2019年2月25日 周一晚 -2019-02-28 10:17:11 总结了3天。
一、关系型数据库、非关系型数据库
数据采集 +消息中间件 + 数据计算+数据存储=数据管理
| 关系型数据库 | 非关系型数据库 |
| 举例:mysql | 举例:hbase |
| 节省空间 | 占空间大 |
| 计算量大 | 计算量小 |
| join | NOSQL, 没有join |
| 各种左连接、右连接、多表连接,才能查询出想要的数据 | 大宽表,一亿列都没问题 |
| 查询慢 | 查询快 |
| 千万条数据OK, 上亿条就很慢了 | 上亿条也OK, 快,适用于大数据量、高性能 |
| 行存储,一行一行的读,且必须整行读,才能抽取出想要的字段的值,select XXX from YYY表 where .....(先去找到这个表,当where后有6千万条数据,80列时,读取数据就会比较慢了) | 列存储,大宽表,一列存为一个文件,需要什么数据,根据rowkey直接拿某一列就行,速度快,且支持文件压缩,一列若是6G的数据,可以压缩成2G的数据,再拿出来解压 |
| 优点:没有冗余数据 | 有冗余数据 |
| primary key | rowkey, 列簇 |
| 关键字总结:节省空间、计算大、join、primary key 、整行读、支持复杂查询(千万级别的数据,更适用于小的操作,落地的数据) | 关键字总结:占空间大、计算小、no join、列簇、rowkey、大宽表、一亿列OK、一列存为一个文件、n列存为n个文件、支持文件压缩(6G→2G)、上亿级别的数据(适用于大块的操作) |
| 补充:phoenix + Hbase 可以组成关系型数据库,凤凰 |
另一种典型的非关系型数据库:Neo4J , 图形数据库
| 非关系型数据库 | ||
| Neo4J | ||
| 图形数据库 | ||
| 适用于图谱关系 | ||
| 1条线,2个点就是一条数据,表示一对1:1的关系 | ||
| 整个数据库可以是一张很大的图 | ||
|
例如微信朋友圈,总共有8千万用户,要查询我的朋友W的朋友S的朋友Y的朋友 有哪些,就需要person join person on L2=L1 |
||
| 10亿 | person join person | |
| 60亿 (10*10=100亿) | person join person | |
| 120亿 | person join person | |
| 300亿 | person join person | |
|
1000亿,10000亿,Neo4J来处理这种图谱关系的数据就非常快, 如果让MySQL来处理这种数据就很慢了,可能一天一一夜都跑不完 |
||
| Neo4J朋友圈表示例如右图所示:两点一线 | T | W |
| T | Z | |
| T | L | |
| W | S1 | |
| Z | S2 | |
| L | S3 | |
| S1 | K | |
| S1 | P |
二、数据库
数据库:负责数据计算、数据存储,两方面统称为数据管理
事务:增、删、改,不包括查,对数据库的一次操作、或者一次修改称为一个事务
事务的四大特性:
| 原子性 |
任务的执行只有成、与不成,没有办成不成,执行到一半,那就是不成,不会改动数据 (不会只改动S-AGE, 不改动S-Name, 如果一条语句要求同时改age, name的话,那就是要么全都修改成功,要么全都修改失败) |
| 隔离性 |
读未提交、不可重复读、可重复读、串行化 (隔离性从low -------→ High) |
| 一致性 | 对用户的一致性,7点的时候,A去读, B去读,C去读,同一条数据都是1,2,3 |
| 永久性 | 数据存储、日志存储 |
事务的隔离性:每一个事务,都可以去定制它的隔离性,具体的业务需求不同,隔离级别也不同
| 事务隔离级别 | 脏读 | 说明 | 适用场景 | 隔离级别 |
|
读未提交(read-uncommitted) |
是 |
A在修改一条数据,且未提交时,B可以去读这条数据,且读出来的是A修改后的值, 这个是脏读,因为A可能改了没有提交,又rollback回去了,那B读到的数据就是错的, |
打电话时,查话费;上网时,查流量;这些都是实时的,不会等你打完(30分钟,或者1小时后,再扣除),上网完才能查 | 最低 |
| 不可重复读(read-committed) | 否 | A 7点时去读是450,B修改数据为400并提交后,A 7点10分再去读,数据就是400了 | 次低 | |
| 可重复读(repeatable-read) | 否 |
A 7点时去读是450,B修改数据为350并提交后,A 7点10分再去读,读到的数据仍然是450 (因为可重复读拿到的是过去那个点读到的数据,是过去版本的数据),此时A-50, 数据就变为了300, 因为减是拿最新数据去操作 |
历史告警卡片中绑定的告警规则,告警规则可修改; 巡检页面,巡检签到时的值要求和刷新后,巡检时看到的值一致; | 次高 |
|
串行化(serializable) |
否 | 一个事务接一个事务接一个事务的串行话执行,必须一个事务执行完了才能去执行下一个事务 |
银行系统,交易流水系统,必须一个事务执行完了才能去执行下一个事务,否则就会出现流水出问题,比如下单购物,待支付, 如果这个时候就去读余额扣除10元,就会脏读,因为用户可能取消支付了,查余额发现被扣了10元,就会找银行麻烦。 |
最高 |
三、实时数据 flink、伪实时数据 spark (数据计算)
flink 1s内,连续不断的采,真实时数据;
spark 把1s划分成0.1,0.01,0.001秒,短暂到感觉不到,采,不采,采、不采,采,不采,采,不采......得到的是伪实时数据;
(需要根据具体业务场景,系统性能考虑,选用实时、还是伪实时更好;)
| spark架构 | spark SQL | 用SQL写的spark 核心 |
| spark core | spark 的核心 | |
| spark streaming | ||
| 结构化 streaming | ||
| mllib 机器学习 | ||
| graph图库分布式 |
参考文章:https://www.cnblogs.com/zdz8207/p/hadoop-spark-flink.html
Spark是一种快速、通用的计算集群系统,Flink是可扩展的批处理和流式数据处理的数据处理平台。至于Flink,其对于流式计算、迭代计算支持力度更强。
Spark和Flink都支持实时计算,且都可基于内存计算(spark是伪实时的分片技术,只能按每秒分片技术,不能每条数据都实时技术,flink和storm可以)。
Spark, flink 都是基于内存计算,Map Reduce是基于磁盘计算(hadoop 3.0 MR 改为了基于内存计算),前两者性能、计算速度明显高于MR.
hadoop架构图、spark架构图、flink架构图、spark生态系统图、flink生态系统图,见参考文章链接。
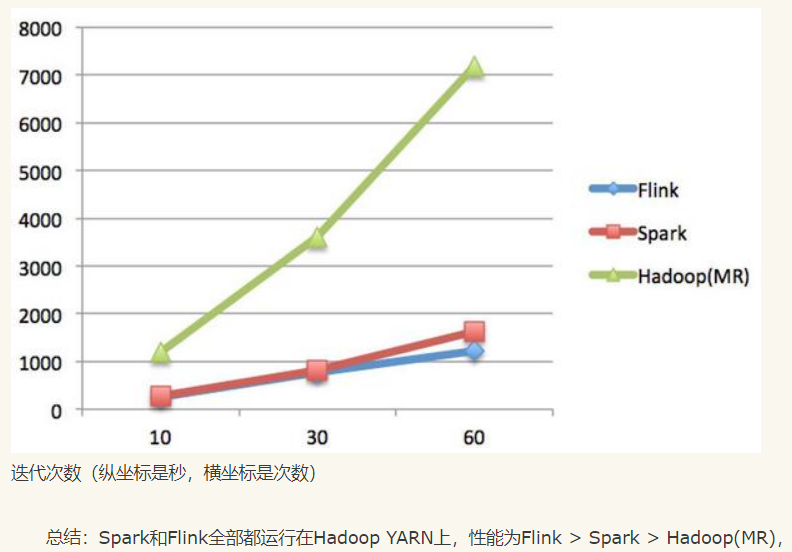
总结:Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
它们都支持流式计算,Flink是一行一行处理,而Spark是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
Spark对SQL的支持比Flink支持的范围要大一些,另外Spark支持对SQL的优化,而Flink支持主要是对API级的优化。
| flink | spark |
| 真实时数据 | 伪实时数据 |
| 流式计算、迭代计算更强的流式数据处理平台 | 快速、通用的计算集群系统 |
| 伪实时分片技术 | |
| 支持毫秒级计算 | 支持秒级计算 |
| 对SQL支持范围更大 | |
| 对Hadoop兼容性更好 | |
| 迭代计算次数越多,性能更好,优于spark | |
| 都支持实时计算(真实时、伪实时) | |
| 都支持流式计算(毫秒级、秒级) | |
| 都基于内存计算 | |
| 都运行再hadoop yarn 上 |
四、hive 和 hbase的区别 (数据存储)
参考文章1:https://www.cnblogs.com/justinzhang/p/4273470.html
参考文章2:https://www.cnblogs.com/xubiao/p/5571176.html
| hive | hbase |
| 离线数仓 | 实时数仓 |
| 都是架构在hadoop之上的。都是用hadoop(HDFS)作为底层存储。 | 都是架构在hadoop之上的。都是用hadoop(HDFS)作为底层存储。 |
| HQL是一种类SQL语言,这种语言最终被转化为Map/Reduce | Hbase的能够在它的数据库上实时运行,而不是运行MapReduce任务。 |
| 表分区 | 列簇,rowkey |
| 全表扫描 | 索引查询 |
| hive查询时间长 | hbase查询时间短 |
|
运行Hive查询会花费很长时间,虽然有这样的缺点,一次遍历的数据量可以通过Hive的分区机制来控制。分区允许在 数据集上运行过滤查询,这些数据集存储在不同的文件夹内,查询的时候只遍历指定文件夹(分区)中的数据。这种机制 可以用来,例如,只处理在某一个时间范围内的文件,只要这些文件名中包括了时间格式。 |
|
| Hive帮助熟悉SQL的人运行MapReduce任务 | HBase通过存储key/value来工作。 |
|
Hive目前不支持更新操作。另外,由于hive在hadoop上运行批量操作,它需要花费很长的时间, 通常是几分钟到几个小时才可以获取到查询的结果。 |
Hbase支持四种主要的操作:增加或者更新行,查看一个范围内的cell,获取指定的行,删除指定的行、列或者是列的版本。 版本信息用来获取历史数据(每一行的历史数据可以被删除,然后通过Hbase compactions就可以释放出空间)。 虽然HBase包括表格,但是schema仅仅被表格和列簇所要求,列不需要schema。Hbase的表格包括增加/计数功能。 |
|
为了运行Hbase,Zookeeper是必须的,zookeeper是一个用来进行分布式协调的服务,这些服务包括配置服务, 维护元信息和命名空间服务。 |
|
|
应用场景:Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。 Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。 |
应用场景:Hbase非常适合用来进行大数据的实时查询。Facebook用Hbase进行消息和实时的分析。 它也可以用来统计Facebook的连接数。 |
|
Hive是一种类SQL的引擎,并且运行MapReduce任务 |
Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库 |
|
这两种工具是可以同时使用的。Hive可以用来进行统计查询,HBase可以用来进行实时查询, 数据也可以从Hive写到Hbase,设置再从Hbase写回Hive。 |
|
| hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序。 |
hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且 克服了hdfs在随机读写方面的缺点。 |
| hive难在sql | hbase难在表结构的设计 |
|
Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。 hive需要用到hdfs存储文件,需要用到MapReduce计算框架。 |
hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。 hbase是列存储。hdfs作为底层存储,hdfs是存放文件的系统,而Hbase负责组织文件。 |
|
简单、好实施 |
更难上手、维护成本高 |
|
数据量、实时度、计算规模,不同,选择hive或者hbase, 二者都具有很强的数据存储、计算能力 |
|
|
关键字总结:离线数仓、全表扫描、表分区、查询时间长、写Hql(类sql语言)来运行map reduce任务, 简单、好用、好实施,实时度不高,适合统计查询 |
关键字总结:实时数仓、索引查询、查询快、Nosql的 key/value数据库,列存储,rowkey, 列簇, 实时度高,适合实时查询 |
五、kafka, flume 的区别
参考文章:
https://www.cnblogs.com/ibyte/p/5830715.html
https://blog.csdn.net/qq_41610418/article/details/82796966
https://blog.csdn.net/gyshun/article/details/79710534
kafka 消息中间件
消息队列中间件,解决数据抖动的问题,如交易高峰期数据陡增(如平常只有几十个订单,高峰期有几千个订单,就没必要浪费服务器资源按照几千个的最高峰值来配服务器,用kafka来做缓存就行)
1G
4G
10G
50G
10G
当生产者生产数据速度 > 消费者消费数据速度, kafka 就会以消息队列缓存,一部分一部分给消费者去计算、存储。
需要自己编写“生产者、消费者”,可以给多个消费者去消费
flume 分布式日志采集系统
flume重点在采集,由一个或者多个 flume agent 组成,flume 没有副本,若一个flume agent节点挂了,则数据就丢失了,需要恢复磁盘才能找回,而kafka有类似hadoop这样备份三份的机制,更可靠,数据不易丢失。

flume agent 的内部采用的是source, chanel, sink 的模式,可以有多个生产者 , 最后集中存储到HDFS, HBASE里。
二者可以组合使用, 如果数据最后要存储到 HDFS, HBASE, 就可以用 kafka + flume (kafka source)
如果数据可以用flume采集,不想自己写采集系统,就可以用 flume + kafka
六、Hadoop
| Hadoop | 计算 MR map reduce |
| 存储 HDFS | |
| 调度 yarn |
Hadoop 1.0 计算MR 存储HDFS
Hadoop 2.0 计算MR 存储HDFS yarn
Hadoop 3.0 改MR基于内存计算,以前是基于磁盘计算的
安了hadoop 配置好配置文件 hdfs就启动了 hdfs是一个服务
Hadoop 集群,分为master, slave,每台主机上的配置文件都一致,上满了hadoop集群主机列表, 通常会做3份数据备份,在三台slave上
数据来了,由master去判断哪台salve 此时空闲度最高,最适合,就把数据存到那台slave上,再通知其他两台salve去那台主机上拿数据做备份。
Hadoop有备份3份的机制,在dhfs里看起来是一个完整的目录,实际一份文件被存放在三台服务器里
hadoop把廉价的主机作为集群,可实现强大的性能,节省硬件成本,多台稍微低配的主机组成的集群性能也远高于一台性能特别好的主机。
8×80G= 640 G, 8台主机组合起来性能大于用一台640G的主机,且更便宜。
内存→CPU, 快 spark计算
硬盘→内存→CPU, 慢 MR计算
硬盘→CPU, 虚拟内存 (当一个内存4G的电脑要运行一个8G的软件时,就要把磁盘的一部分当作虚拟内存 )
Hbase的运行需要zookeeper来做协调服务。
七、常用数据处理模型
flume agent → kafka → flink → HBase / Hive / ES / redis→ spark→ mysql → 前端
采集→ 消息中间件 → 流处理,流式计算 → 1T → groupby 啊等计算操作 →1M → 前端
问:数据采集,来自哪儿,采集什么?
数据计算,经过了哪些计算,怎样的计算处理?
数据存储,存储在哪儿?
数据落地,落地在哪?落地到 mysql 吗?