本文翻译自
翻译:coneypo,working in Intel for IoT,有问题或者建议欢迎留言交流
在这篇文章中,我们会介绍如何利用 Intel 的 OpenVINO 软件包来,发挥 OpenCV 中 Deep Neural Network (DNN) / 深度神经网络 模块的的最大性能;
我们也对 CPU 上 OpenCV 和其他深度学习库的性能进行了比较;
OpenCV 中基于 DNN 实现的模型,在很多深度学习任务中,如分类,目标检测,目标追踪和姿态估计,都表现出色;
我们会在这篇文章中探究,是否可能通过 Intel OpenVINO + OpenCV 这样的组合来进行加速;
0. 目录
1. 训练与推理1. 训练和推理
在开始介绍之前,我们要强调这篇文章专注于 Speeding up inference / 加快推理 而不是训练;让我们来看看两者区别:
1. Training / 训练
把深度神经网路视为一个有很多 knobs (parameters) / 旋钮 的黑盒,当旋钮的设置是正确的时候,神经网络就会比较高可能性的给出正确答案;
训练就是来给网络投喂百万级别的训练数据点,以至于神经网络可以按部就班的调整这些旋钮,使得接近正确值;
这种百万级别的数据处理经常是通过 GPU 来进行运算的;
当前 OpenCV 没有提供训练一个 DNN 的方法,然而你可以利用比如 Tensorflow, MxNet, Caffe 等等框架来进行 DNN 模型的训练,然后在你的代码里导入;
2. Inference / 推理
一旦网络训练完成,就可以输入新的数据来获取输出;使用一个训练好的模型,进行输入输出的过程,就叫做 inference / 推理;
一个推理引擎会将输入的数据通过神经网络产生输出结果,这里有很多优化方式来加速推理过程;
比如一个高效的推理引擎可以进行神经网络的 pruning / 修剪,将多个 Layers 融合到一步计算过程;
如果硬件支持 16-bit 浮点数运算 (2倍于 32-bit 浮点数运算),一个推理引擎会提高两倍推理速度,而且不会丢失精度,这种方式称之为 quantization / 量化;
2. OpenVINO Toolkit 介绍
OpenVINO 代表 Open Visual Inferencing and Neural Network Optimization / 开放视觉推理和神经网络优化;
正如 OpenVINO 名称所描述,OpenVINO 被设计用来给网络加速,在视觉推理任务中,比如图像分类和目标检测;
几乎所有用来解决视觉任务的 DNN 是 Convolutional Neural Networks (CNN) / 卷积神经网络;
OpenVINO 对于特定的硬件有特定的硬件加速方式来加速计算过程;
2.1 为什么使用 OpenVINO?
如果你 AI 新入门,或者对于 AI 不是很了解,你会发现这块会很有意思;
当我们想起 AI,我们经常会想起一些公司,比如 Google, Facebook, Amazon, IBM, Baidu 等等;
确实他们推动了算法的发展,但是 AI 不仅在 Training / 训练 上对于算力要求高,在 Inferencing / 推理 的时候对于资源的要求也高;
因此,我们在 AI 兴起的时候,也应该去关注一些硬件公司;
Convolutional Neural Networks (CNN) / 卷积神经网络 经常在 GPU 上进行训练;
NVIDIA 能够提供几乎最好的的硬件 GPU,与此同时软件上面使用 CUDA 和 cuDNN 进行深度学习;
NVIDIA 几乎垄断了深度学习的市场,当训练模型的时候;
然而 GPU 过于昂贵,往往在推理的时候也是不需要的;事实上,大多数的推理是在 CPU 上进行的;
比如 Dropbox 使用 CPU farm 来进行文档的 OCR;
在低成本的设备上进行深度学习,GPU 往往是开销最大;比如你几乎不可能花费几百刀去买一个 GPU 去给一个监控摄像头;
这些小设备,比如监控摄像头或者树莓派,经常被称为 Edge devices / 边缘设备 或者 IoT devices / 物联网设备;
在推理领域,Intel 占有很大份额;除了制造 CPU,Intel 也生产继承了 GPU 的 Vision Processing Units (VPU) 和 FPGA,这些都用来做推理;
Intel 明白尽管选择很多会很好,但是这也是 AI 开发者的噩梦,因为要在不同平台上进行开发就要学习和适应不同平台的开发环境;
幸运的是,Intel 通过 OpenVINO 解决了这种问题,给 AI 开发者提供了一种 Unified Framework / 统一的框架;
OpenVINO 使得可以边缘端进行 CNN-based 深度学习推理,支持跨平台的异构执行,通过一些 OpenCV 和 OpenVX 中一些函数库和预优化的核来加速产品落地时间;
2.2 计算机视觉 Pipeline 和 OpenVINO
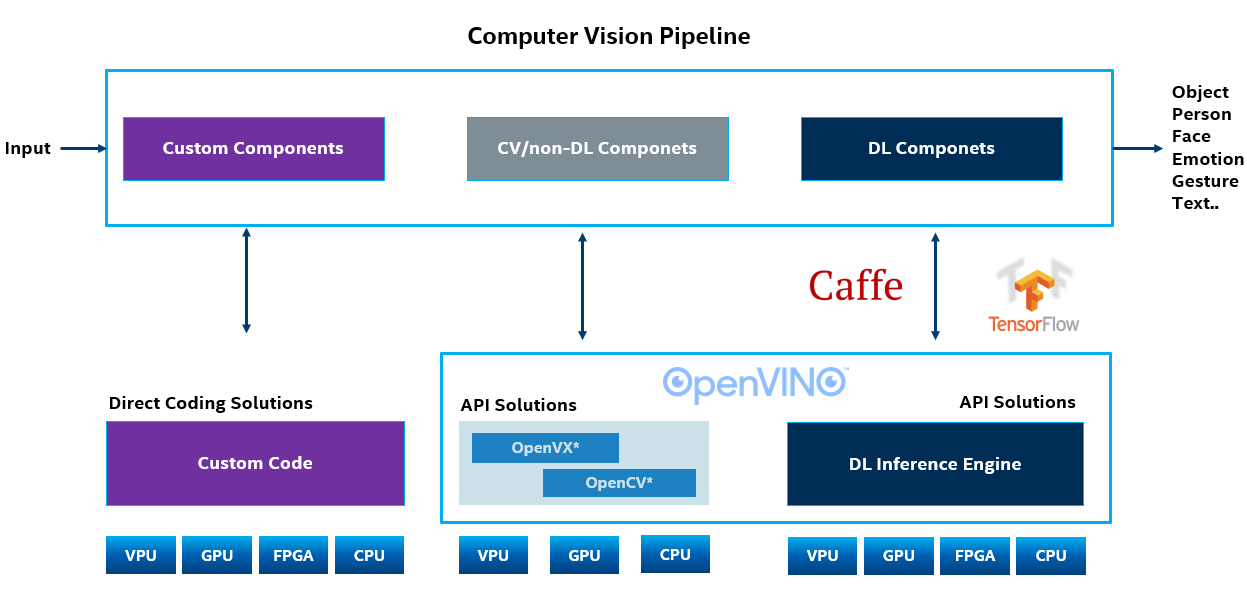
上面框图中,除了有最左边 Custom Code / 定制代码 实现的任务;
除此之外,你有右边两种模块:
1. CV/non-DL, 非基于深度学习的计算机视觉任务
2. DL, 基于深度学习的计算机视觉任务
首先,它会优化 OpenCV 中实现的,许多基于传统计算机视觉算法的很多 calls,然后它对于深度学习推理也有特定的优化;
我们如果将 OpenCV 和 OpenVINO 一起使用会从中受益;
3. 使用 OpenVINO 进行深度学习
这一节中,我们会介绍如何在深度学习应用中使用 OpenVINO。
3.1 训练一个深度学习模型
正如我们之前所提到过,OpenCV 或者 OpenVINO 不会给你提供训练神经网络的工具(OpenVINO 专注于 Inference 而不是 Training);
你可以通过下列任一支持的类型模型来训练神经网络,或者从 zoo 模型下载:
1. Caffe Model Zoo
2. Tensorflow Model Zoo
3. MxNet Model zoo
4. Open Neural Network Exchange (ONNX) Model zoo
3.2 优化模型和创建一个 Intermediate Representation (IR) / 中间表示
之前步骤获得的模型往往没有进行性能的优化,因此,我们利用 OpenVINO 提供的 Model Optimizer / 模型优化器, 来创建一个称之为 Intermediate Representiation (IR) / 中间表示文件 的优化模型;
IR 完全与硬件无关,只取决于神经网络的架构;
下图中展示了用 OpenVINO 部署方式和大多数深度学习框架部署方式的区别:
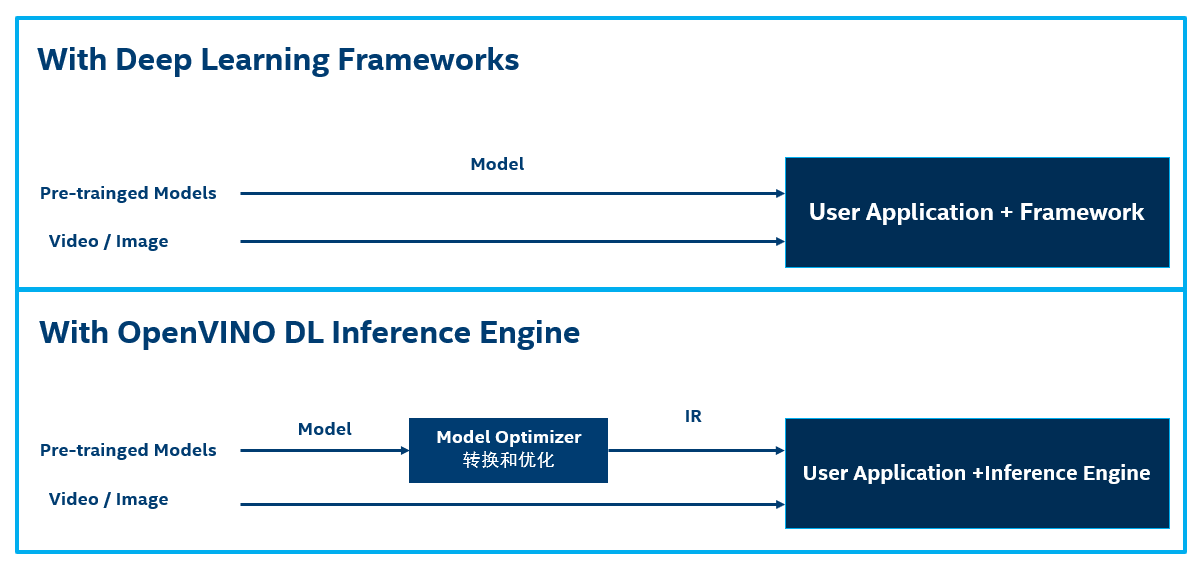
可以看到模型优化器通过以下机制来优化模型:
1. 对模型进行修剪:移除部分在训练时候需要的,而推理时候不需要的网络;DropOut 就是这种网络层的一个例子;
2. 融合操作:有些时候多步操作可以融合成一步,模型优化器检测到这种就会进行必要的融合;
优化过程结束后会生成一个 IR model / 中间表示模型,模型可以被分成两部分:
1. model.xml: XML 文件包含网络架构;
2. model.bin: bin 文件包含 Weights / 权重 和 Biases / 误差
3.3 OpenVINO 推理引擎: 硬件特殊优化
IR 模型与硬件无关,但是 OpenVINO 通过 Inference Engine plugin / 推理引擎插件 在特定的硬件上进行优化;
这个 Plugin 在所有 Intel 的硬件上 (GPUs, CPUs, VPUs, FPGSs) 都可以获得:

3.4 OpenVINO 和 OpenCV
尽管 OpenCV 的 DNN 已经被高度优化,通过推理引擎我们可以进一步提高性能;
下图中展示了使用 OpenCV DNN 的两种方式;如果在您的平台上可以使用,我们高度推荐 OpenVINO + OpenCV 的组合;

4. Linux 中安装 OpenVINO Toolkit
这一节我们会介绍如何在 Linux 中安装和测试 OpenVINO;
Windows 中的 Openvino 安装可以参考 Intel’s website.
4.1 OpenVINO Toolkit 安装
1. 首先去 OpenVINO Toolkit Download page 注册并下载适合你系统的正确版本,这里我们介绍 Linux 系统中的安装:

2. 你会下载下来如 “l_openvino_toolkit_p_2020.1.023.tgz” 这样一个压缩文件,解压然后安装;
1 cd ~/Downloads/ 2 tar -zxvf l_openvino_toolkit_p_2020.1.023.tgz 3 4 cd l_openvino_toolkit_p_2020.1.023/ 5 sudo ./install_openvino_dependencies.sh 6 sudo ./install_GUI.sh

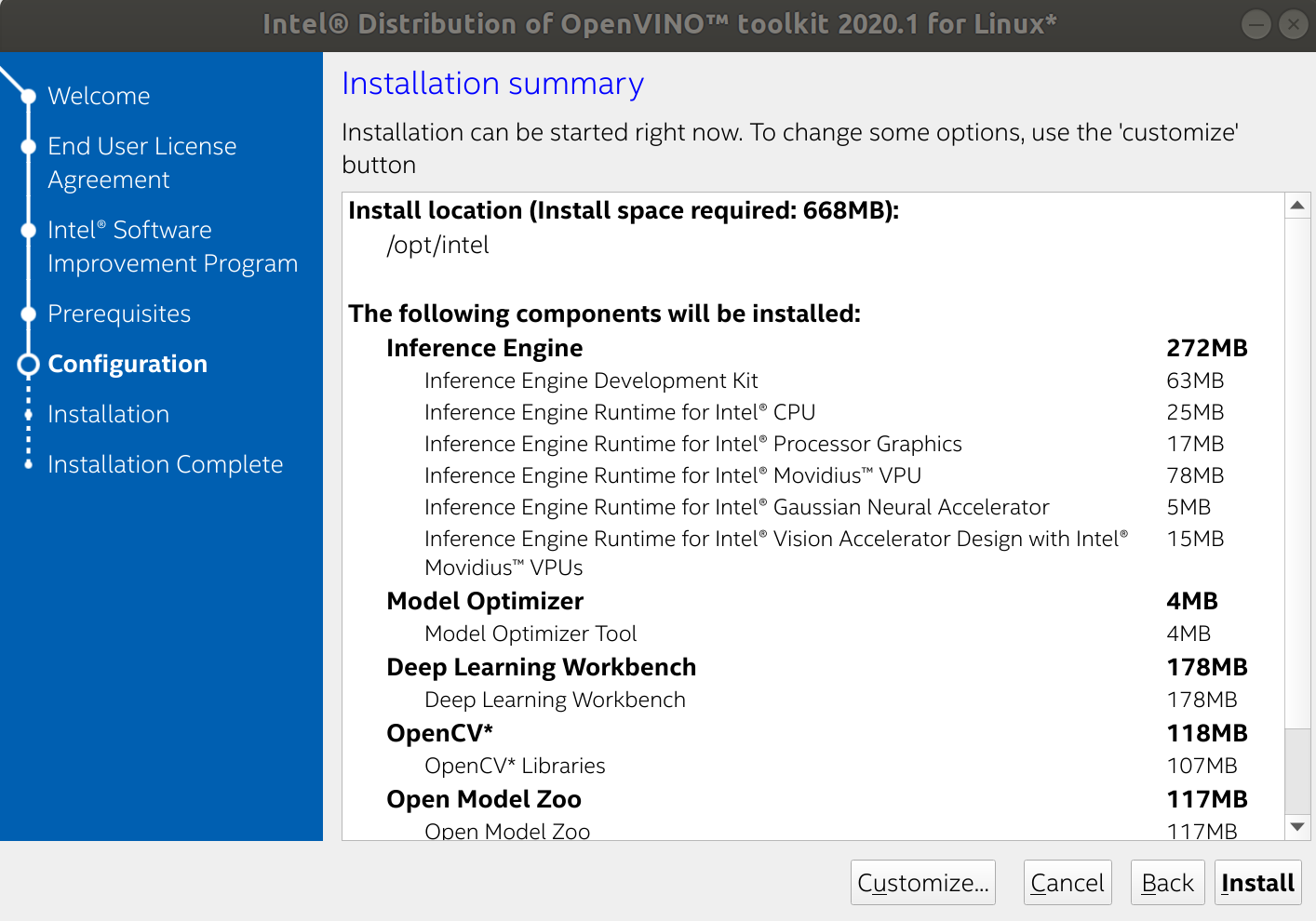

注意: 如果你 sudo ./install_GUI.sh 的话,路径会是 "/opt/intel/openvino_2020.1.023/" 这种;
如果不是 sudo 身份安装,路径会是 "/home/user/intel/openvino_2020.1.023/";
3. 修改环境变量
vim /home/user/.bashrc
在最后一行加入
source /opt/intel/openvino_2020.1.023/bin/setupvars.sh
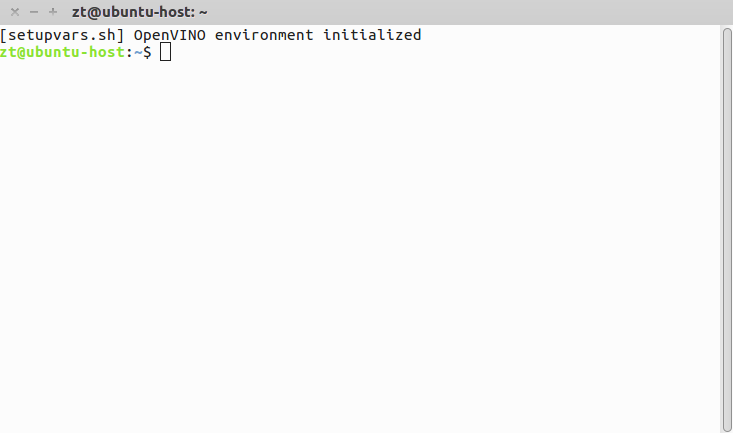
4. 打开一个新的 Terminal,可以看到 "OpenVINO enviroment initialized"
5. 配置模型优化器,让我们去模型优化器的路径,然后安装所需文件:
cd /opt/intel/openvino_2020.1.023/deployment_tools/model_optimizer/install_prerequisites/ sudo ./install_prerequisites.sh
4.2 测试 OpenVINO 安装
我们可以用 Image Classification demo 来测试安装:
cd /opt/intel/openvino_2020.1.023/deployment_tools/demo/ sudo ./demo_squeezenet_download_convert_run.sh
可以看到 "Demo completed successfully":

还可以去跑 Inference Pipepline demo:
sudo ./demo_security_barrier_camera.sh
可以看到输出的检测结果:

5. 使用 OpenCV 和 OpenVINO IE 进行图像分类
现在让我们来看看如何利用 OpenVINO IE + OpenCV 进行图像分类。
1. 首先需要加载需要的模块:
C++
1 #include <fstream> 2 #include <sstream> 3 #include <opencv2/dnn.hpp> 4 #include <opencv2/imgproc.hpp> 5 #include <opencv2/highgui.hpp> 6 #include <iostream> 7 8 using namespace std; 9 using namespace cv; 10 using namespace cv::dnn;
Python
1 import numpy as np 2 import time 3 import cv2
2. 下一步指定 Caffe 的根路径和模型路径:
C++
1 string caffe_root = "/home/zt/caffe/"; 2 Mat image = imread("/home/zt/caffe/examples/images/cat.jpg"); 3 string labels_file = "/home/zt/caffe/data/ilsvrc12/synset_words.txt"; 4 string prototxt = "/home/zt/caffe/models/bvlc_reference_caffenet/deploy.prototxt"; 5 string model = "/home/zt/caffe/models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel";
Python
1 caffe_root = '/home/zt/caffe/' 2 image = cv2.imread('/home/zt/caffe/examples/images/cat.jpg') 3 labels_file = caffe_root + 'data/ilsvrc12/synset_words.txt' 4 prototxt = caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt' 5 model = caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
3. 接下来就是常用的图像分类代码,加了一点轻微改动;
我们会声明优先选取 cv2.dnn.DNN_BACKEEND_INFERENCE_ENGINE;
C++
1 // load the labels file 2 std::ifstream ifs(labels_file.c_str()); 3 if (!ifs.is_open()) 4 CV_Error(Error::StsError, "File " + labels_file + " not found"); 5 string line; 6 while (std::getline(ifs, line)) 7 { 8 classes.push_back(line); 9 } 10 } 11 blobFromImage(image, blob, 1, Size(224, 224), Scalar(104,117,123)); 12 cout << "[INFO] loading model..." << endl; 13 Net net = readNetFromCaffe(prototxt, model); 14 net.setPreferableBackend(DNN_BACKEND_INFERENCE_ENGINE); 15 net.setPreferableTarget(DNN_TARGET_CPU); 16 17 // set the blob as input to the network and perform a forward-pass to 18 // obtain our output classification 19 net.setInput(blob) 20 preds = net.forward() 21 22 double freq = getTickFrequency() / 1000; 23 std::vector<double> layersTimes; 24 double t = net.getPerfProfile(layersTimes) / freq; 25 cout << "[INFO] classification took " << t << " ms" << endl;
Python
1 // load the labels file 2 rows = open(labels_file).read().strip().split(" ") 3 classes = [r[r.find(" ") + 1:].split(",")[0] for r in rows] 4 5 blob = cv2.dnn.blobFromImage(image,1,(224,224),(104,117,123)) 6 print("[INFO] loading model...") 7 net = cv2.dnn.readNetFromCaffe(prototxt,model) 8 net.setPreferableBackend(cv2.dnn.DNN_BACKEND_INFERENCE_ENGINE) 9 net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU) 10 # set the blob as input to the network and perform a forward-pass to 11 # obtain our output classification 12 net.setInput(blob) 13 start = time.time() 14 preds = net.forward() 15 end = time.time() 16 print("[INFO] classification took " + str((end-start)*1000) + " ms")
就是这样,仅仅需要用 OpenVINO IE 来替代原生的 OpenCV (cv2.dnn.DNN_BACKEDN_OPENCV);
6. OpenCV 和 OpenCV + IE 的比较
这些比较任务在一台使用 OpenCV-3.4.3,只有 CPU 的 Ubuntu 16.04 AWS 机器上测试;
取100次的平均时间;
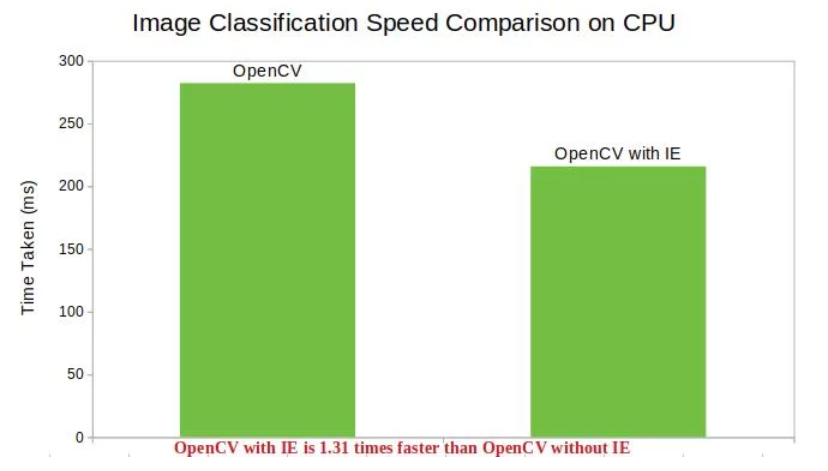
Image Classification / 图像分类

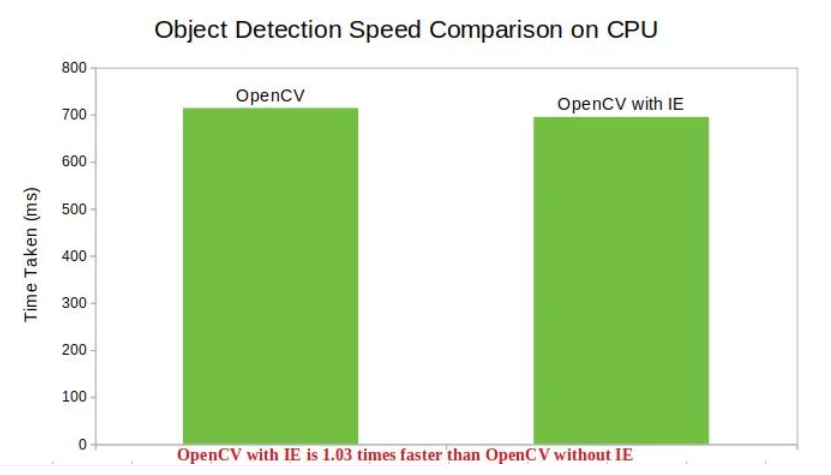
Object Detection / 目标检测
Pose Estimation / 姿态估计

从这些数据中可以很清楚的看到,使用 OpenCV + OpenVINO 可以提高计算机视觉库的性能;
# 英文版权 @
# 翻译中文版权 @ coneypo
# 转载请注明出处