Supermarket
| Time Limit: 2000MS | Memory Limit: 65536K | |
| Total Submissions: 17974 | Accepted: 8071 |
Description
A supermarket has a set Prod of products on sale. It earns a profit px for each product x∈Prod sold by a deadline dx that is measured as an integral number of time units starting from the moment the sale begins. Each product takes precisely one unit of time for being sold. A selling schedule is an ordered subset of products Sell ≤ Prod such that the selling of each product x∈Sell, according to the ordering of Sell, completes before the deadline dx or just when dx expires. The profit of the selling schedule is Profit(Sell)=Σx∈Sellpx. An optimal selling schedule is a schedule with a maximum profit.
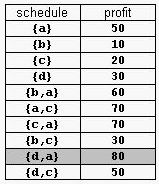
For example, consider the products Prod={a,b,c,d} with (pa,da)=(50,2), (pb,db)=(10,1), (pc,dc)=(20,2), and (pd,dd)=(30,1). The possible selling schedules are listed in table 1. For instance, the schedule Sell={d,a} shows that the selling of product d starts at time 0 and ends at time 1, while the selling of product a starts at time 1 and ends at time 2. Each of these products is sold by its deadline. Sell is the optimal schedule and its profit is 80.
Write a program that reads sets of products from an input text file and computes the profit of an optimal selling schedule for each set of products.
For example, consider the products Prod={a,b,c,d} with (pa,da)=(50,2), (pb,db)=(10,1), (pc,dc)=(20,2), and (pd,dd)=(30,1). The possible selling schedules are listed in table 1. For instance, the schedule Sell={d,a} shows that the selling of product d starts at time 0 and ends at time 1, while the selling of product a starts at time 1 and ends at time 2. Each of these products is sold by its deadline. Sell is the optimal schedule and its profit is 80.
Write a program that reads sets of products from an input text file and computes the profit of an optimal selling schedule for each set of products.
Input
A set of products starts with an integer 0 <= n <= 10000, which is the number of products in the set, and continues with n pairs pi di of integers, 1 <= pi <= 10000 and 1 <= di <= 10000, that designate the profit and the selling deadline of the i-th product. White spaces can occur freely in input. Input data terminate with an end of file and are guaranteed correct.
Output
For each set of products, the program prints on the standard output the profit of an optimal selling schedule for the set. Each result is printed from the beginning of a separate line.
Sample Input
4 50 2 10 1 20 2 30 1 7 20 1 2 1 10 3 100 2 8 2 5 20 50 10
Sample Output
80 185
Hint
The sample input contains two product sets. The first set encodes the products from table 1. The second set is for 7 products. The profit of an optimal schedule for these products is 185.
题目大意是超市卖n个商品,每个商品都有自己的截止时间dx和利润px,在截止时间之前都可以卖掉它,且每个单位时间只能卖一件。问最大获利。
【思路一:贪心】
一开始的想法是用贪心,把每个商品利润从高到低排序,保证利润高的能“先”卖出去(优先级高)。每个商品在截止时间那天卖出,如果有重复的就把时间往前推,直到找到第一个空出的时间卖掉。
写了个简单贪心,没有优化,POJ上耗时141MS,代码如下:
1 #include <iostream> 2 #include <cstring> 3 #include <cstdio> 4 #include <queue> 5 #include <algorithm> 6 using namespace std; 7 8 struct product{ 9 int px; //利润和截止时间 10 int dx; 11 }x[10005]; 12 13 bool cmp(product a,product b){ //根据利润从大到小排序 14 return a.px > b.px; 15 } 16 17 int main(){ 18 int n; 19 int table[10005]; 20 while(cin>>n){ 21 int sum = 0; 22 memset(x,0,sizeof(product)*10005); 23 memset(table,0,sizeof(table)); 24 for(int i = 0;i<n;i++) 25 scanf("%d%d",&x[i].px, &x[i].dx); 26 sort(x,x+n,cmp); //根据利润排序 27 for(int i = 0;i<n;i++){ 28 int tmp = x[i].dx; 29 if(!table[tmp]){ 30 table[tmp] = 1; //如果该时间单位为空,则占位 31 sum += x[i].px; 32 } 33 else{ 34 while(table[tmp]&&tmp>=1) tmp--; //如果该时间单位已满,则往找前第一个空的时间单位占位 35 if(tmp!=0){ 36 table[tmp] = 1; 37 sum += x[i].px; 38 } 39 } 40 } 41 printf("%d ", sum); 42 } 43 return 0; 44 }
【思路二:贪心+优先队列】
代码提交之后总觉得还会有别的更好的的方法,搜了搜大佬们的博客,发现了另一种贪心思路。“ 每卖一个产品要占用一个时间单位,所以,我们可以一个单位一个单位时间地依次决定,每个时间要卖哪个产品,并且保证每个单位时间卖出的产品都是利润最大的,这样便能保证最终结果是最大的。如果枚举时间从小到大的话,那么比较麻烦,更好的办法是从最后一个截至时间开始往前枚举, 这样的话,只要把截止时间大于等于这个时间段的产品都放入优先队列,其中利润最大的便是这时间所要的。 “
这个思路是用贪心+优先队列实现的,我也敲了一遍,POJ耗时63MS,代码如下:
1 #include <iostream> 2 #include <cstdio> 3 #include <cstring> 4 #include <queue> 5 #include <algorithm> 6 using namespace std; 7 8 struct product{ 9 int px; //利润和截止时间 10 int dx; 11 }x[10005]; 12 13 bool cmp(product a,product b){ //根据截止时间从大到小排序 14 return a.dx > b.dx; 15 } 16 17 priority_queue<int,vector<int>,less<int> > q; //从大到小排列 18 19 int main(){ 20 int n; 21 while(~scanf("%d",&n)){ 22 int sum = 0; 23 for(int i = 0;i<n;i++){ 24 scanf("%d%d",&x[i].px, &x[i].dx); 25 } 26 sort(x,x+n,cmp); 27 int pos = 0; //下标 28 while(!q.empty()) q.pop(); //清空q 29 for(int i = x[0].dx;i>=1;--i){ 30 while(pos<n && x[pos].dx == i){ //如果有相同截止时间的 31 q.push(x[pos++].px); //把截止时间相同的利润都放进优先队列 32 } 33 if(!q.empty()){ 34 sum+=q.top(); //把队列中利润最大的(即第一个)加进总和里,然后从队列中删去,队列中剩下的一定是截止时间大于等于下一个商品的 35 q.pop(); 36 } 37 } 38 printf("%d ", sum); 39 } 40 41 return 0; 42 }
【思路三:贪心+并查集优化】
看到的第三种思路实际上是第一种思路的优化,用到了并查集。一个商品可以在它的截止时间之前卖出,且一个时间只能卖一个商品。所以从后往前,找到商品的截止时间之前的第一个空位,并在当天卖出,然后标记那天已被占用。当时间被占用时,把当天时间标记为它的前一个时间,表示下次搜索空位时直接从前一个位置搜索。用并查集优化,在往前搜索空位的过程中,途中经过的所有位置都直接标记到最后搜到的那个空位上去,这样再次搜索这些点前面的空位时,可直接从上一次搜到的空位开始往前搜。这次的代码POJ耗时47MS,代码如下:
1 #include <cstdio> 2 #include <cstring> 3 #include <iostream> 4 #include <algorithm> 5 using namespace std; 6 7 const int N = 10005; 8 struct product{ 9 int px,dx; 10 }x[N]; 11 bool cmp(product a,product b){ 12 return a.px > b.px; //根据利润从大到小排序 13 } 14 15 int f[N]; 16 int find(int x){ //找截止时间前空着的时间,返回从后往前找到的第一个 17 if(f[x] == -1) return x; //如果当前时间未被占用,直接返回 18 return f[x] = find(f[x]); //当前时间已被占用,从它标记处从后往前开始搜,并把搜到的第一个空位直接标记给它和中间经过的点 19 } 20 21 int main() 22 { 23 int n; 24 while(cin>>n){ 25 memset(f,-1,sizeof (f)); //全部初始化为-1,表示空位(此处不可初始化为0,否则在find步骤会产生影响) 26 for(int i = 0;i < n; i++) 27 scanf("%d%d",&x[i].px,&x[i].dx); 28 sort(x,x+n,cmp); 29 int sum = 0; 30 for(int i = 0; i < n;i++){ 31 int t = find(x[i].dx); //找到当前物品截止时间前空着的时间 32 if(t>0){ //找到的空着的时间单位不为0 33 sum += x[i].px; 34 f[t] = t-1; //表示当前时间已被占用,下次搜索直接搜前一个时间是否为空 35 } 36 } 37 printf("%d ",sum); 38 } 39 40 return 0; 41 }
总结:并查集确实是个好东西,在学会的同时也不能死套模板,能把它用到实处才是真正的理解。希望下次可以自己写出更好的优化!