1.Scrapy框架简介
Scrapy是一个为爬取网站数据、提取结构性数据而设计的应用程序框架,它可以应用在广泛领域:Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
前面数据采集流程: url地址->发起请求(requests urllib)-->response(json html/css 代码)--->解析(lxml xpath 正则表 达式 bs4)--存储数据(csv文件 数据中)
scrapy:上面的整个的流程全部都交给框架去做 流水线 自动化 url ------------------目标数据
2.Scrapy框架架构
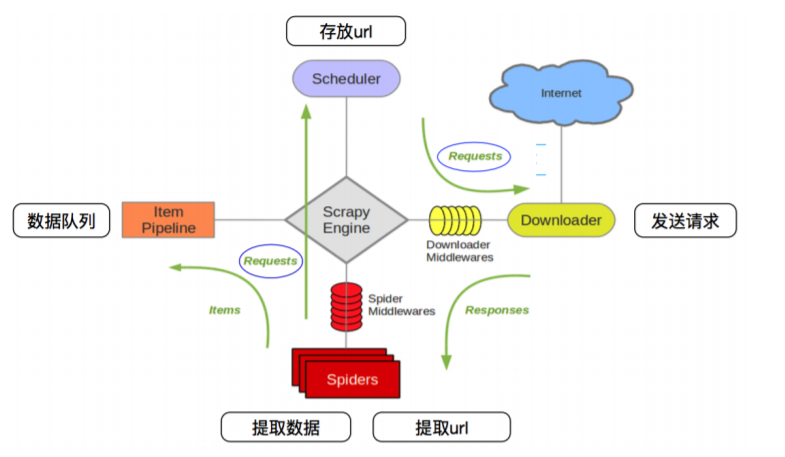

scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、 数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列, 入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取 到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并 将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过 滤、存储等)的地方。
Downloader Midlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider 中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。

3.Scrapy框架安装
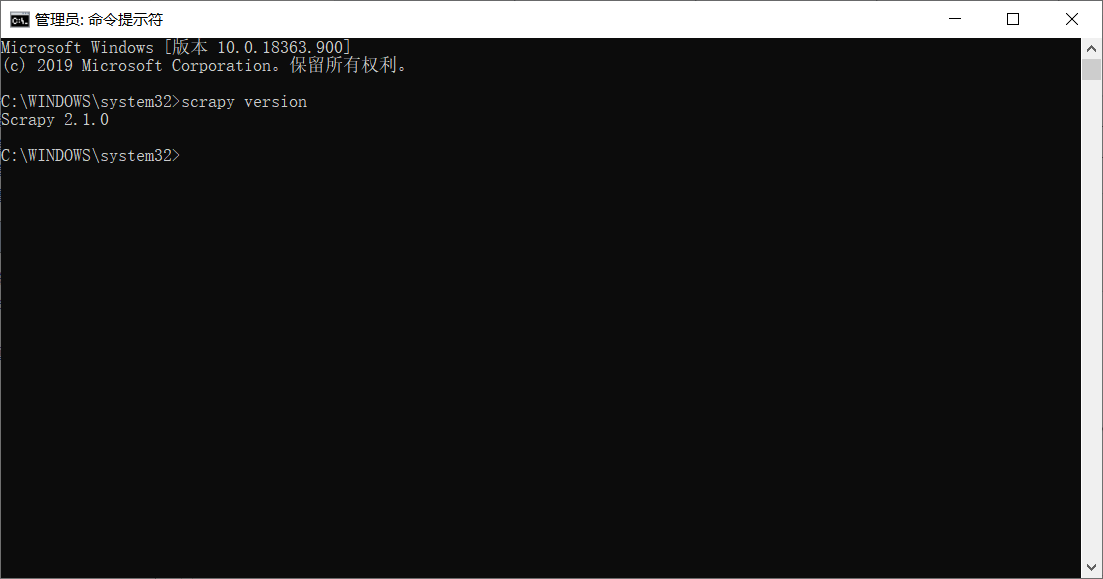
3.1 cmd以管理员方式运行。
> pip install scrapy 安装
> scrapy version 验证
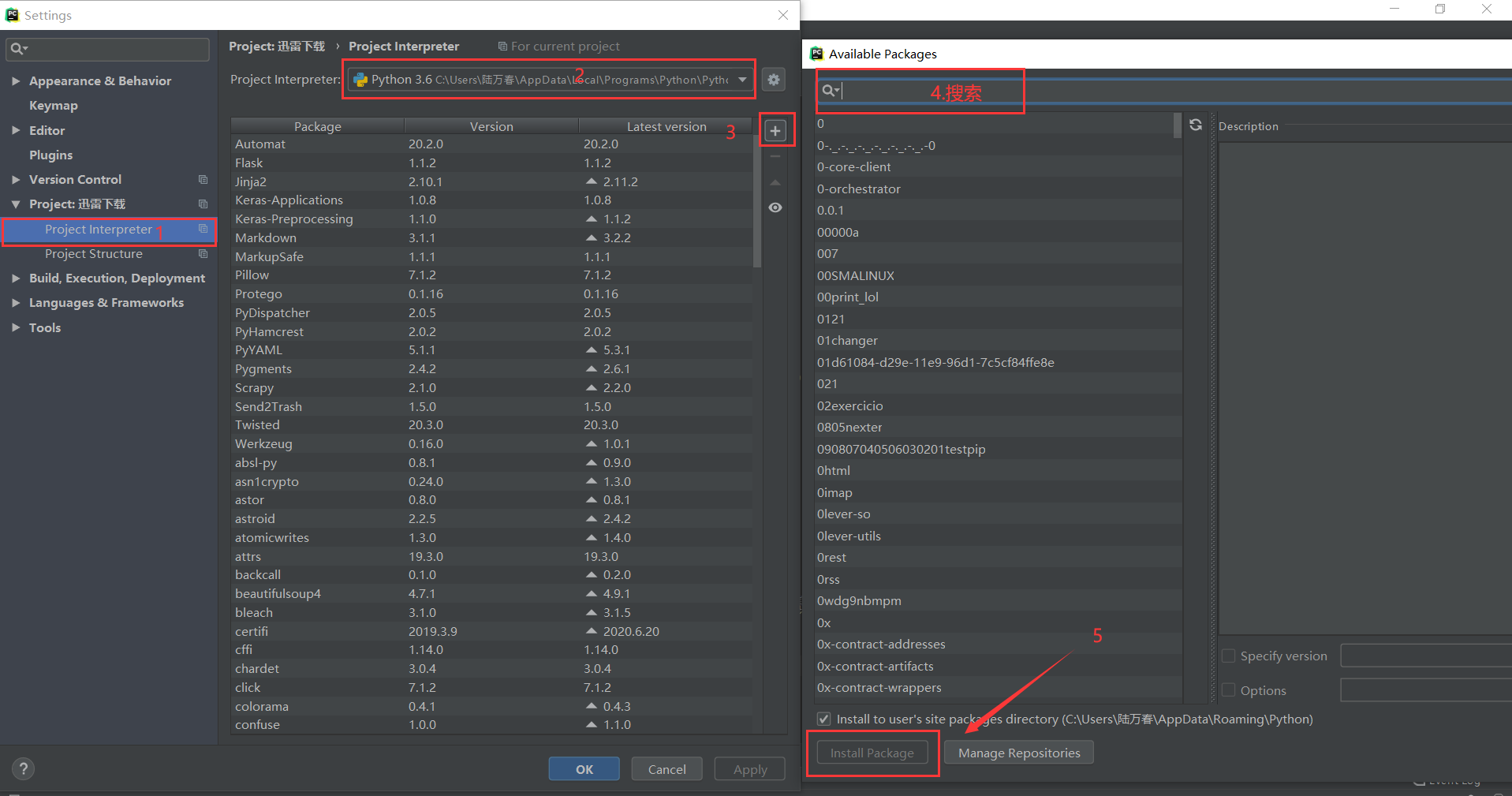
3.2 加载Scrapy(PyCharm)
4.Scrapy简单实例
目标:打开百度首页,把 '百度一下,你就知道' 抓取下来,从终端输出。
4.1创建项目Baidu 和 爬虫文件baidu
1. scrapy startproject Baidu # 创建爬虫项目: scrapy startproject 项目名 2. cd Baidu # cd 项目文件 3. scrapy genspider baidu www.baidu.com # 创建爬虫文件:scrapy genspider 文件名 域名


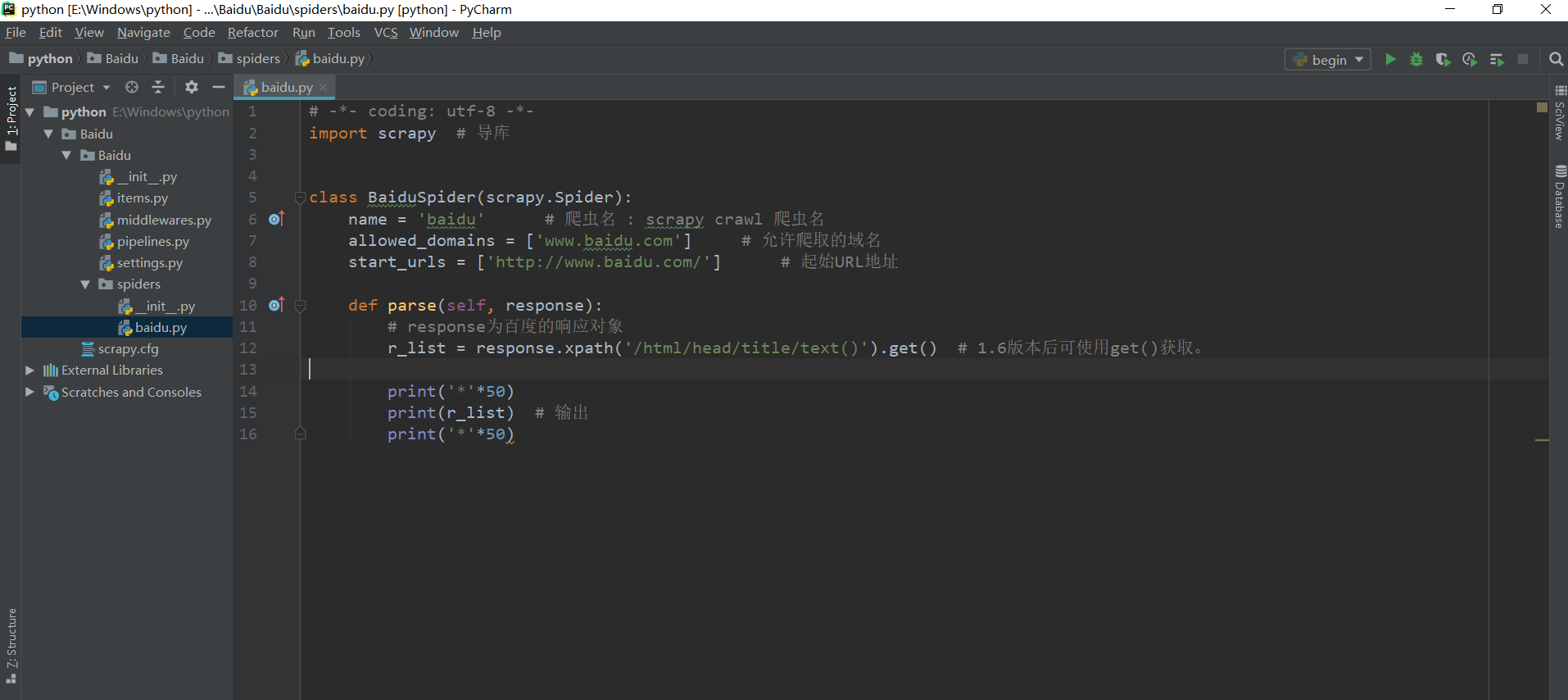
4.2编写爬虫文件baidu.py,xpath提取数据
# -*- coding: utf-8 -*- import scrapy # 导库 class BaiduSpider(scrapy.Spider): name = 'baidu' # 爬虫名 : scrapy crawl 爬虫名 allowed_domains = ['www.baidu.com'] # 允许爬取的域名 start_urls = ['http://www.baidu.com/'] # 起始URL地址 def parse(self, response): # response为百度的响应对象 r_list = response.xpath('/html/head/title/text()').get() # 1.6版本后可使用get()获取。 print('*'*50) print(r_list) # 输出 print('*'*50)
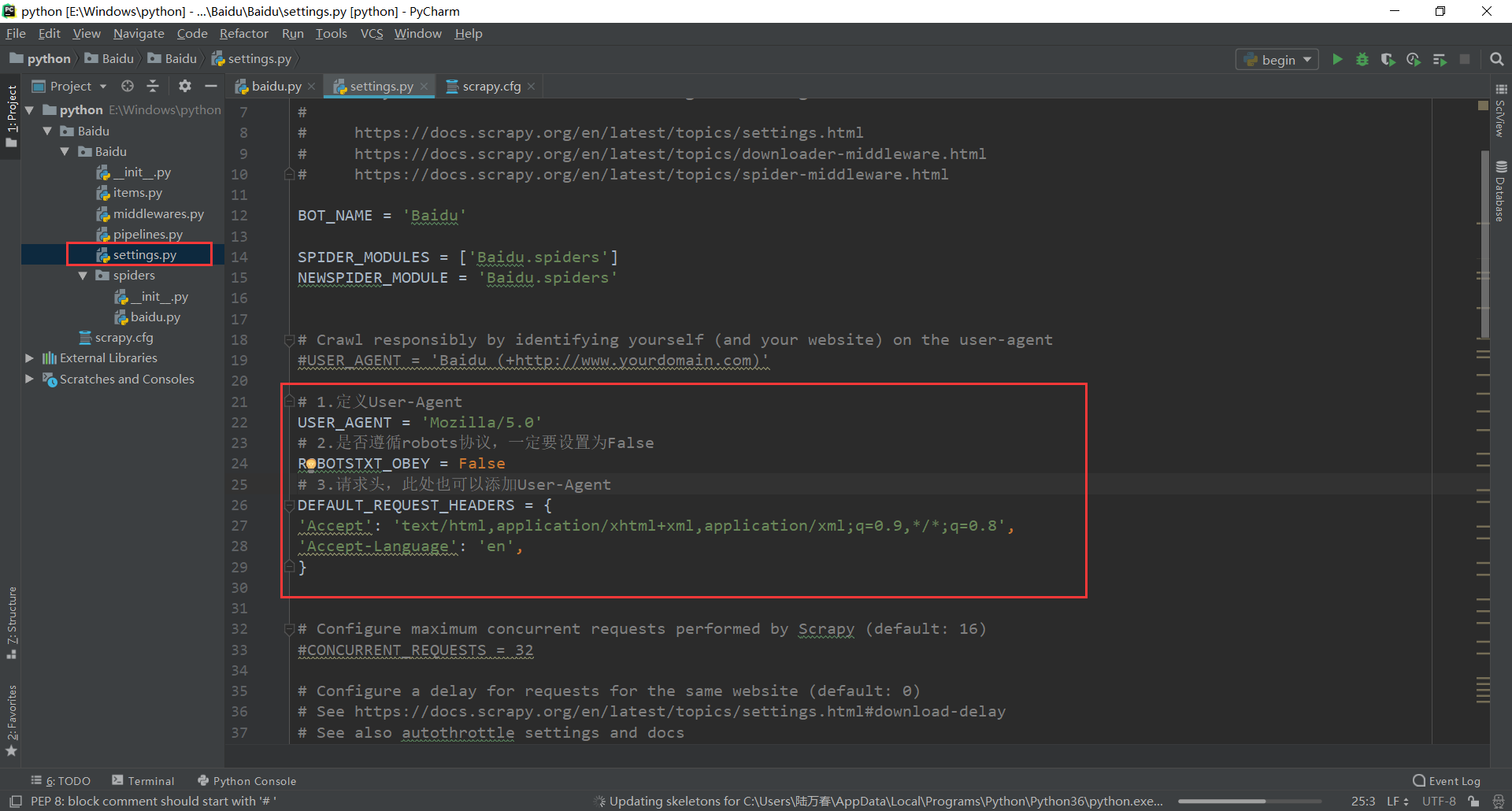
4.3全局配置settings.py
# 1.定义User-Agent USER_AGENT = 'Mozilla/5.0' # 2.是否遵循robots协议,一定要设置为False ROBOTSTXT_OBEY = False # 3.请求头,此处也可以添加User-Agent DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', }
4.4创建begin.py(和scrapy.cfg同目录)
from scrapy import cmdline cmdline.execute('scrapy crawl baidu'.split())

4.5启动爬虫
运行 begin.py 文件
