这一篇文章我们首先会介绍一下归并排序,并以归并排序和我们上一章所说的插入排序为例,介绍时间复杂度。此系列的所有代码均可在我的 github 上找到。
点此查看本文归并排序的完整代码。
分治法
在介绍归并排序前,我们需要首先介绍一下分治法,归并排序正是分治法的一个典型应用。
分治法:将原问题分解为多个规模较小的但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。
分治法一般而言分为这三步:
分解:将原问题分为若干个子问题,这些子问题是原问题的规模较小的实例。
解决:对于每一个子问题,递归地求解其子问题(即如果要求解一个子问题,但如果这个子问题仍然很复杂,那么我们可以像对待原问题一样,再将其分为多个子子问题)。如果子问题的规模足够小,则直接求解(例如排序问题中,如果只有一个数据需要排序,那么这个问题已经非常简单了,已经可以直接得出这个问题的解)。
合并:将这些子问题的解合并在一起,组成为原问题的解。
这其中最为重要的一步,是如何分解问题,保证其子问题与原问题除了在问题规模上,其他所有属性均相同。
归并排序
归并排序完全遵照分治法的思路:
分解:将等待排序的n个元素的序列分解为各 n/2 个元素的两个子序列。
解决:如果元素个数大于1,继续进行分解;如果元素个数等于1,直接返回此序列。
合并:合并两个已排序的子序列,形成一个已排序的序列。
虽然上面这部分内容就是归并排序的步骤,但可能很多读者依然没有太明白:什么?就这?这就排序好了?是的,就这。接下来我们详细介绍一下每一步的过程。
归并排序的合并步骤
归并排序的合并步骤是归并排序最重要的一步。这一步的目标是:
将两个已经排序完成的序列合并为一个新的排序完成的序列。
具体C语言代码如下:
// 合并两个相邻的数组
// 将已经有序的数组 array[0, array_length1 - 1] 与 array[array_length1, array_length1 + array_length2 - 1]
// 合并至 array[0, array_length1 + array_length2 - 1],并依然保证有序
int Merge(int* array, int array_length1, int array_length2){
int i, j, k; // 临时变量
int* temp_array1 = (int*)malloc(sizeof(int) * (array_length1 + 1));
int* temp_array2 = (int*)malloc(sizeof(int) * (array_length2 + 1));
// 复制新数组,因为原数组将会用于储存结果
for(i = 0; i < array_length1; i++){
temp_array1[i] = array[i];
}
temp_array1[array_length1] = INT_MAX;
for(i = 0; i < array_length2; i++){
temp_array2[i] = array[array_length1 + i];
}
temp_array2[array_length2] = INT_MAX;
// 进行合并操作
j = 0;
k = 0;
for(i = 0; i < array_length1 + array_length2; i++){ // 我是第22行
if(temp_array1[j] > temp_array2[k]){
array[i] = temp_array2[k];
k++;
} else{
array[i] = temp_array1[j];
j++;
}
}
// 释放申请的空间
free(temp_array1);
free(temp_array2);
return 0;
}
上述代码中,array是一个数组,我们的目标是将已经有序的相邻数组 array[0, array_length1 - 1] 与 array[array_length1, array_length1 + array_length2 - 1] ,合并至 array[0, array_length1 + array_length2 - 1],并依然保证有序。如下图所示:
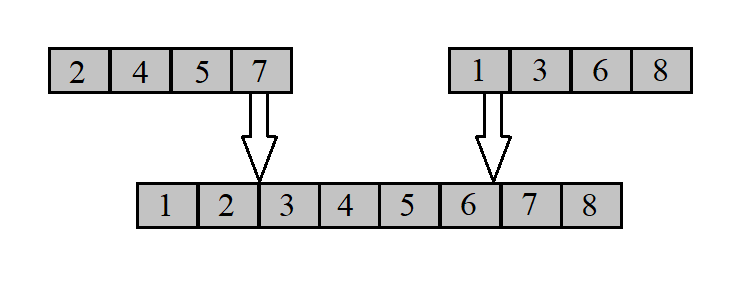
具体步骤的解释我们仍以扑克牌为例:现在我们在桌上有两堆牌面向上的牌,每堆都按照从小到大的顺序排序完成,即最小的牌在顶部。此时我们比较这两堆牌的顶部牌的大小,选择较小的那一张(如果一样大,就随意选择一张),将牌拿走,并将其牌面向下放在输出牌堆,此时我们拿走的那张牌下面的牌也显露了出来,我们重复上述过程,继续将选出来的牌牌面向下盖在输出牌堆,直至将所有牌均转移至输出牌堆。
在合并的过程中,必定会有一个牌堆先空,此时最直接的想法是直接将另一个牌堆的所有牌 牌面向下盖在输出堆,但在我上文中给出的的归并排序代码中,为了使得代码简洁,我采用了另外一种策略,在两个牌堆底部添加一张无限大的牌(由于真实计算机的限制,无法表示无限大,所以我们采用int的最大值,即INT_MAX来代替,效果也是一样的),这样在另一个牌堆中,除了同样被我们人为添加进去的无限大牌以外,其余牌均小于无限大,那么必定也可以逐个将所有剩下的牌转移至输出堆。其实这样会有一个bug,即如果第二个数组中有多个数的大小是INT_MAX,那么我们会一直从第一个数组中取值,这样就会出现数组越界的问题,修复这个bug就当做课后作业交给读者们解决了。其实解决方法无非两种,一是规定数组中不得出现值为INT_MAX的数据,是的我就是这么懒,你来打我啊;二是判断如果 j 已经不小于 array_length1 了,则取值 temp_array[array_length1 - 1]。
上文中之所以要牌面向下仅仅是为了保证结果也是从小到大的,如果牌面向上结果则为从大到小。如果不理解这个小细节并不影响对于归并排序算法的理解,读者可以在阅读完整篇文章,理解了归并排序后再回过头来,应该就能马上明白其用处。或者读者也可以拿一副扑克牌自己亲手尝试一下。
证明合并步骤的正确性
正如我们上一篇文章所说,一个算法最重要的是正确性,所以我们将首先进行这一步,判断上述合并代码的关键步骤:第22行~第30行的正确性。如果判断正确性的3个步骤已经忘了,可以去回顾一下第一篇文章。同时为了方便说明,我们将第一个数组称为 L,第二个数组称为 R,同时 i 恒等于 j + k:
初始化:循环开始前,i == 0 ,即目标数组 array 为空,必然有序,且这个空数组包含 L 和 R 中的 0 个最小的元素;j == k == 0,则 L[j] 和 R[k] 分别为 L 和 R 数组中未被复制到 array 数组的最小的元素。
保持:我们不妨假设 L[j] <= R[k],则 L[j] 是未复制到 array 数组的最小的元素。因为 array[0, i - 1] 包含 i - 1 个最小元素且有序,所以将 L[j] 复制到 array[i] 以后,array[0, i] 包含 i 个最小元素,且有序。增加 i 值和 j 值后,L[j] 依然是 L 数组中未被复制到 array 数组的最小的元素,R 数组由于未发生变化,所以R[k] 依然是 R 数组中未被复制到 array 数组的最小的元素。反之若 L[j] > R[k],同理可得。
终止:当 j == array_length1,k == array_length2 时,程序终止。此时 array[0, array_length1 + array_length2 - 1] 包含 L[0, array_length1 - 1] 和 R[0, array_length2] 中最小的 array_length1 + array_length2 个元素且有序。L[array_length1] 和 R[array_length2] 是我们手动加入的两个无限大的值。
归并排序的其他步骤
在理解了合并步骤以后,归并排序的剩下两个步骤就很简单了。具体C语言代码如下:
// 归并排序,结果按升序排列
int MergeSort(int* array, int array_length){
// 若数组长度为1,必然有序
if(array_length == 1){
return 0;
}
int half_array_length = array_length / 2;
// 将数组分为两个部分,递归实现子数组的排序
MergeSort(array, half_array_length);
MergeSort(array + half_array_length, array_length - half_array_length);
// 将已经排序完成的子数组合并,实现整个数组的排序
Merge(array, half_array_length, array_length - half_array_length);
return 0;
}
我们可以将 Merge() 函数用在 MergeSort() 中,作为一个子程序。若数组长度为1,则直接返回,因为一个数据必然是有序的;若数组长度大于1,则将此数组分解为两个子数组,分别进行递归调用,通过这两步后,两个子数组已经有序,然后将两个数组进行合并,形成一个新的有序数组。
提示:可能有的读者才入门没有多久,无法理解为何将数组分为两个子数组后,递归调用完成后这两个子数组就分别有序了。我们以第一个子数组为例进行分析:假设第一个子数组(不妨称为数组a)长度为4,所以我们仍需将此数组分解,分解为长度均为2的两个子子数组(不妨称为 a_a 和 a_b ),对于数组 a_a 而言,仍需分解为长度各为1的两个子子子数组(不妨称为 a_a_a 和 a_a_b),由于 a_a_a 和 a_a_b 各只有一个元素,所以已经有序,直接返回。那么数组 a_a 已经有了两个有序的子数组,利用我们上文所说的合并算法,合并为一个长度为2的有序数组。同理数组 a_b 也通过类似步骤成为一个长度为2的有序数组,那么我们对数组 a_a 和 a_b 使用上文中的合并算法,则将数组 a_a 和 a_b 合并为一个长度为4的有序数组,即为a。
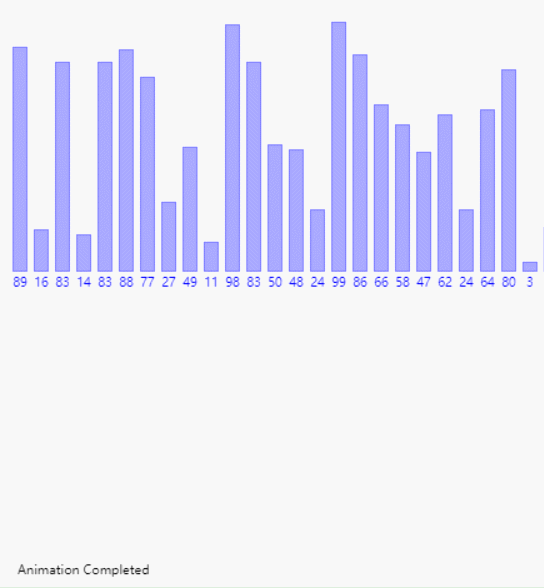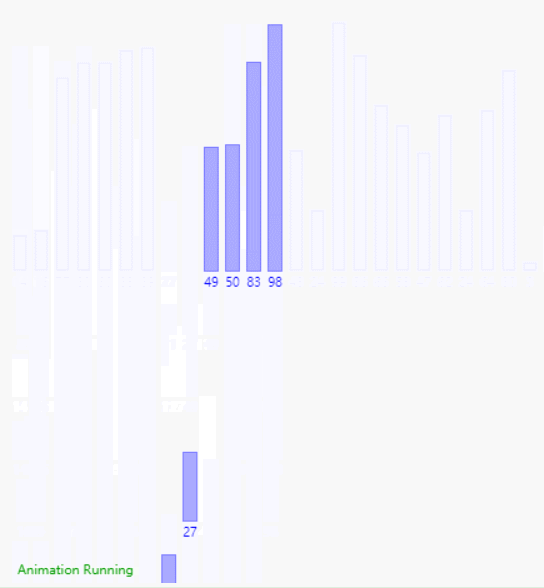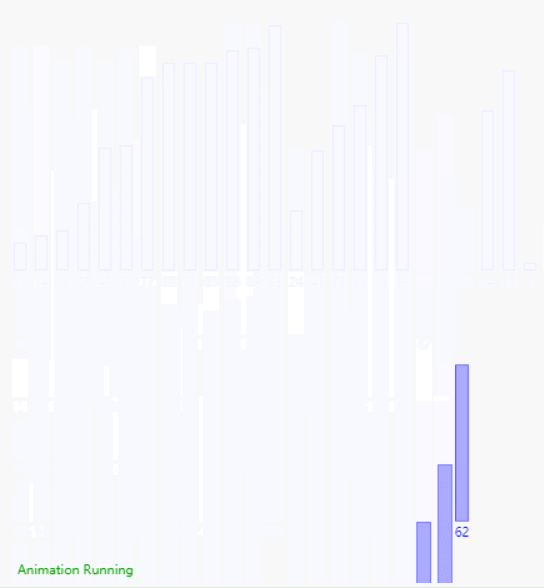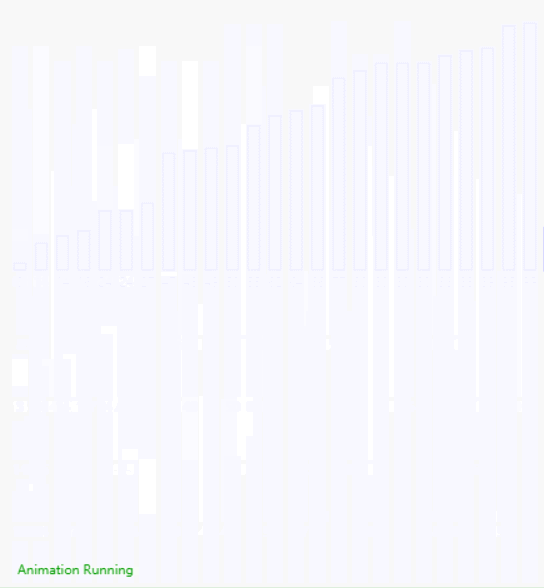
如下图,就是一个将数组 [5, 4, 2, 7, 1, 6, 8, 3] 进行归并排序的样例。

归并排序的运行效率分析
当一个算法包含对其自身的递归调用时,我们可以使用递归方程来描述其运行时间。我们对此进行的分析也是按照分治法的三个步骤来进行。
T(n)表示规模为n的一个问题的运行时间。当问题规模足够小的时候,直接求解仅需要常量时间,如归并排序时数组长度为1时,记为(Theta (1)),含义与数学中渐进分析一样,我们通俗的理解为等于某个常数,规范解释我们将在下文的时间复杂度中详细介绍。
当问题规模较大是,需要进行分解,例如将原问题分解为a个子问题,每个子问题的规模是原问题的 1/b (归并排序中 a 和 b 均等于2,但在很多其他分治法中,a 和 b 并不相同)。为了求解一个规模为 n/b 的子问题,需要 T(n/b) 的时间,所以需要 a*T(n/b) 的时间来求解 a 个子问题,如果分解子问题需要时间 D(n),合并子问题的解需要时间 C(n),那么得到递归式:
例如对于归并排序,我们也如上进行分析,此时我们仅分析最坏情况,原因我们已经在上一篇文章中讨论过了:
分解步骤仅需要计算子数组的中间位置,需要常量时间,即 (D(n) = Theta(1))。
解决问题时,我们需要递归地求解两个规模均为 n/2 的子问题,因此需要时间 (2*T(n/2))。
合并问题的解时,只需要扫描两个子数组各一遍,因此与问题规模成线性关系,即 (C(n) = Theta(n))。
故最终的时间复杂度公式为
如果数学基础较好的读者,可能已经能够通过此表达式计算出最终的运行时间:
与数学中不同,由于计算机采用二进制,所以log默认底为2,而非10,这一点需要读者们注意,以后的文章我们将不会强调这一点,但读者们应该时刻记住这一关键点。具体的结果计算过程,由于篇幅原因,我们不再赘述,数学基础较差的读者可以去搜索“递推公式求和”,如果只是想知道结论也可以直接搜索“主定理”。如果确实需要的话,大家可以给我留言,我以后专门写一篇文章来详细介绍一下。
从上述分析我们可以看出,归并排序的时间复杂度远低于插入排序,在实际中,如果一个算法的时间复杂度已经达到 O(n*lgn),通常认为已经无需再进行优化了,因为对数的增长趋势非常低,我们几乎可以认为 O(n*lgn) 几乎等同于 O(n),而一个问题,你再怎么也要把数据全部读取一遍吧,这样时间复杂度已经达到了 O(n)。当然你要是真能做到 O(n) 的话,那我只能说一声“大佬大佬,技不如人,甘拜下风”。
时间复杂度
我们前面说了这么久的时间复杂度,那时间复杂度究竟是一个什么东西呢?其实在看完上一篇文章和此文章前面的内容以后,相信大部分读者只需要读一遍下面的内容就能明白了。
之所以我们提出时间复杂度这个概念,正如我们前文所说,我们大部分时候并不需要确定一个算法的精确运行时间,只需要知道他的增长趋势。为了这个目的,我们将低次项与常系数忽略,只关心影响此算法效率最为核心的部分。
渐进符号
这些符号直接使用的数学中的相关符号,含义也几乎完全一样。
(Theta) 记号我们前面已经看到过了,读作 Theta ,在这里,我们给出他的一个详细定义:
对于任意给定的函数 (g(n)):(Theta(g(n)) = { f(n)):存在正常量 (c_1)、(c_2) 和 (n_0),使得对于所有 (n geq n_0),有 (0 leq c_1*g(n) leq f(n) leq c_2 * g(n) })。
通俗一点来说,当问题规模足够大时,若函数 (f(n)) 能“夹在” (c_1*g(n)) 和 (c_2*g(n)) 之间,则 (f(n)) 属于集合 (Theta(g(n)))。
例如 (a*n^2 + b*n + c + d*lgn in Theta(n^2)),其中 (a eq 0)。
第二个符号则是 O 记号,一般读作“大O”。定义为:
对于任意给定的函数 (g(n)):(O(g(n)) = { f(n)):存在常量 (c) 和 (n_0),使得对于所有 (n geq n_0),有 (0 leq f(n) leq c*g(n) })。
与之相似的符号是 o 记号,一般读作"小o"。定义为:
对于任意给定的函数 (g(n)):(o(g(n)) = { f(n)):存在常量 (c) 和 (n_0) ,使得对于所有 (n geq n_0),有 (0 leq f(n) < c*g(n) })。
与 大O 记号相反的是 (Omega) 符号,读作“大Omega”,定义为:
对于任意给定的函数 (g(n)):(Omega(g(n)) = { f(n)):存在常量 (c) 和 (n_0) ,使得对于所有 (n geq n_0),有 (0 leq c*g(n) leq f(n) })。
以及 (omega) 符号,读作“小omega”,定义为:
对于任意给定的函数 (g(n)):(omega(g(n)) = { f(n)):存在常量 (c) 和 (n_0) ,使得对于所有 (n geq n_0),有 (0 leq c*g(n) < f(n) })。
看了这么多,你一定在想,这是什么东西?其实后面四个符号都是从 Theta 符号衍生而来的,大O和小o表示渐进上界,大Omega和小omega是渐进下界。
或者说人话,Theta表示这个算法运行速度就是g(n)这么快;大O表示这个算法运行速度至少和g(n)一样快;小o表示这个算法运行速度必定快于g(n);大Omega表示这个算法速度至少和g(n)一样慢;小omega表示这个算法必定慢于g(n)。一眼看来是有点乱,但相信大家多看几遍也就明白了。
何为时间复杂度
现在我们一句话就能说清楚什么是事件复杂度了:一个算法运行时间的大O,或者说这个算法最差情况下的运行效率。例如
插入排序时间复杂度:(O(n^2))
归并排序时间复杂度:(O(n*lgn))
为什么一定要定义这么复杂呢?其实最重要的原因是,算法是一门对于数学和逻辑要求很高的学科,包含了大量的证明和计算,这就要求其必须有着一套严密的符号规定与术语。
当然对于普通人而言,最重要的是表示我是真的学了算法的以及我能听懂别人在说什么,同时也可以偷偷懒。例如某一天有人告诉你“我这个算法的时间复杂度是O(n)”,你一下子就明白了,如果没有这些定义,那么应该怎么说?“如果输入规模是n,那么我的这个算法在最差情况下,运行时间和n呈线性关系。什么?你不知道什么是线性关系?线性关系是xxx”,这样一想,还是时间复杂度这五个字听着舒服些。
结语
前面两篇文章的数学知识可能较多,但这确实无法避免,作者已经尽量减少了数学相关的内容,数学证明也尽量使用大白话来描述了。后续将逐步介绍一些算法和数据结构,需要使用的数学知识相较于这两章要少很多,所以读者们如果真的数学底子不是很好的话,也不需要担心,但作者依然建议有时间能够学一学数学,毕竟研究计算机的那一波祖师爷可几乎全是数学家呢,计算机天生就和数学分不开。如果有条件的话,可以先学习一下高中数学里数列的知识,然后当某一天感觉自己达到了瓶颈时,可以学习一下离散数学,如果非常有兴趣的话,可以再学一学数论。
下一篇文章将会介绍排序算法中最为常用的“堆排序”。
原文链接:albertcode.info
个人博客:albertcode.info