参考课程地址:https://www.bilibili.com/video/av65548392?p=24(哔哩哔哩视频教程)
一、Hbase 简介
hdfs 是分布式文件系统, 只支持在文件层面的增、删除、改(需要把文件下载下来,改完,再上传上去)、查
hbase 是支持海量数据存储的NoSql数据库,基于hdfs的,支持数据的增、删、改、查,支持随机写数据(改指定的某一条数据)
hbase 查询数据只能根据rowkey进行检索
namespace ——命名空间:相当于数据库名,一个命名空间下可以有多张表
二、Hbase的表结构、存储原理
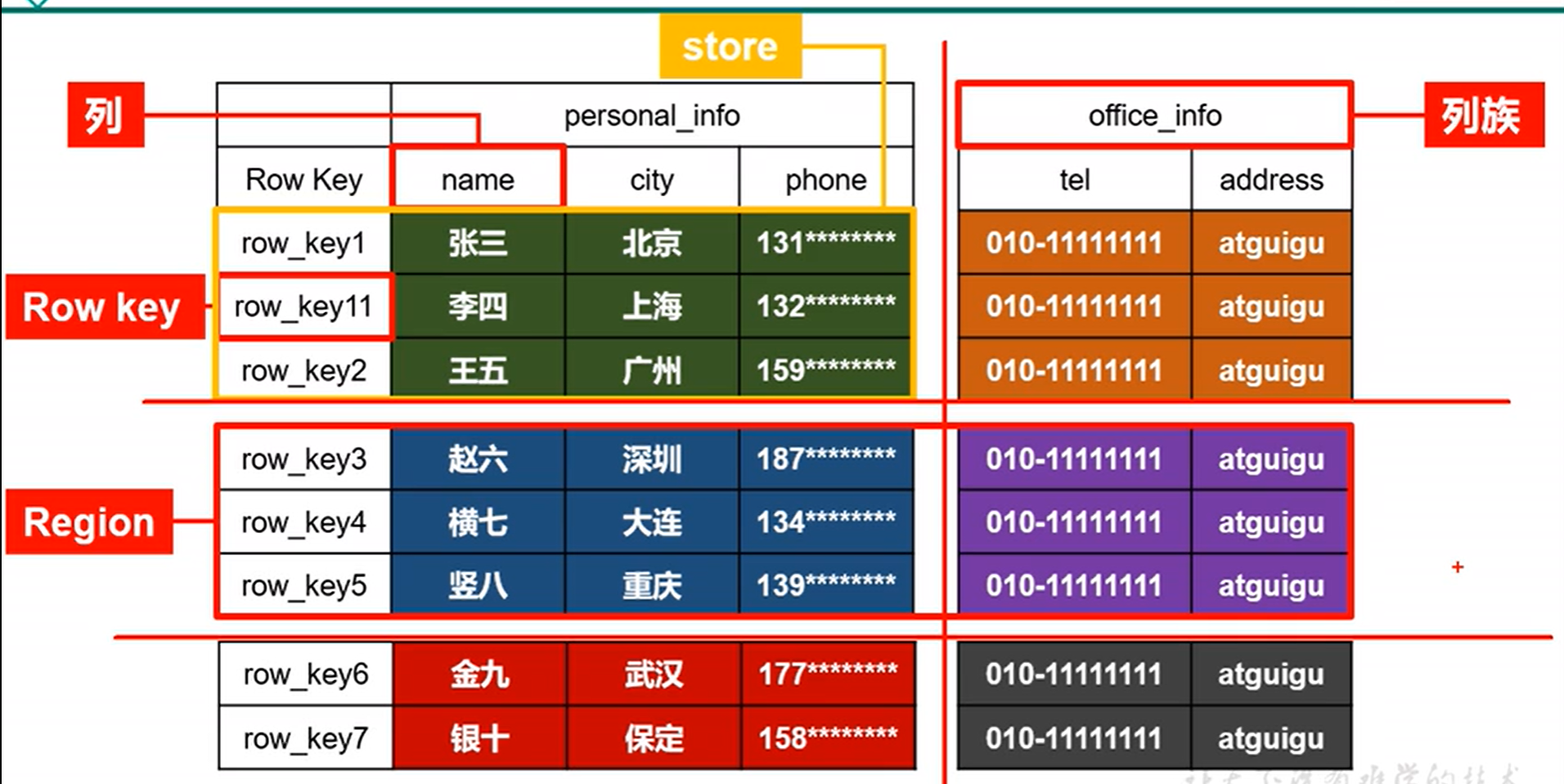
Bigtable,————高表、宽表,支持海量数据的存储
rowkey,————行键,在一张表中是唯一的,插入一行数据必须要有rowkey
列族——包含多个列,一个列族存为一个文件, 纵向切割
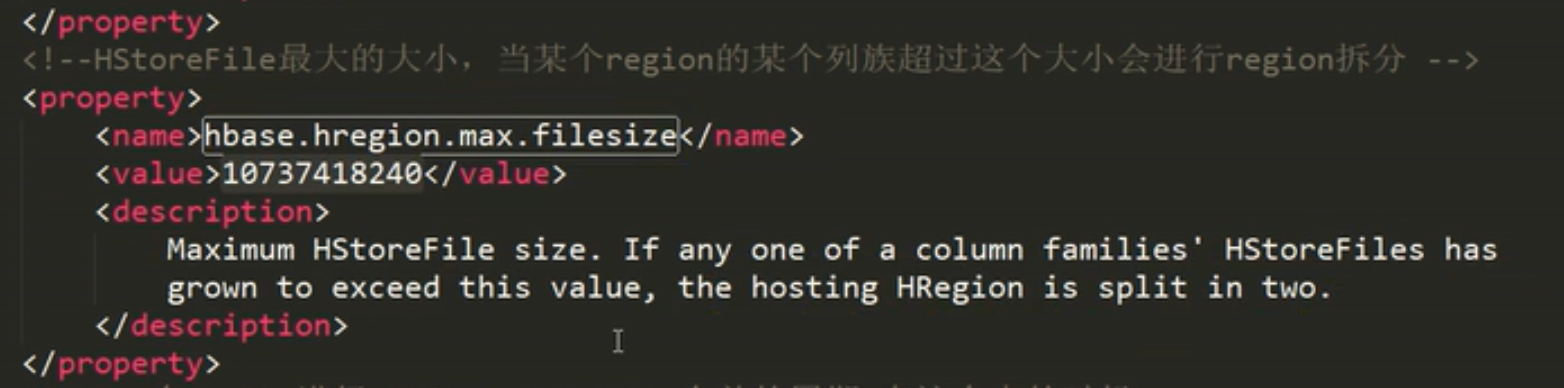
Region————横向的切片,数据量大时,会把一张表横向切割成, 多个Region, 一个region存一个文件
hbase是基于hdfs存储的数据库:
namespace → table → region → 列族,
一级代表一个文件夹,层层深入 (可以在hdfs管理页面中浏览文件)
三、hbase的物理存储结构

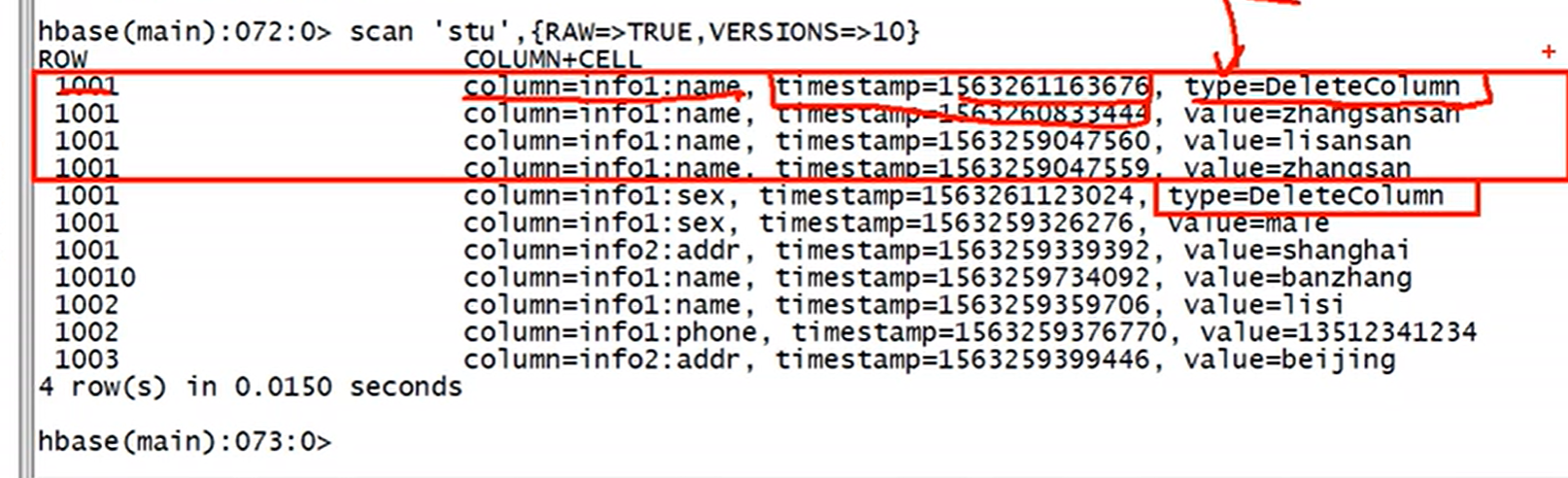
查询返回的数据是时间戳大的版本。
时间戳大的版本类型为delete, 则不返回该条数据。
四、基本概念
namespace ——命名空间:相当于数据库名,一个命名空间下可以有多张表

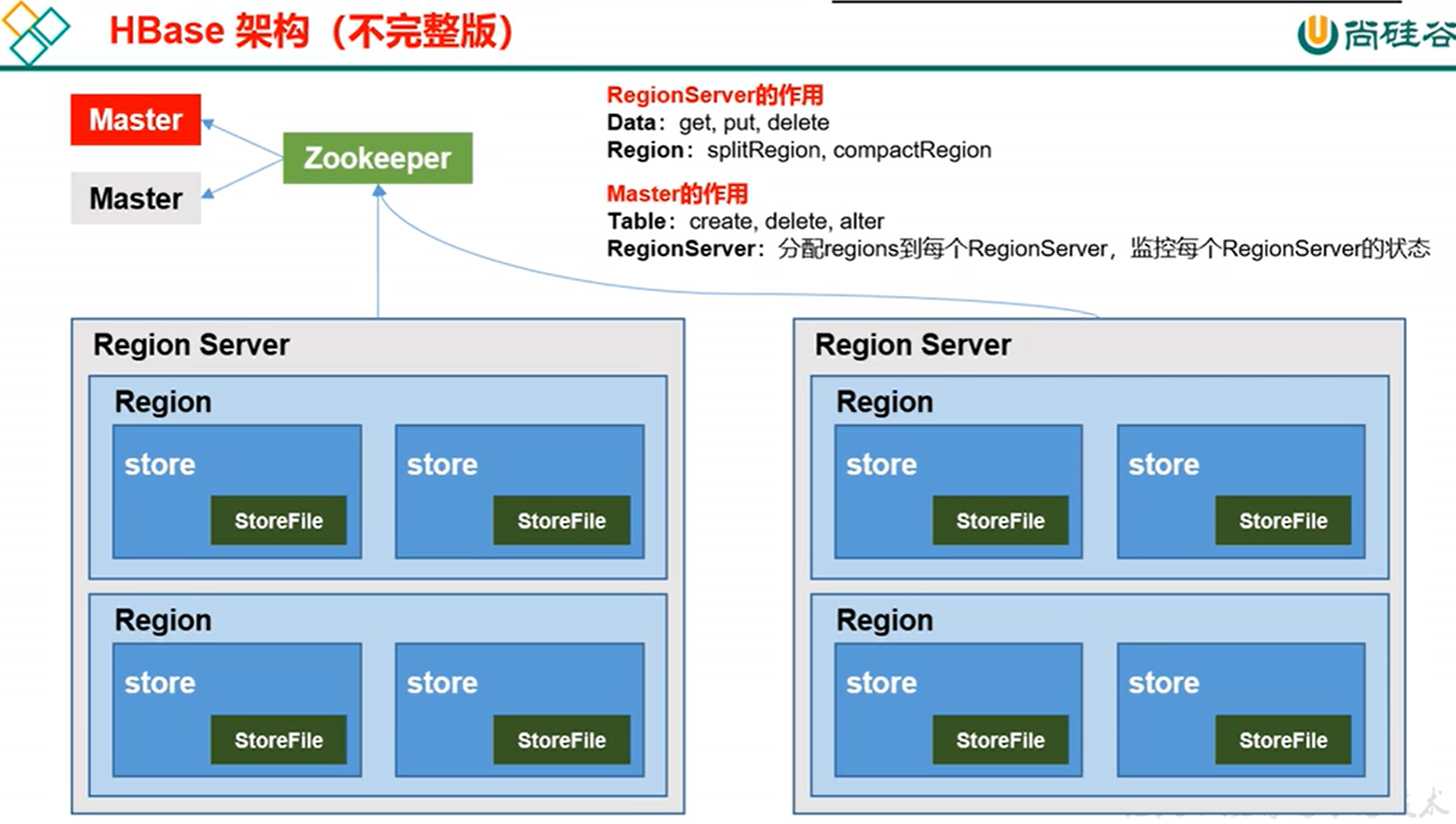
五、Hbase 基本架构
HMaster: 管理表的增删改,监控regionserver状态,调度region,DDL
RegionServer:管理数据的增删改,DML
启动Hbase: 需先启动zookeeper, hdfs
六、Hbase 集群部署
参考:https://www.bilibili.com/video/av65548392?p=7
也可以参考:
https://blog.csdn.net/weixin_33991727/article/details/85815994
https://www.cnblogs.com/daleyzou/p/8568502.html
https://www.linuxidc.com/Linux/2016-11/137303.htm
七、hbase的启动、停止

启动HMaster :
./hbase-daemon.sh start master
启动regionserver :
./hbase=daemon.sh start regionserver
启动集群:
./start-hbase.sh
七、hbase shell 命令
以cell为单元操作,即某表、某行、某列、某timestamp
help
(一) 表的增、删、改、查

1.创建表
create 'student','info'
create 'student','info','work'
说明:‘表名’,‘列族1’,‘列族2’
2.查看表
list
说明:列出所有表
describe 'student'
说明:查看表结构,有哪些列族,保存几个版本
3.修改表
alter 'student',{NAME=>'info',VERSION=>3}
说明:需要指定列簇,保存几个版本,默认是1
4.删除表
disable 'student'
drop 'student'
说明:需要先disable, 才能删除表成功
(二)数据的增、删、改、查(重点!)

1.增加数据(4个参数,‘表名’,‘rowkey’,‘列族:列名’,‘值’)
增加数据是1个cell, 一个cell的添加
put 'argus:student','1001','info:name','张三'

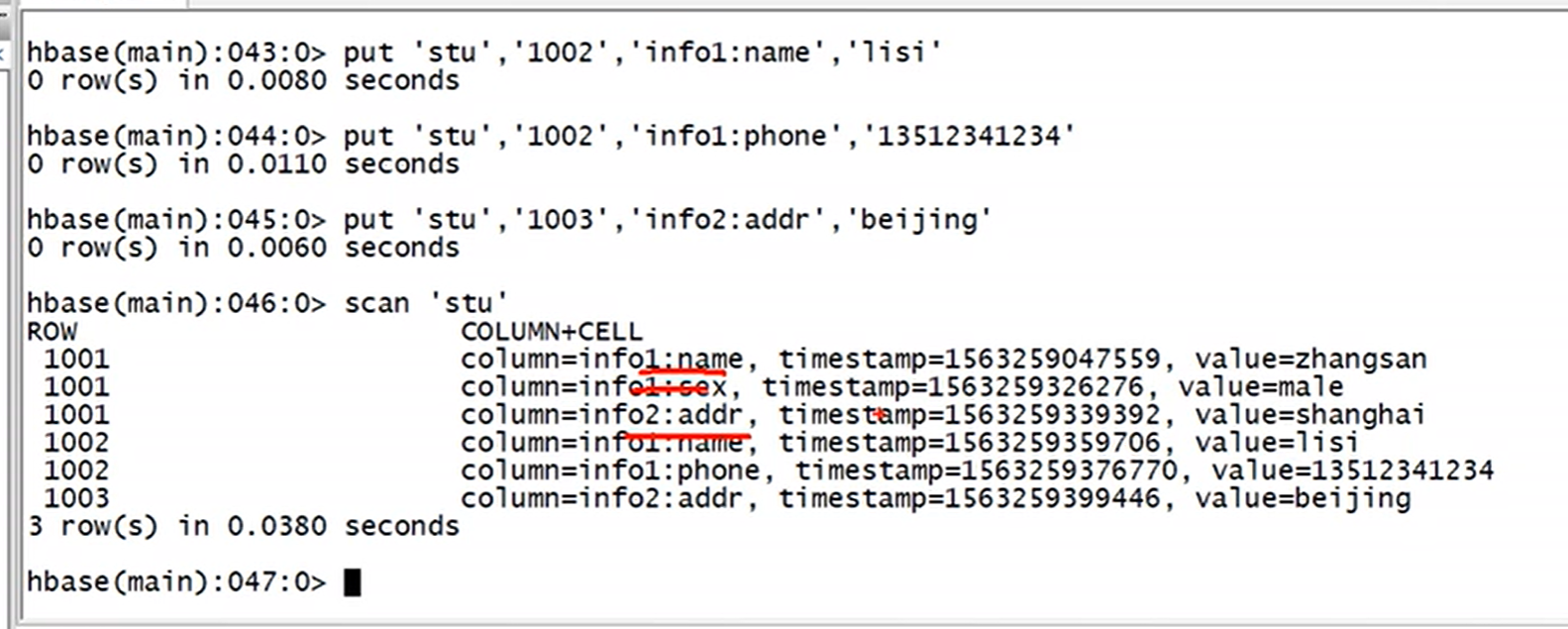
说明:put '命名空间名:表名', 'rowkey', '列族名:列名',‘value’
也可以在后面加时间戳,插入某一个版本的数据
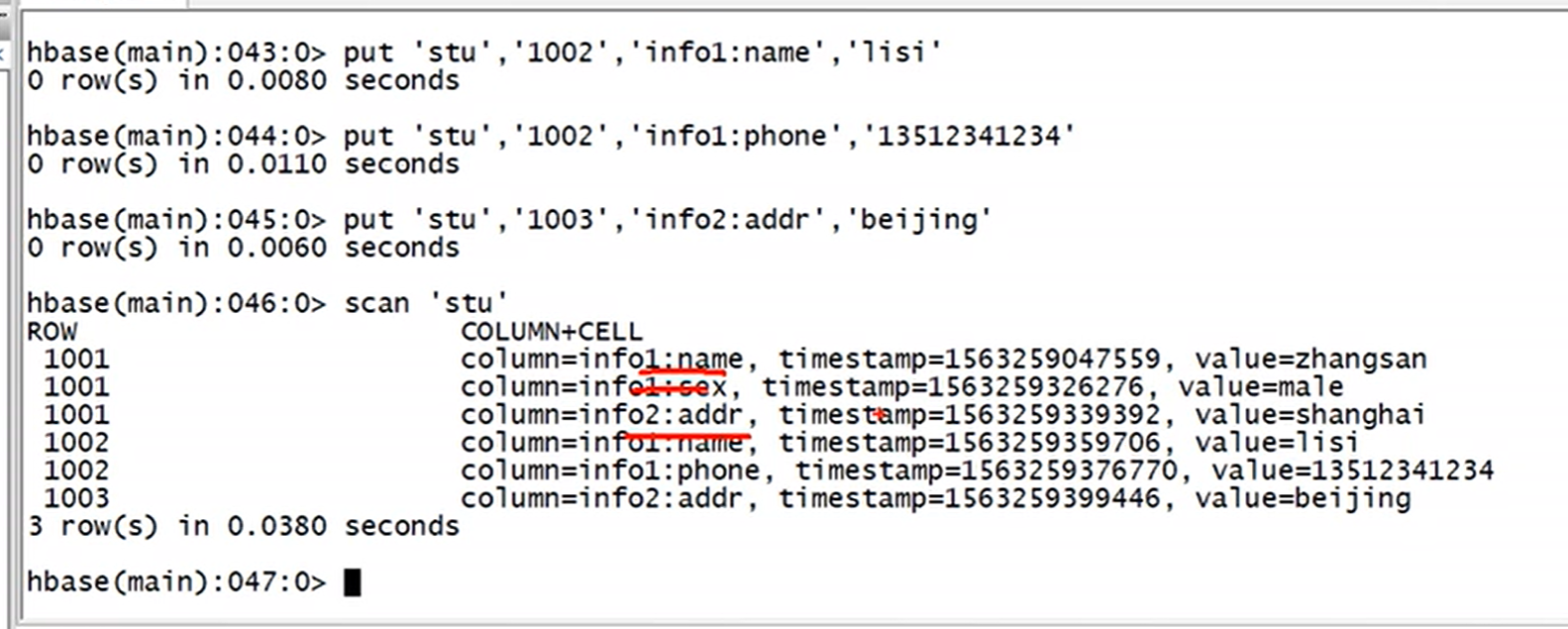
2.查看表数据
scan 回车,即可看到使用举例

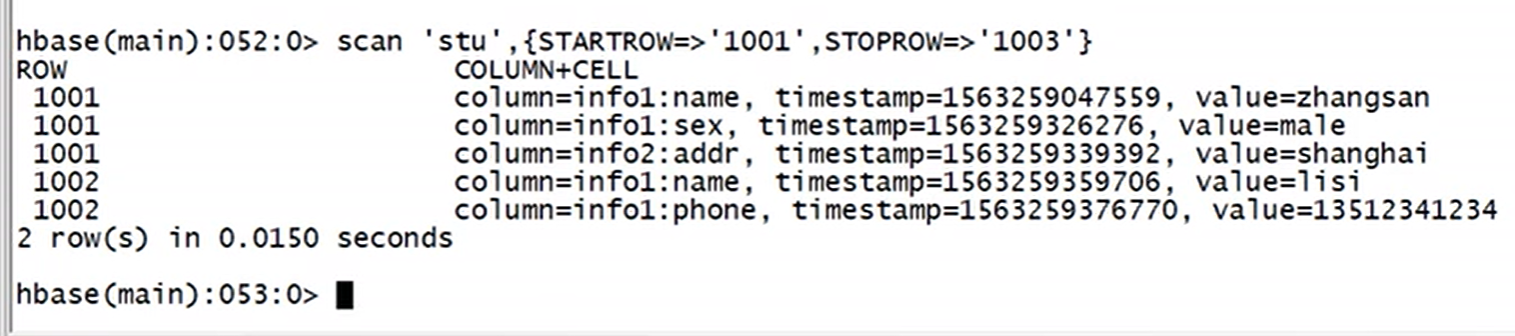
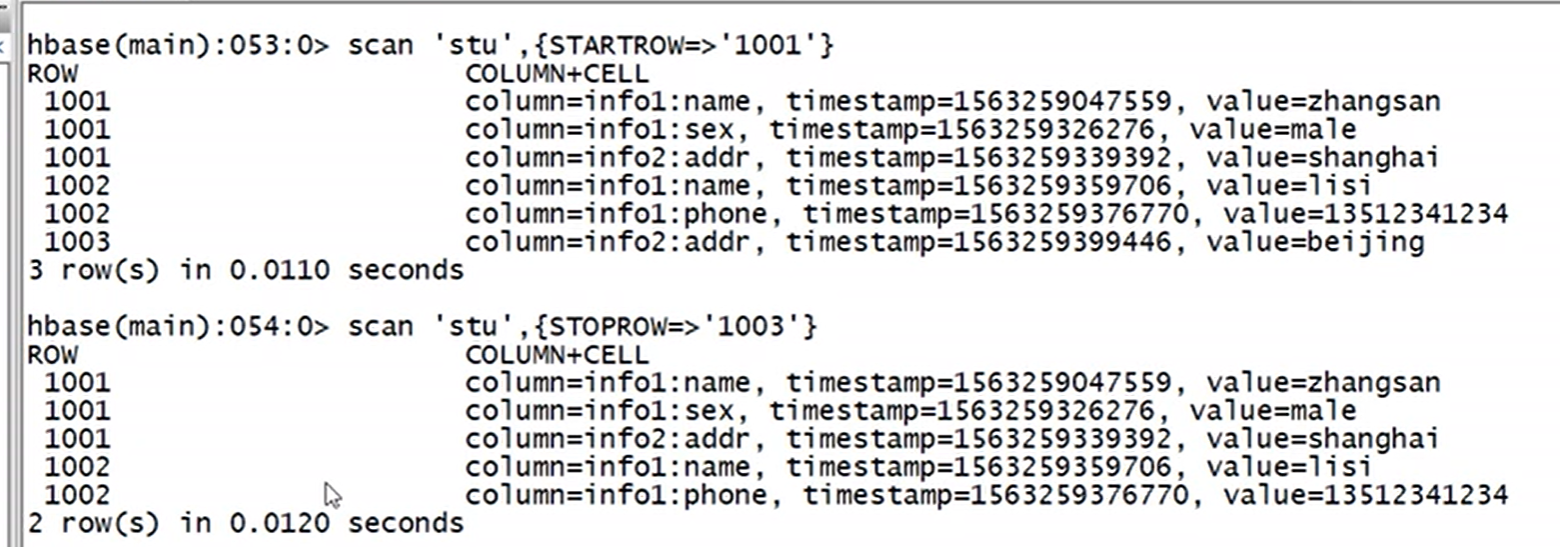
上图说明:scan是左闭右开区间
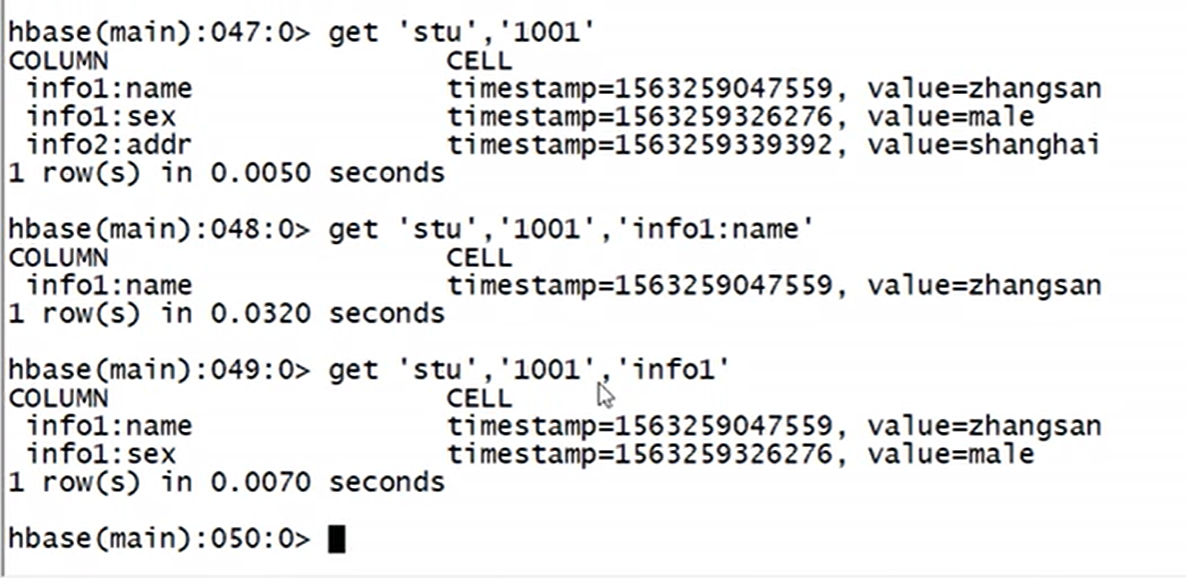
get 回车,查看使用举例,(hbase只能根据rowkey查询)

get查询至少需要2个参数(表名,rowkey)
get 'argus:student','1001'
get 'argus:student','1001','info:name','info:age'
get 'student','1001',{COLUMN=>'info:name',VERSIONS=>3}
3.修改数据
put 'argus:student','1001','info:name','李四'
put 'argus:student','1001','info:name','王五',时间戳
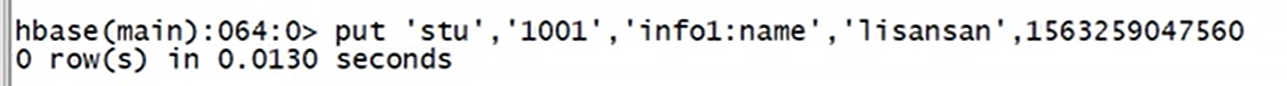
修改后,可以用以下命令查看10个版本以内的数据

注意:修改和增加,都用put
4.删除数据

删除数据至少需要3个参数
delete 'student','1001','info:name'
delete 'student','1001','info:age'
会把该表,该行,该列的cell的所有版本都删了, get查询数据就不会再返回了
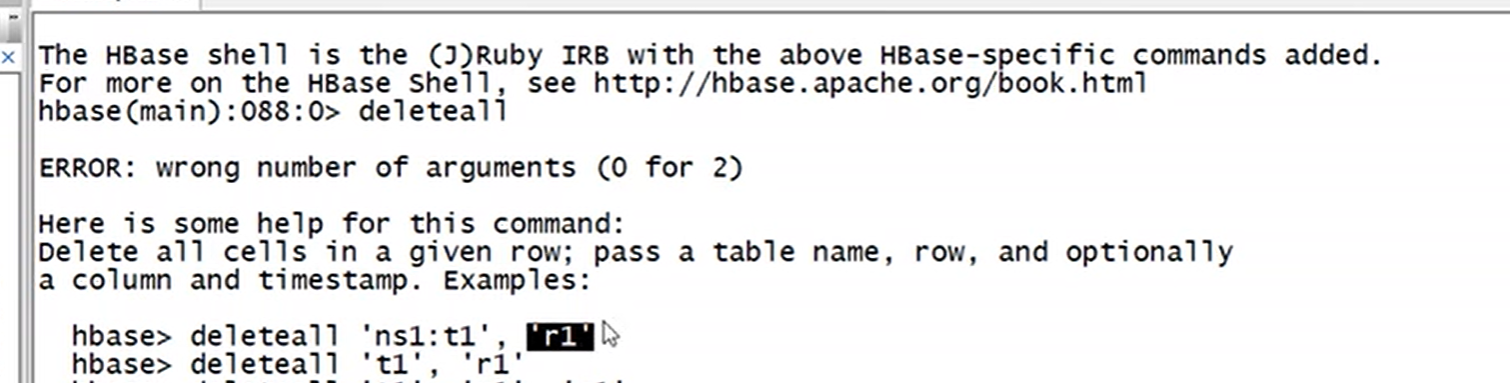
deleteall 'argus:student','10001'
注意:deleteall 是删除rowkey,删除rowkey对应的那一行数据
truncate 'argus;student'
注意:truncate 是清空表数据,步骤也是自动先disable该表,再清空表数据
(三)命名空间的增、删、改、查

1.查看命名空间
list_namespace
2.创建命名空间
create_namespace 'argus'
补充:在命名空间argus里创建表alter,
create 'argus:alert'
3.删除命名空间
drop_namespace 'argus'
注意:命名空间为空,才能删除成功。所以要先删除该命名空间下的表
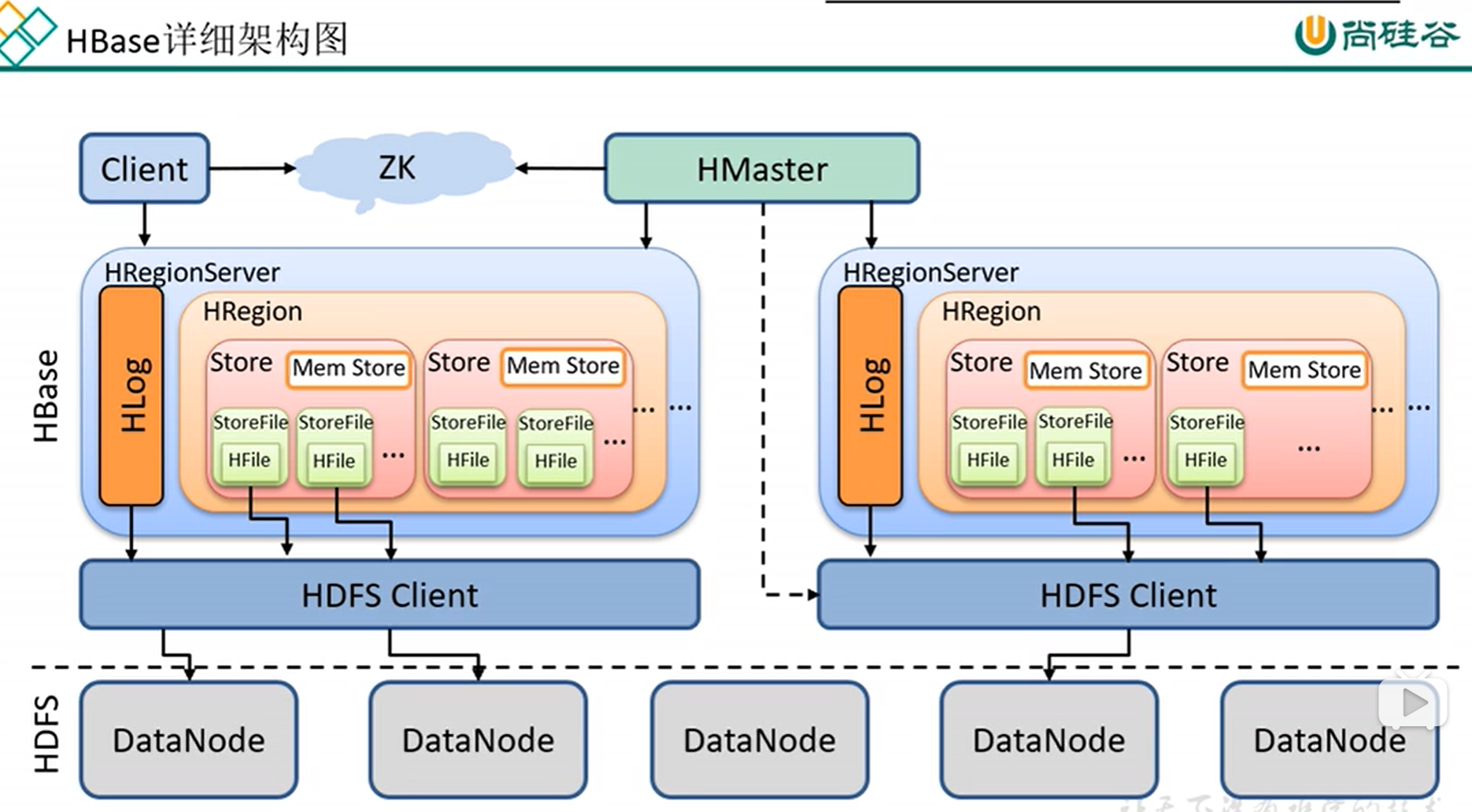
八、Hbase详细架构图
Hlog ————相当于hdfs的edit.log, 预写入日志,恢复数据用的,防止regionserver挂了,数据还在内存中
内存
磁盘
数据先放入内存中,配置一个小时、或者数据到多少条后,再flush (刷洗)到磁盘中
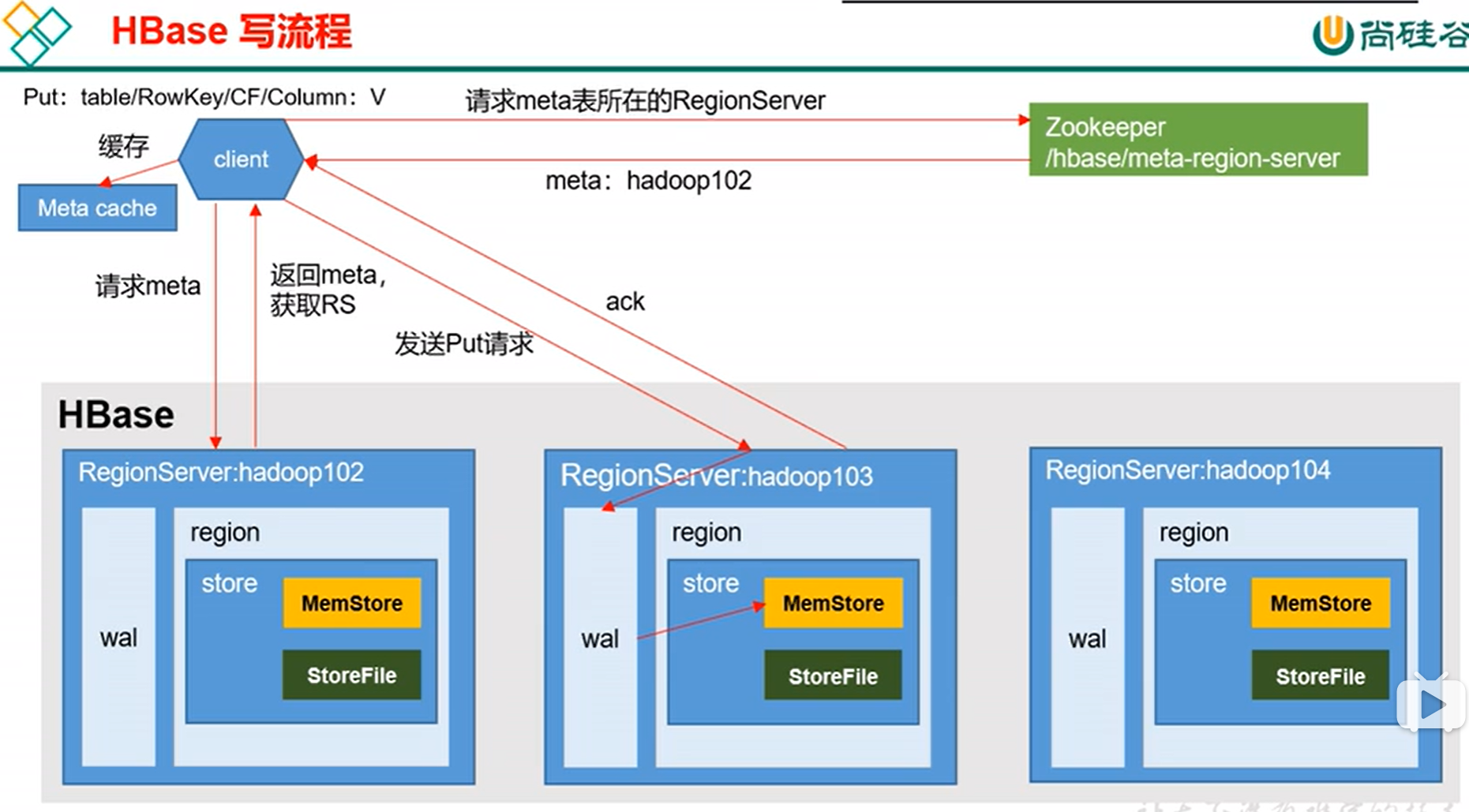
九、Hbase写流程
Hbase是一个读流程没有写流程快的框架
meta表保存的是所有表在哪个regionserver(某表的哪些rowkey到哪些rowkey,在哪个regionserver, 一个表可以有多个region,特别是数据量大时),
从zk获取meta表位置后会缓存起来,下次就不用去zk找meta表在哪个regionserver上了
找到meta表后,找到要插入的表在哪个regionserver管理后就朝上面插入数据,
先写到wal, 再写到内存中,然后再同步wal, 如果同步失败(机器挂了),则内存回写rollback, 该条数据就不会插入成功

十、mysql与Hbase
mysql Hbase
数据库 Namespace
表 Region(数据量大时,一个表可以有多个region, 横向切割)
列 列族(column family)
数据 列+数据(cell)
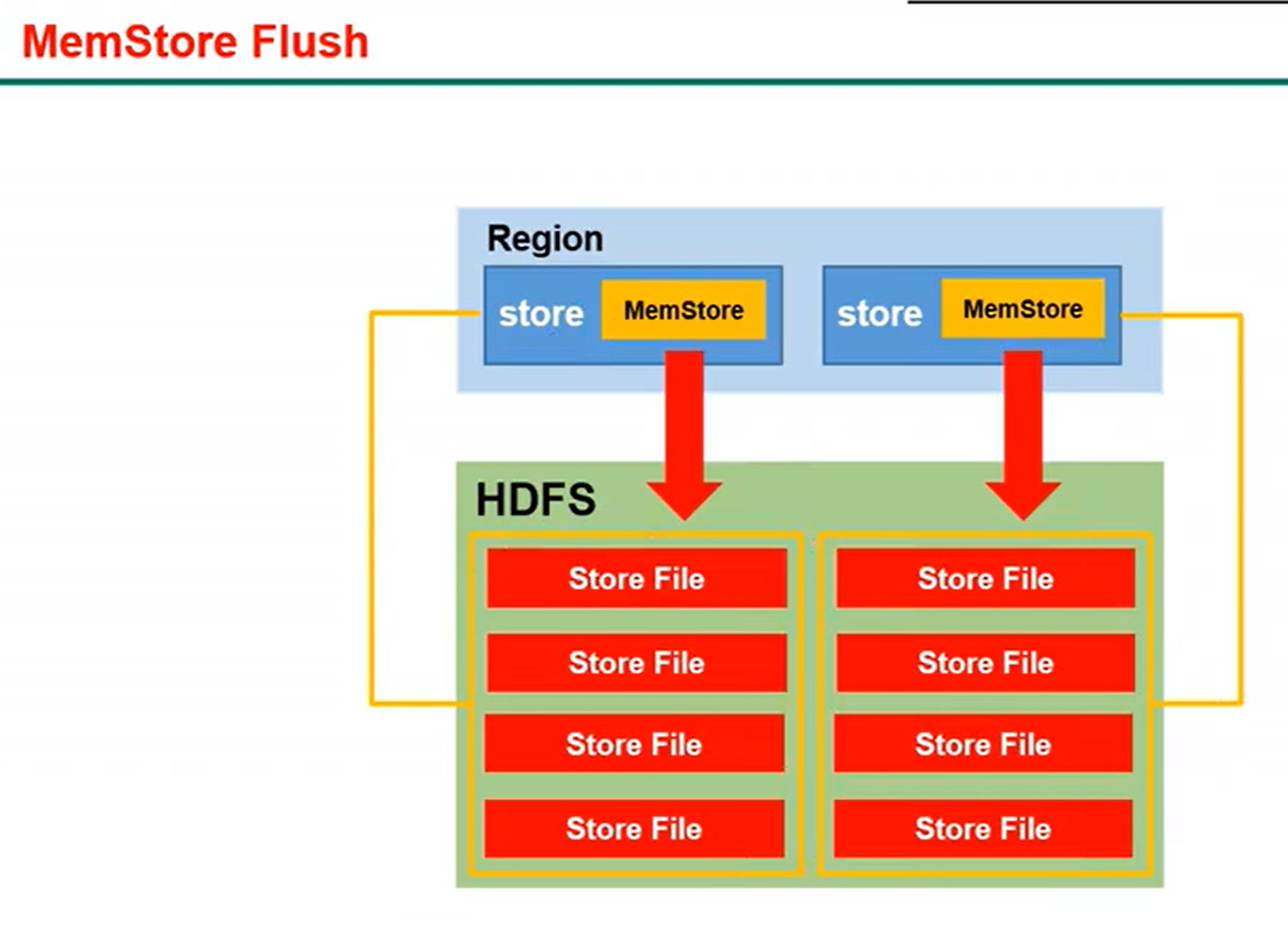
十一、memstore flush流程
同一个region的多个store存的是不同列族,
一个列族存为一个文件,
方便查找数据,get 'stu','1001','name:age'
注意:flush操作会阻塞用户端读写,因为不阻塞的话,会导致内存爆掉
手动刷写命令:flush 'stu3'
以上命令即可把内存的数据立刻手动刷写到磁盘,在hdfs中可看见。
十二、Hbase读流程
说明:前面读取元数据meta的步骤,和缓存Meta的步骤和写流程一致
后面读具体数据的步骤:同时读内存、磁盘的数据,并merge, 比较时间戳大的数据,返回时间戳大的数据,并把磁盘中读到的数据缓存到Block cache中
下次如果再读同一条数据,则同时读内存、Blockcache数据,比较快。
memStore, 缓存cache都是存在内存中的
Store File 格式为Hfile, 是存在磁盘中的


十三、Hbase的compact流程, 文件的合并

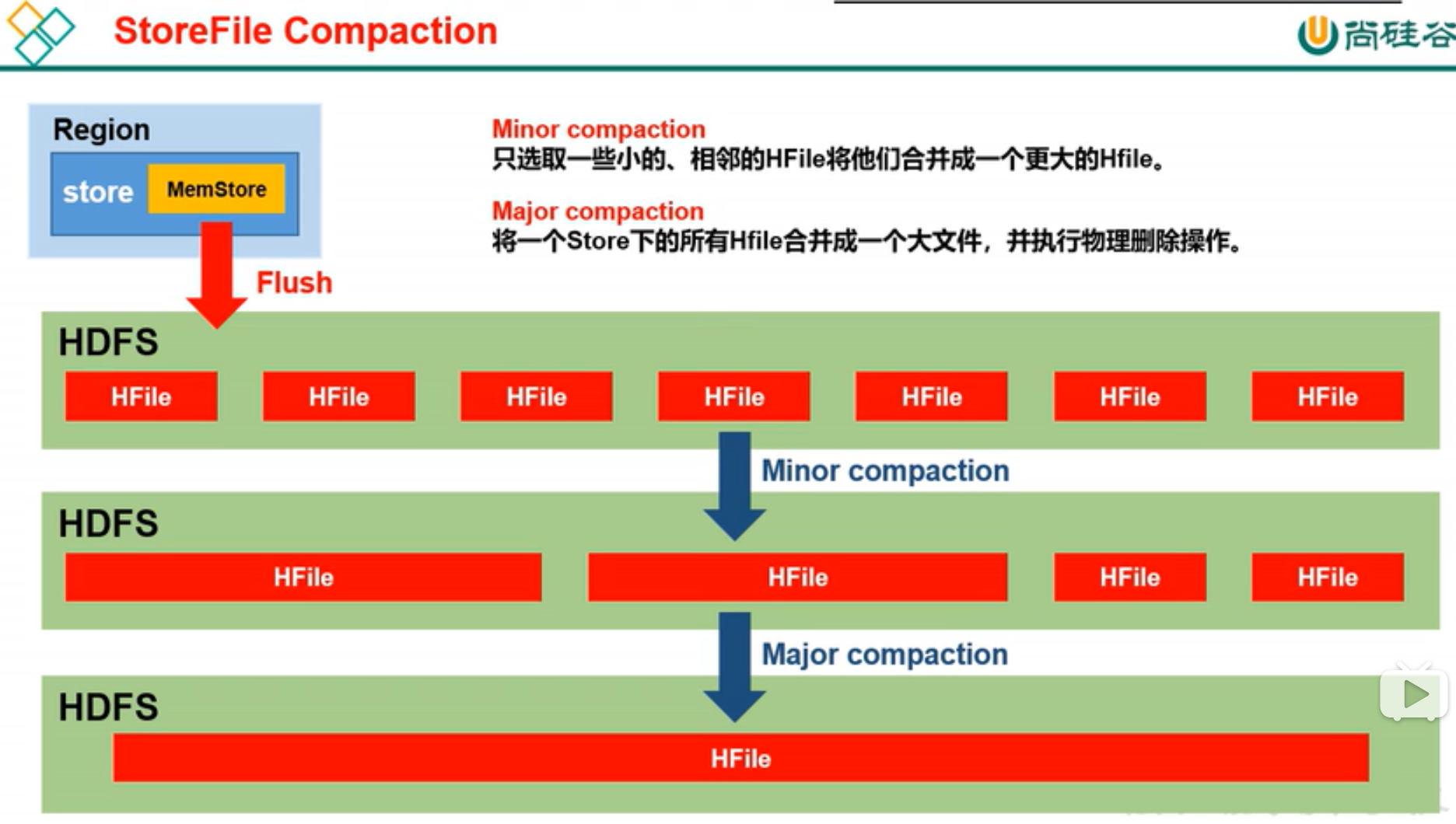
说明:合并及全部读出来再进行重写到一个大的Hfile中,非常耗资源,所以生产上不要配置7天合并一次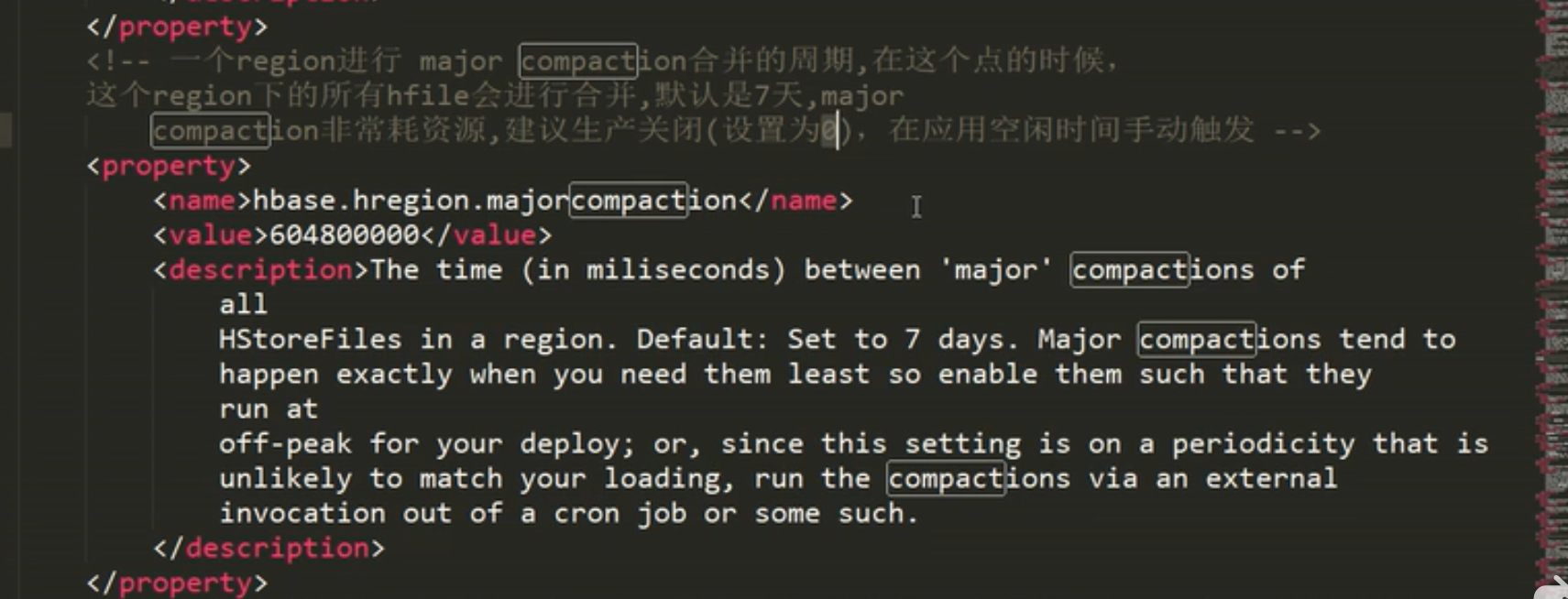
配置了如下后:就可 compact 'stu3'
通过命令行手动合并文件,可看到在hdfs中生成了一个新文件,2-3分钟后老文件也被删除
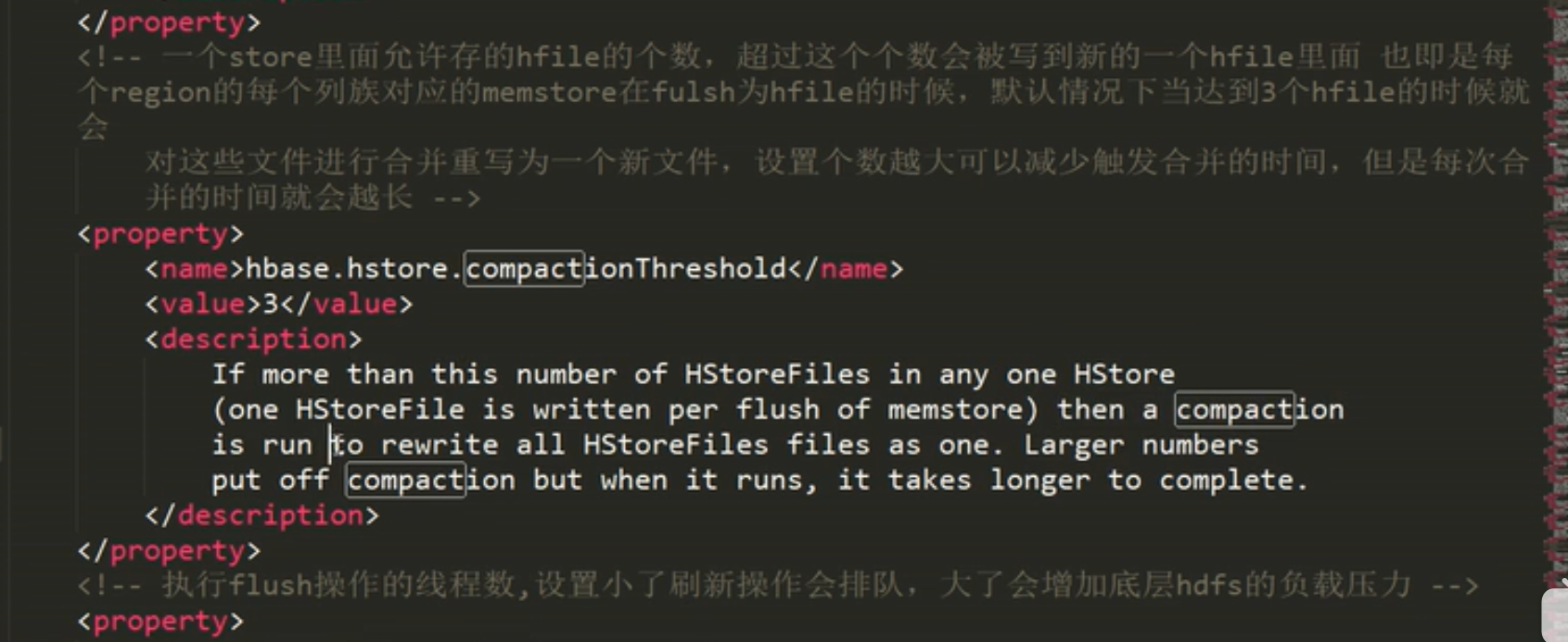
超过3个文件数, 则手动进行 compact 'stu4', 相当于major compact
十四、hbase真正删除数据的时间
说明:flush 只会删除内存中过期的数据,无法删除已经在磁盘存在的数据
compact 会删除磁盘文件中过期的数据,以及删除标志(scan 'stu4', 可以看到标记type=delete被删除了)
十五、Hbase的split流程
说明:split即某一个列族数据量较大时,按照rowkey范围把一个表横向切割成几个region
官方建议:建表时,尽量只是用一个列族,避免flush时产生太多小文件