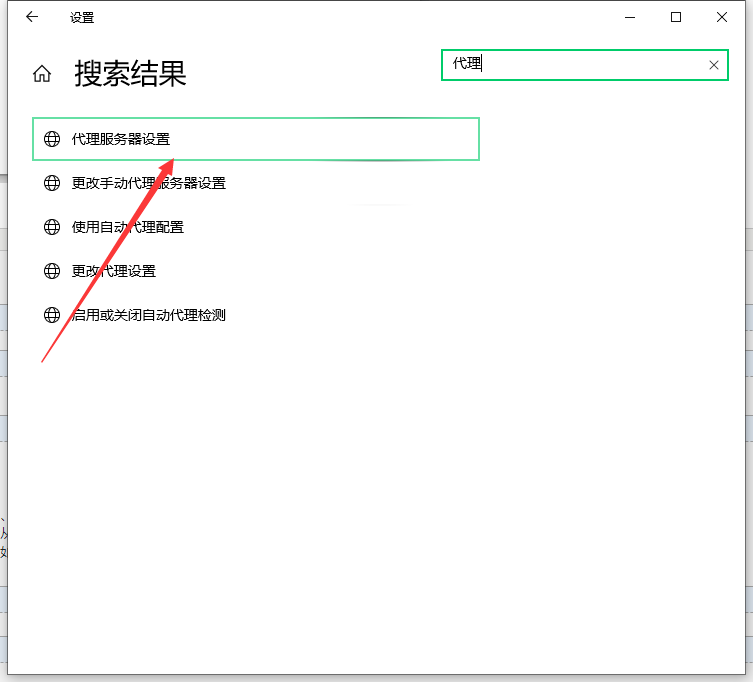
Forth:
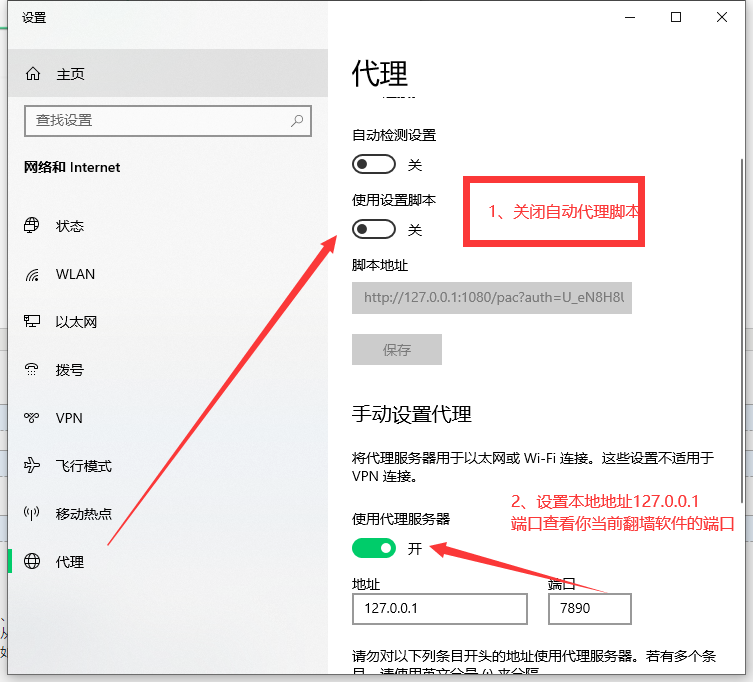
结果:起飞
