【结对情况】
【各种传送门】
【设计说明】
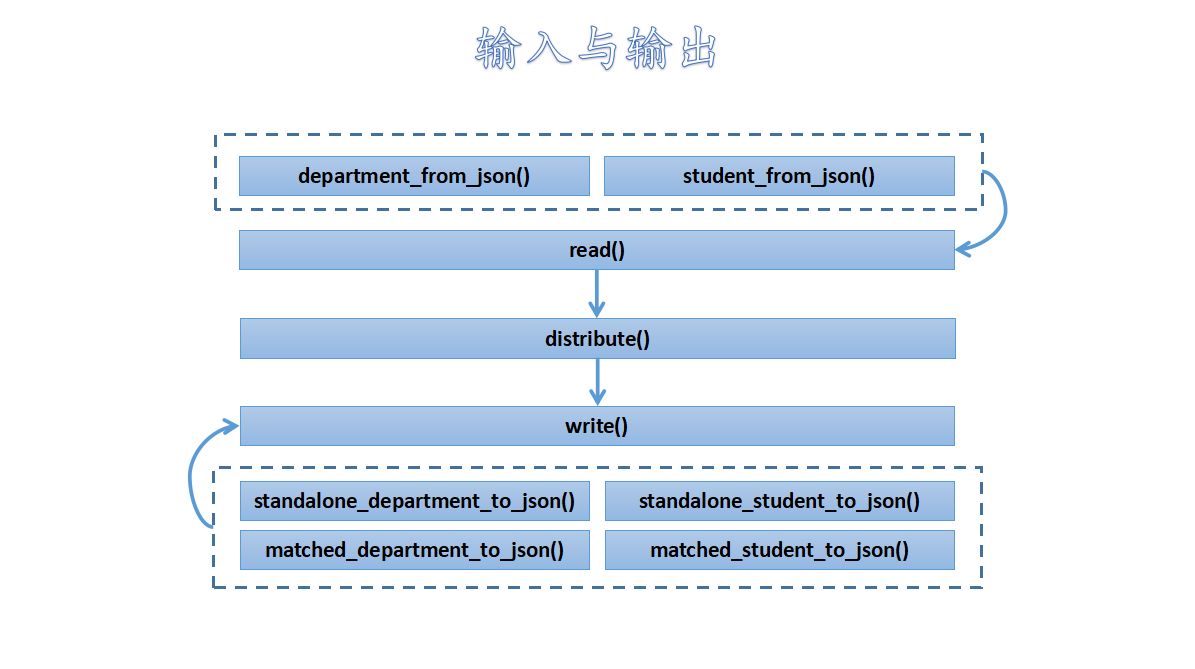
接口设计(API)
friend void student_from_json(const json& j, Student& student);
friend void department_from_json(const json& j, Department& department);
friend void read(string file_name, DistributeSystem& ds);
friend void matched_student_to_json(const Student& student);
friend void standalone_student_to_json(const Student& student);
friend void matched_department_to_json(const Department& department);
friend void standalone_department_to_json(const Department& department);
内部实现设计(类图)
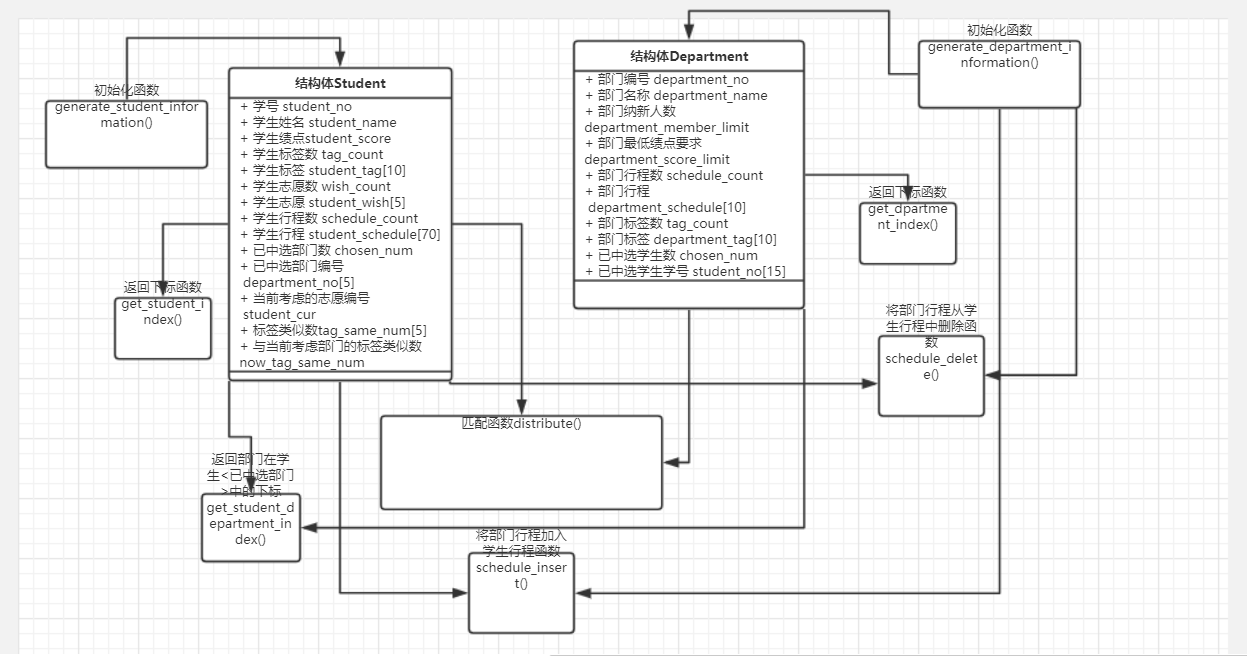
代码规范
命名规范
- 类与结构体:第一个大写字母开头,后面跟随的字母全部用小写。
- 变量:所有字母均小写,使用下划线“_”作为单词的分隔。
- 指针: '*' 应靠近类型,而不是变量名。
- 引用: '&' 应靠近类型,而不是变量名。
排版规范
- 方法和函数的布局 :对于有较多参数的函数的写法,如果参数较多,一行写不下,我们应该分成几行来写,并且每个参数都另起一行对齐。
- 缩进:缩进的时候,每一层缩进4个空格;不要使用TAB,用空格。
- 行规则:保证一行只写一条语句,一行只定义一个变量。
- 所有的 if, while 和 do 语句,要么用单行格式,要么使用花括号格式。
- 圆括号 () 规则:圆括号与关键字之间应放一个空格; 圆括号与函数名之间不要有空格。
- Continue 和break: Continue 和break 实际上起到与goto一样的作用,因此,尽量少用为上。并且,Continue与break最好不要连用。
- 运算符号的规则 : 一元操作符如(!、~ 等等)应贴近操作对象; 二元操作符如(+、*、%、== 等等)应在前后留空格;++ 和 -- 尽量使用前置运算。
- 变量声明语句块: 变量应该是随用随声明,不要集中在函数前,例如for语句的循环变量,应只在for语句中定义。
注释
- Include 语句注释:如果有必要,#include语句也应有注释,它可以告诉我们,为什么要包含这个头文件。
- 语句块注释:尽量用代码代替注释,如果决定用注释,避免喃喃自语或含糊不明的注释。
编码要求
- 不要忽略编译器的警告:编译器的警告,通常能够指示出编码存在的笔误或逻辑错误。因此,不能轻视编译器的任何警告,准确来说是,不允许代码在编译时产生任何警告信息。
- 初始化所有的变量:无论如何,都要初始化所有的变量。我们无法保证编译器会给个什么样的初值。
- 保持函数短小精悍:一般情况下,一个函数最好在一个屏幕内,不要超过三个屏幕。
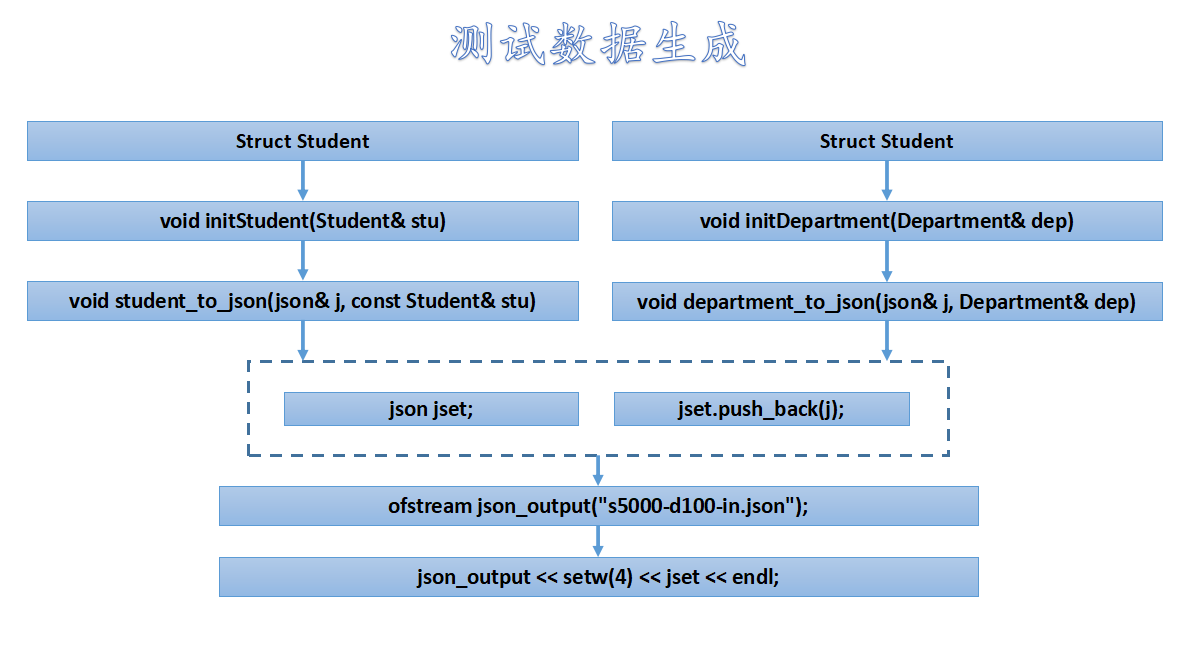
测试数据生成


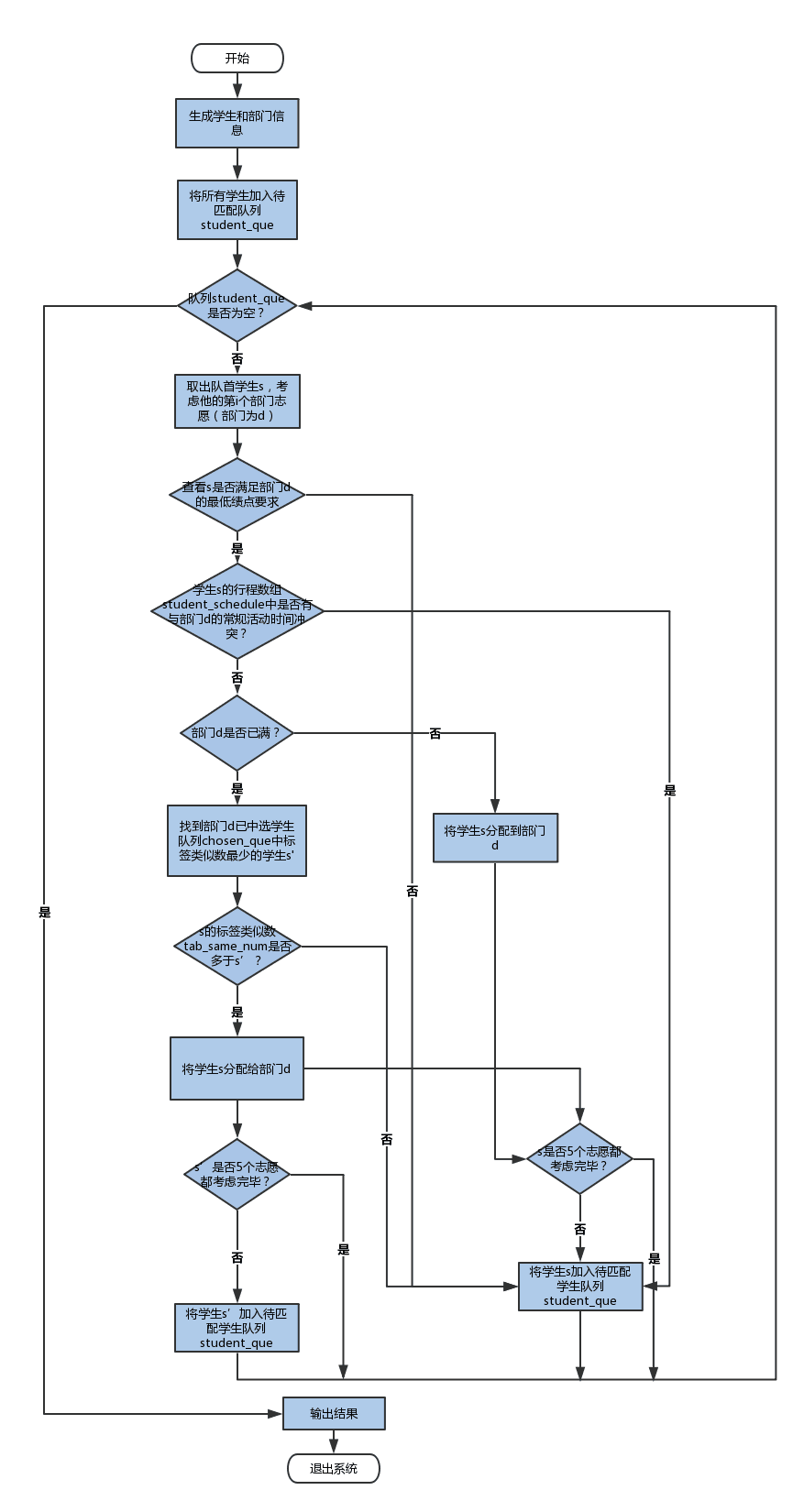
匹配算法设计(思想/流程)
分配原则及思想:
- 一看志愿。学生待分配队列先按照志愿顺序进行排序,分配时,第一志愿优于二、三、四、五志愿,以此类推;
- 二看最低绩点要求。部门提出最低绩点要求,以此作为进入部门的敲门砖,当且仅当学生满足此条件,才考虑条件3 ——行程时间
- 三看行程时间。学生满足最低绩点要求后,通过匹配其与志愿部门的活动时间,查看是否有冲突。当行程时间无冲突时,有两种情况,一种是该部门未满,则学生就可以入选该志愿部门;另一种是该部门已满,则考虑条件4 ——标签类似数;
- 四看标签类似数。当部门已满,通过学生与部门间的标签类似数进行重筛选,决定去留。
- 算法流程图:
匹配算法评价
- 该算法是我们一起商量后决定实现的,较为贴切现实情况并且简洁易于理解的。有考虑过通过各部分占比进行权衡统计再分配,但最终得出的结论是并不符合现实情况,例如现实中部门对于学生成绩的要求,一般是给个最低的标准,防止部分学生因为部门活动影响学生,因此没有必要按照绩点高低进行排序筛选。我们一致认为,在匹配中最重要就是<有志愿——绩点满足要求——时间无冲突>这三个部分,至于其他的都是在这些的基础上进行拓展,因此,我们认为我们的匹配算法还是较为合理的。但是,设想都是特别美好的,当我们开始跑时,我们发现,匹配率简直低啊,居然不到一半,考虑到有一下几个原因:第一,有部分部门的纳新人数为零;第二,有部分学生的志愿只有1个;第三,匹配算法考虑的还不够周到。虽然说匹配率并不能反映一切,但是这么低也不正常,我反思。
【关键代码】
/*根据分配原则进行学生-部门分配*/
void DistributeSystem::distribute()
{
queue<Student> student_que; //待分配的学生队列
for (int i = 0; i < student_number; ++i)
student_que.push(stu[i]); // 初始都是未分配状态,都加进队列
while (!student_que.empty())
{
int ss = student_que.front().student_no;
int sss = get_student_index(ss);
Student& s = stu[sss]; //访问学生队列队首元素
student_que.pop();
// 第一步考虑学生s的第student_cur个志愿(部门为d)
int ww = s.student_cur;
int www = s.student_wish[ww];
int wwww = get_department_index(www);
Department& d = dep[wwww]; //访问部门队列队首元素
if (s.student_score >= d.department_score_limit)
{
//第二步考虑学生与部门时间是否有冲突
int same_schedule_num = 0;
for (int i = 0; i < s.schedule_count; ++i)
{
for (int j = 0; j < d.schedule_count; ++j)
if (s.student_schedule[i] == d.department_schedule[j])
same_schedule_num++;
}
>
if (same_schedule_num > 0)
{
s.student_cur++;
if (s.student_cur < s.wish_count)
{
// 如果五个志愿还没考虑完毕的话,放入队列中继续参与分配
student_que.push(s);
}
}
else
{
//若时间无冲突
//第三步考虑部门是否已收满
if (d.department_member_limit > d.chosen_num)
{
// 如果部门d还有剩余名额,直接中选
int ss = 0;
ss = s.student_no;
int dd = d.chosen_num;
d.student_no[dd] = ss;
int ddd = s.chosen_num;
s.department_no[ddd] = d.department_no;
s.chosen_num++;
s.student_cur++;
d.chosen_num++;
if (s.student_cur < s.wish_count)
{
// 如果五个志愿还没考虑完毕的话,放入队列中继续参与分配
student_que.push(s);
}
} //未收満
//若已收满,第四步考虑标签类似数
//先找到部门d<已中选学生中>标签类似数最少的学生s'
//将学生s的标签类似数和s’最少标签数的进行对比
else
{
//若部门无空余名额
int least_stu_no = -1; // 部门d<已中选学生中>标签类似数最少的学生s’编号
int pos = -1; // 以及s'在部门的<已中选列表中>的下标
int stu_pos = -1; //s'在<学生数组>中的下标
int less_stu_dep_pos = -1; //部门d在s'的<已中选部门数组>中的下标
int least_tag_same_num = 10; //最少的标签类似数
s.now_tag_same_num = get_student_now_tag_same_num(s.student_no, d.department_no); //学生s与部门d的标签类似数
for (int i = 0; i < d.chosen_num; ++i)
{
// 在部门d中查找标签类似数最少的学生编号
stu_pos = get_student_index(d.student_no[i]); //部门已中选学生在<学生>数组的下标
Student dmp = stu[stu_pos]; //对应的已中选学生
less_stu_dep_pos = get_stu_department_index(stu_pos, dmp.chosen_num, d.department_no);
if (least_tag_same_num > dmp.tag_same_num[less_stu_dep_pos])
{
least_tag_same_num = dmp.tag_same_num[less_stu_dep_pos];
least_stu_no = dmp.student_no;
pos = i;
}
}
//再判断纳新人数是否为0 以及 学生s的标签类似数和最少标签类似数less_tag_same_num的大小关系
//若纳新人数为0 或者 学生s的标签类似数<=最少标签类似数less_tag_same_num ,考虑学生s的下一个志愿
if (d.department_member_limit == 0 || s.now_tag_same_num <= least_tag_same_num)
{
s.student_cur++;
// 如果五个志愿还没考虑完毕的话,放入队列中继续参与分配
if (s.student_cur < s.wish_count)
student_que.push(s);
}
else
{
// 否则学生s就直接替换掉标签类似数最少的那个学生
int least_stu_index = get_student_index(least_stu_no); //被替换掉的学生s.在<学生数组>中的下标
Student& least_stu = stu[least_stu_index];
int least_stu_department_index = get_stu_department_index(least_stu_index, least_stu.chosen_num, d.department_no); //部门d在被替换掉的学生s.<已中选部门数组>中的下标
least_stu.department_no[least_stu_department_index] = -1; //被替换掉的学生该部门队列
//此时学生s已中选,保存中选信息
s.department_no[s.student_cur] = d.department_no;
s.tag_same_num[s.student_cur] = s.now_tag_same_num;
s.chosen_num++;
d.student_no[pos] = s.student_no;
} //替换
} //若部门无空余名额
}//行程无冲突
} //绩点满足
else
{
s.student_cur++;
// 如果五个志愿还没考虑完毕的话,放入队列中继续参与分配
if (s.student_cur < s.wish_count)
student_que.push(s);
}
}
}
【测试运行】








| 学生人数 | 部门人数 | 学生未分配人数 | 部门未分配数量 | 学生匹配率 | 部门匹配率 | 耗时(s) |
|---|---|---|---|---|---|---|
| 200 | 20 | 128 | 0 | 0.36 | 100% | 4 |
| 500 | 30 | 322 | 0 | 0.36 | 100% | 6 |
| 1000 | 50 | 722 | 0 | 0.28 | 100% | 10 |
| 5000 | 100 | 3626 | 0 | 0.27 | 100% | 21 |
效能分析报告


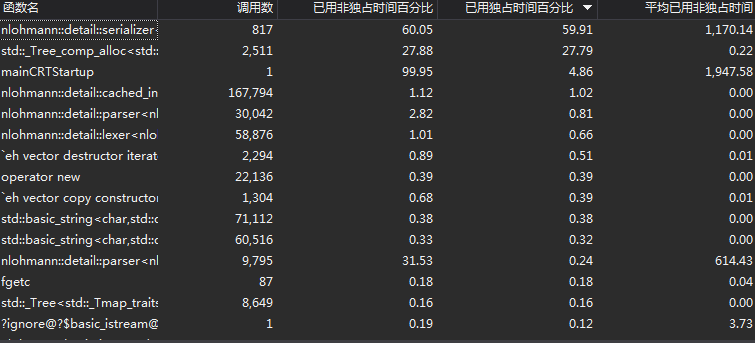
由上图可以看出,耗时最多的地方在于json文件的写和读,还有可以继续优化的空间。
【困难与解决】
json学习——雨勤
- 使用了助教在微信群中推荐的json,这个json的方法和网上最广泛流传的jsoncpp不大一样,没有Value、Reader和Writer。找资料的能力真的比较欠缺,其实网上有相应的中文博客解读,只是我一直没找对,于是很吃力地翻译阅读github上的文档。
时间——雨勤
- 问题:我在假期中主要进行了对json的学习,开假后就去漳州比赛(明明是公费旅游),白天课也很多,留给结对作业的时间十分有限。
- 解决:本周,无论在外地、在宿舍,夜夜修仙。
- 效果:伤身。
交流——雨勤
- 问题:一开始进行了讨论,制定了基本的原则与方案,但在后来代码实现的过程中,由于算法实现的一些原因,对最初的设计做出了修改,但两人之间并没有进行良好的沟通反馈,以至于后来在咨询队友一些变量细节问题时,突然发现对大原则变了……
- 解决:向匹配模块的大佬低头,有什么需要您说的算:)
规范——雨勤
- 问题:两人各有自己的代码习惯,虽然制定了代码规范,但好像没能严格的执行。
- 解决:是时候事后诸葛了,改。
计划——安琪
- 问题:实现初期赶着时间,想赶紧搭个框架出来好和小伙伴对接,蜜汁自信连流程图都没画就直接上手,导致算法设计模糊混乱,浪费了相当一部分时间。
- 解决:冷静分析后觉得还是不能本末倒置,于是老老实实把流程图画了下,觉得思路瞬间清晰了不少。
不符预期——安琪
- 问题:算法实现过程中发现之前和队友小伙伴讨论的原则存在一些问题,并不是很合理,且实现起来也相当麻烦。
- 解决:改、删。(勤勤我对不起你)
【对安琪的评价】
- 关键词:效率 投入 配合
- 没有队友我大概已经上天了。
- 这么好的大腿我是怎么抱到的?
- 队友安琪是一个进取心很强的girl,她会要求自己的工作一定在计划内完成,不会把时间浪费在其他繁琐的事情上。做决定的时候很果断,当我还在纠结题目表述不清,我们该这样还是该这样的时候,安琪已经“我们就这样做”了。
【对雨勤的评价】
- 关键词: 认真 负责 包容
- 什么,居然还要写队友缺点?
- 那大概就是太可爱了,导致我不能专心敲代码了_
- 因为一些不可抗拒因素,在实现阶段不能和雨勤进行很好的沟通交流,有部分细节擅作主张改完之后才跟她说,虽然她选择了原谅(给大佬递帽子),但还是很对不起她,害她要熬夜返工orz。面对json这种我看了两遍还是不大懂是什么鬼的东西,雨勤也不在怕的,很好的完成了,要好好亲亲她了O(∩_∩)O。
【PSP】
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 200 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 240 | 120 |
| Development | 开发 | 2010 | 2000+ |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 360 |
| · Design Spec | · 生成设计文档 | 0 | 0 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 0 | 120 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 30 |
| · Design | · 具体设计 | 240 | 120 |
| · Coding | · 具体编码 | 900 | 1000 |
| · Code Review | · 代码复审 | 60 | 100 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 100 | 100 |
| · Test Report | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 180 | 100 |
| 合计 | 2610 | 3000+ |
【学习进度条】
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 138 | 138 | 36 | 36 | 复习了c++,了解了vs和git |
| 2 | 20 | 56 | 重新认识了mockplus的使用,需求分析、原型设计能力++ | ||
| 3 -5 | 600 | 738 | 30 | 86 | 学习了前端的基本知识,java技能++,结对作业,血量-- |