近几日,Js的学习进入到瓶颈阶段。在学习闭包这一章节时,我发现自己对于代码的底层运行原理其实理解的并不透彻,每当我试图解读一段代码时,总是陷入思维的怪圈,以至于学习进度滞后。为了以后能够更深入的学习,故在此,对闭包学习阶段的内容加以整理,希望在对知识进行梳理的同时,能够为其他同学的学习提供微小的帮助。
一: 基本类型和引用类型的值
在讲解内存空间之前,我们首先应该了解JS中,基本类型和引用类型值的概念。
ECMAScript中,包含两种不同数据类型的值。基本类型值 和 引用类型值。
- 基本类型:
JS中基本类型值有5种: Undefined、Null、Number、String和Boolean。基本类型数值是按值访问的,即我们可以直接操作保存在变量中实际的数值。基本类型值被复制时,复制的是值本身。
- 引用类型:
引用类型的值是保存在内存中的对象。引用类型数值是按引用访问的,即在操作对象时,我们实际上实在操作对象的引用或是指针(地址)而不是实际的对象。引用类型值被复制时,复制的是地址亦或是常说的指针。
除了保存方式的不同之外,基本类型值和引用类型值在复制时,也存在不同。
下面我们通过一个例子来更好的理解这两种类型值之间的区别:
- 基本类型:
var num1 = 5;
var num2 = num1;
console.log(num2); // 5
如果从一个变量向另一个变量复制基本类型值,会在变量对象上创建一个新值,然后把该值复制到为新变量分配的位置上。这个案例中的num1与num2是互相独立的,这两个变量可以参与任何操作而不相互影响。
我们来把代码改变一下:
var num1 = 5;
var num2 = num1;
num2 = 10;
console.log(num2); // 10
console.log(num1); // 5
在这段代码中,我们先声明了num1,并把其赋值给num2,后又为num2重新赋值为10。此时打印一下结果,发现num2为10,num1为5。在这个案例中,即使我们在后面改变了num2的值,num1的值也没有受到影响而改变。
- 引用类型
如果从一个变量向另一个变量复制引用类型的值时,同样也会将存储在变量对象中的值复制一份放到为新变量分配的空间中。但不同的是,这个值的副本实际上是一个指针,而这个指针指向存储在堆中的一个对象。复制结束后,两个变量实际上引用同一个对象。因此,改变其中一个变量,另一个也会受到影响而改变。
var obj1 = new Object();
var obj2 = obj1;
obj1.name = "Neil";
console.log(obj2.name); // "Neil"
此例中,obj1于obj2都指向同一个对象,所以为obj1添加name属性后,可以通过obj2来访问这个属性。
二: 两种类型值存放位置
了解了JS中两种类型的值之后,我们来聊一下这两类值被分配到内存中的什么位置。
- 数据存放位置
基本类型值存储在栈内存中,引用类型值存储在堆内存中。
下图可以帮我们更好的理解这两个概念。
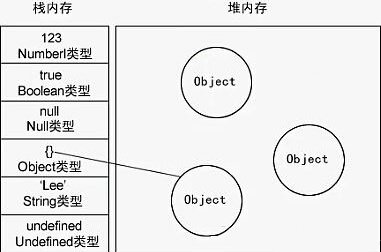
---引自网络---
通过上图,我们发现:
当我们要访问堆内存中的引用数据类型时,实际上我们首先是从变量对象(之后的章节会有讲解)中获取了该对象的地址引用(或者地址指针),然后再从堆内存中取得我们需要的数据。
所以,我们可以得到以上的结论。
- 堆栈运行数据结构的原理
简单理解栈的存取方式,我们可以通过类比乒乓球盒子来分析。如下图。
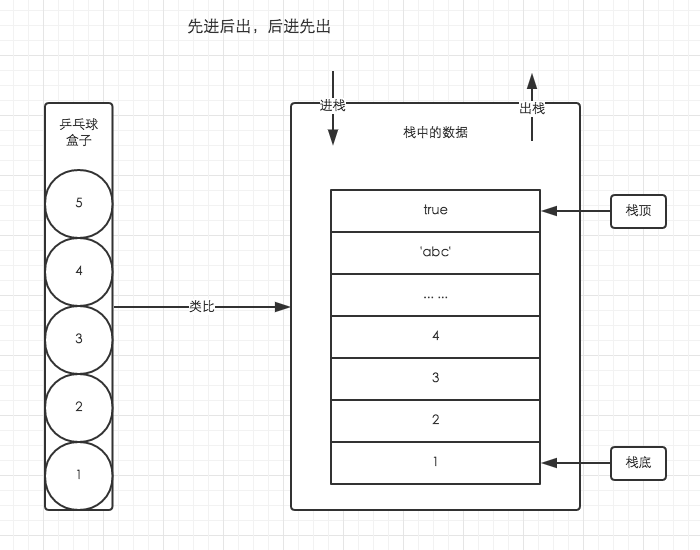
---引自网络---
进入堆栈的对象,遵循着先进后出的原则。如:处于盒子中最顶层的乒乓球5,它一定是最后被放进去,但可以最先被使用。而最先进入盒子的乒乓球1,它是最先被放进去的,但只能最后被使用。而在后面会被讲到的执行上下文在逻辑上也遵循着堆栈先进后出的原则。
三:为什么会有栈内存和堆内存之分?
通常与垃圾回收机制有关,为了使程序运行时占用的内存最小。
四:最后我们对堆栈的优缺点进行一下总结:
栈的优势:存取速度比堆快。
缺点:存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。
堆的优势:可以动态地分配内存大小,生存期也不必事先告诉编译器,垃圾收集器会自动地收走这些不再使用的数据。
缺点:由于在运行时动态分配内存,所以存取速度较慢。
所以相对于简单数据类型而言,他们占用内存比较小,如果放在堆中,查找会浪费很多时间,而把堆中的数据放入栈中也会影响栈的效率。比如对象和数组是可以无限拓展的,正好放在可以动态分配大小的堆中。