1、下载solr :wget http://archive.apache.org/dist/lucene/solr/7.3.0/solr-7.3.0.tgz 或者去官网自己下:http://archive.apache.org/dist/lucene/solr/ 找下面图片字样点进去选版本
2、解压solr 命令:tar -zxvf solr-7.3.0.tgz -C /usr/local/software/ -C指定解压到的路径
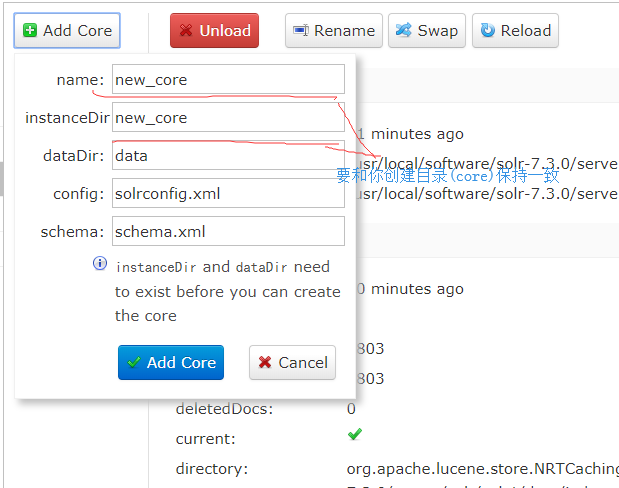
3、启动solr 命令: bin/solr start -force 在此之前有两种做法 (1、直接启动 但会报错 它会创建一个目录 2、先创建目录,再添加core 这里要注意下图两个位置要和你创建的core名保持一致)
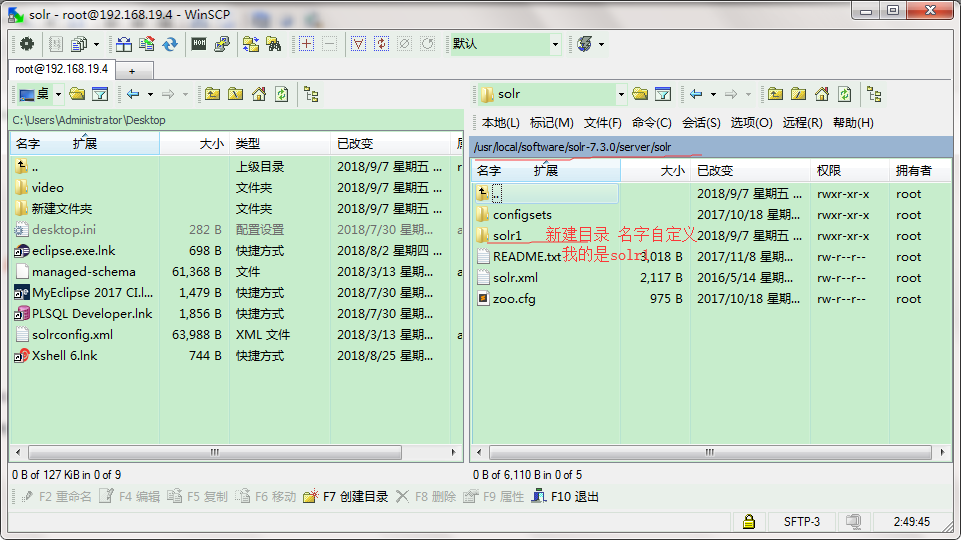
3.1 找到如下路径新建一个目录 没有ftp 就用命令进入解压solr位置下的/ server/solr 创建自定义目录 这个目录就等价于4.10.3下solrHome下的core
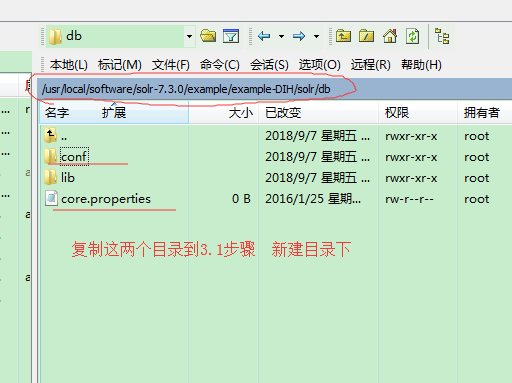
3.2 复制如下路径的两个文件夹到 3.1 步骤 (example-DIH里面有db mail solr 配置都可以使用 注意conf目录里面的东西看下图)
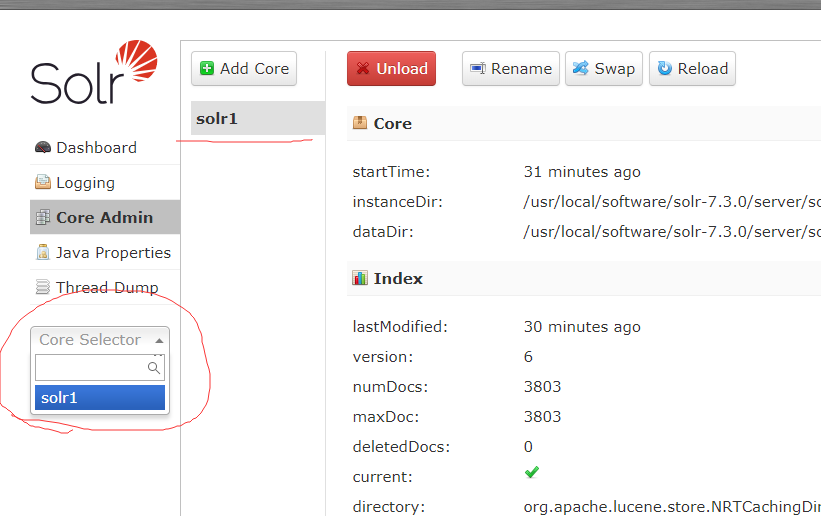
重启 命令:./solr restart -force 以上sorl基本配置就完成了 验证是否成功 看下图就行 如果没有表示的地方说明没成功
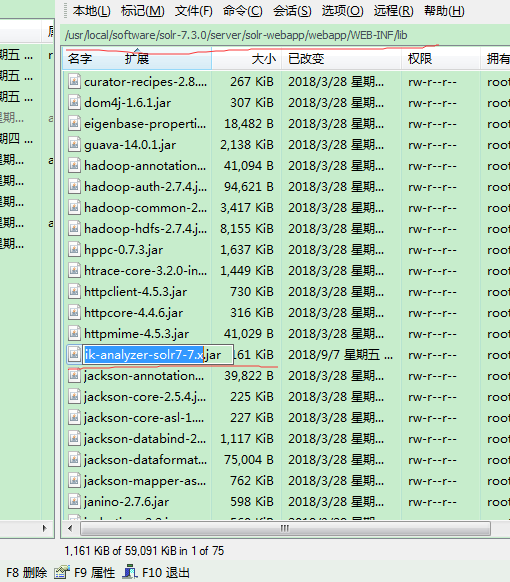
4、配置中文分析器 下载中文分析器ik-analyzer-solr7-7.x.jar 添加到 /usr/local/software/solr-7.3.0/server/solr-webapp/webapp/WEB-INF/lib 下 据说有自带的不知道怎么配置 地址:https://jar-download.com/download-handling.php
5、打开managed-schema 配置配置如下代码
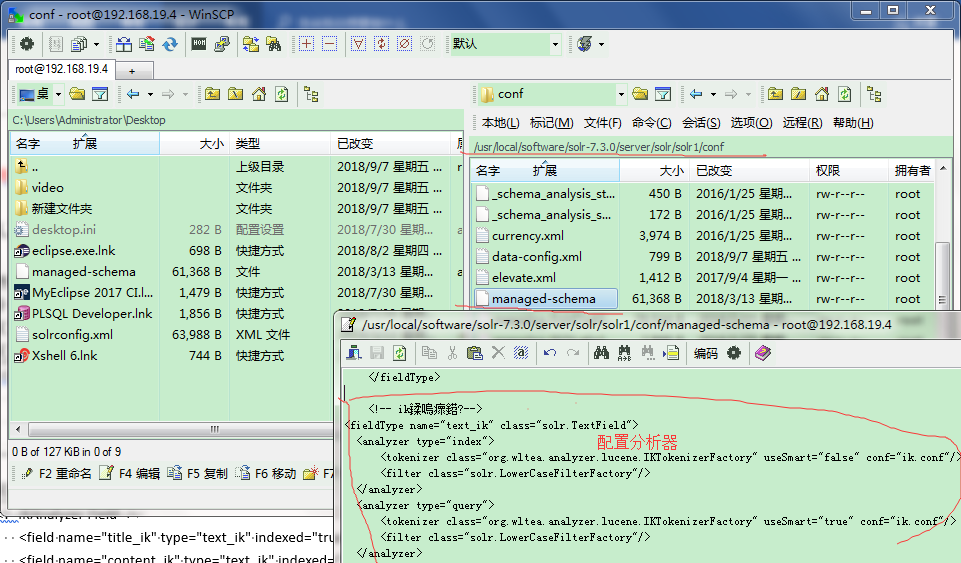
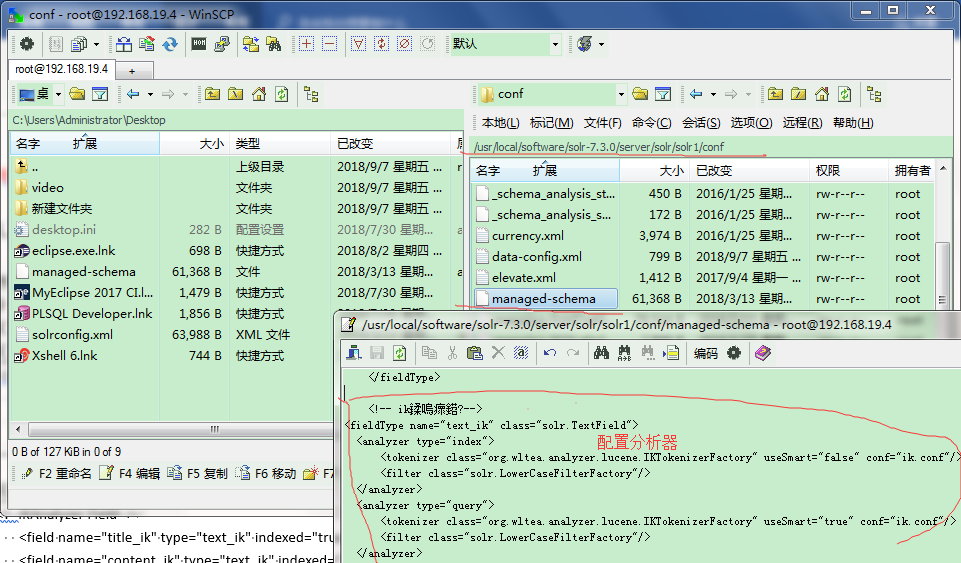
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
6、重启solr 命令:bin/solr restart -force
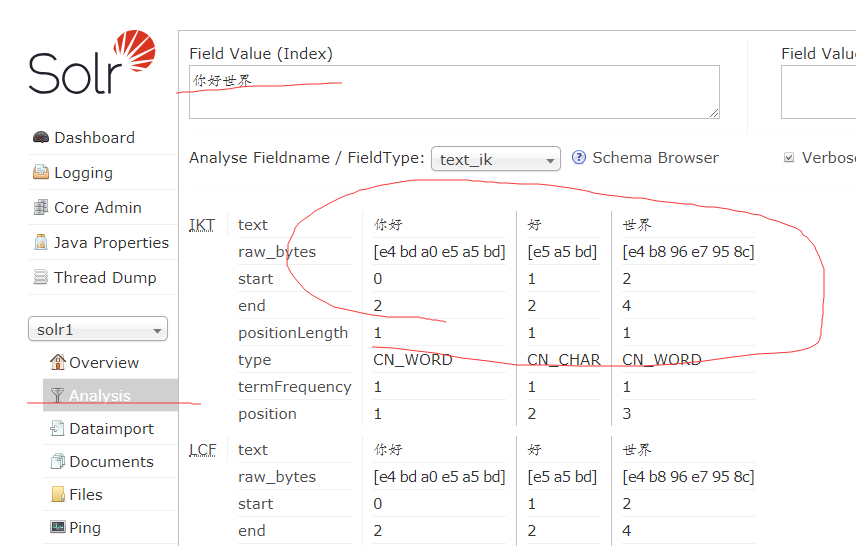
7、配置mysql solr-dataimporthandler-7.3.0.jar 和 solr-dataimporthandler-extras-7.3.0.jar 和mysql-connector-java-5.1.46.jar放到solr-7.3.0/server/solr-webapp/webapp/WEB-INF/lib
mysql自己下 solr-dataimporthandler-7.3.0.jar 和 solr-dataimporthandler-extras-7.3.0.jar 在/solr-7.3.0/dist下面有复制到solr-7.3.0/server/solr-webapp/webapp/WEB-INF/lib(这样就不用手动引架包了)
8、进入你创建的core/conf 打开solrconfig.xml 命令:vi solrconfig.xml 在requestHandler 最后面添加以下代码即可
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
9、在同级目录下创建 data-config.xml 内容如下
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/solr" user="root" password="root"/> <document> <entity name="product" query="SELECT pid,name,catalog,catalog_name,price,description,picture FROM products "> <field column="pid" name="id"/> <field column="name" name="product_name"/> <field column="catalog" name="product_catalog"/> <field column="catalog_name" name="product_catalog_name"/> <field column="price" name="product_price"/> <field column="description" name="product_description"/> <field column="picture" name="product_picture"/> </entity> </document> </dataConfig>
10、 编写managed_schema
managed_schema里面定义了很多域,其实是使用了lucene中的域。
什么是域?域的作用是定义一个solr索引里面的字段是什么类型,能做什么,怎么做。有点类似数据库中字段的类型。但表示的含义更加的丰富。
在managed_schema后面添加如下代码:
<!--product-->
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_catalog" type="string" indexed="true" stored="true"/>
<field name="product_catalog_name" type="string" indexed="true" stored="true" />
<field name="product_price" type="pfloat" indexed="true" stored="true"/>
<field name="product_description" type="text_ik" indexed="true" stored="false" / >
<field name="product_picture" type="string" indexed="false" stored="true" />
<field name="product_keywords" type="text_ik" indexed="true" stored="false" mult iValued="true"/>
name是这个域的名称,在整个managed_schema文件里面需要唯一,不能重复,这里定义成跟数据库表字段的名称,方便使用。当然,也可以定义成其他名字。
type是表示这个字段的类型是什么,string是字符串类型,int是整形数据类型,date是时间类型,相当于数据库里面的timestamp。
indexed表示是否索引,索引的话就能查询到,否则,搜索的时候,不会出现。
stored表示是否存储到索引库里面。
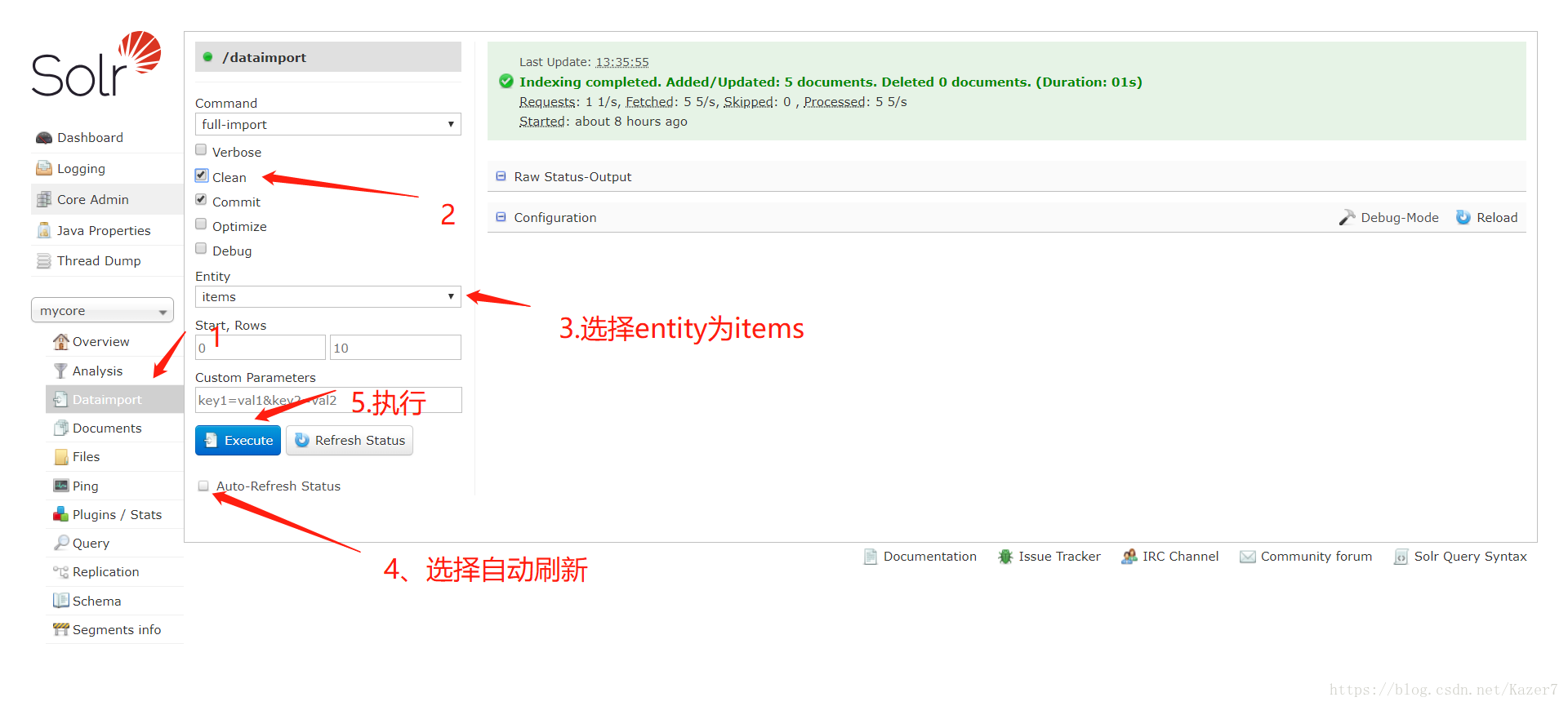
11、测试是否成功
12、停止solr 命令:bin/solr stop -all
13、卸载solr 直接删除solr根目录 重启虚拟机