引入
对于分类任务我们可以使用分类错误率来衡量模型的性能,具体来说是模型在训练集上的误差成为训练误差,模型在新样本(测试集)上的误差成为泛化误差,评估机器学习应该使用泛化误差进行评价。
概念
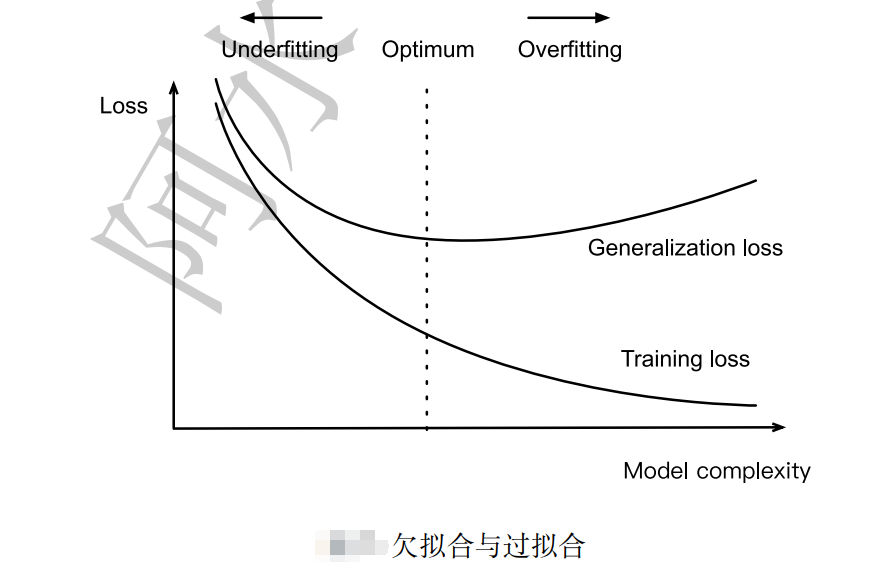
在模型的训练过程中,模型只能利用训练数据来进行训练,模型并不能接触到测试集上的样本。因此模型如果将训练集学的过好,模型就会记住训练样本的细节,导致模型在测试集的泛化效果较差,这种现象称为过拟合(Overfitting)。与过拟合相对应的是欠拟合(Underfitting),即模型在训练集上的拟合效果较差。
(1)过拟合: 模型在训练集误差较低,但在测试集上误差较高;
(2)欠拟合: 模型在训练集误差较高,还没有完全拟合训练集;
解决办法
导致模型过拟合的情况有很多种原因,其中最为常见的情况是模型复杂度(Model Complexity)太高,导致模型学到了训练数据集的方方面面,学到了一些细枝末节的规律。欠拟合由模型复杂度较高或模型未训练完全导致的,解决方案很简单: 增加模型复杂度或者增加模型的训练轮数。