关于本书
《七周七并发模型》是我在书店寻找Actor相关资料时偶遇的一本200多页的小册子。目录看似简单,实际的内容却涵盖了多种编程语言、并发模型与框架,对我实在是一大考验。断断续续地看了一个多月才勉强读完一遍,很粗浅地对书中提到的模型有了大致的了解。由于其中每个模型都需要大量的基础知识支撑,很容易让自己陷入碎片化学习的泥沼,因此暂时我就把它当个入门的索引了。
七个并发模型
- 线程与锁:这是最传统的、围绕共享数据进行并发编程的基础。
- 函数式编程:FP主要依赖于无可变状态、无副作用的纯函数这两大特性,摆脱传统的命令式编程因共享数据导致的并发冲突。
- Clojure之道:结合FP与CP的优势进行的混搭,借鉴了FP的持久数据结构以避免竞争。这一章需要的Clojure知识太多,我只看了个大概。
- Actor:借助Actor这种自带事件邮箱的事件驱动的并发最小实体,实现无数据共享的并发与协作。
- 通信顺序进程:借助共用的消息队列和相对独立的Go并发状态机,实现与Actor互补的另一种并发模型。比如.NET里的async与await内部实现就借鉴了这种机制。
- 数据级并行:借助GPU在图像处理等方面进行矩阵或向量相关的等大量数字计算。
- Lambda架构:时下最潮的基于Map-Reduce和批处理的分布式协作模型。
主要实例
- 哲学家用餐:有一张餐桌,若干个哲学家。哲学家或在进餐、或在思考。进餐时哲学家需要拿起左右两边的筷子,进餐结束后则放下筷子开始思考。
- 词频统计:根据一个较大尺寸的文本档(可能是XML格式),统计其中的每个单词及其出现频率。实质是个生产者-消费者问题。
并发与并行
- 并发:同一时间应对(Dealing With)多件事情的能力。另一种解释是同时有多个操作出现。
- 并行:同一时间执行(Doing)多件事件的能力。另一种解释是以同时多个操作完成单个目标。
阿姆达尔定律(Amdahl's law)
公式:并行加速率=(Ws+Wp)/(Ws+Wp/p)
受计算中并行分量Wp、串行分量Ws、处理器数量p影响,加速化曲线呈S状梯形上升。
路线图
如前所述,由于涉及的语言和框架的跨度较大,每个章节又相对独立、知识点相对零散,所以我无法从中窥探出一幅真正意义上的路线图,只能记下其中的聊聊数笔。
首先是关于餐桌加锁还是筷子加锁的抉择
以哲学家进餐为例,谁同时拿上左右两支筷子才能吃上饭,其他人则只能等待他放下筷子才能机会拿齐一双筷子进餐。这就是线程与锁的故事——简单而粗暴。这一把把筷子就好比是一把把的锁,这锅饭就好比大家竞争的共享数据。没拿到筷子的人,即被阻塞在不停抢筷子的循环里——天知道我什么时候能抢到?
由于存在多把锁的同时竞争,很容易造成死锁。于是引入了一个简单而有效的规则:『始终按照一个全局的、固定的顺序获取多把锁』。比如说约定总是先取左手边的筷子,再取右手边的。于是得到如下的一个示意图。图中的每个元素、每个环节都需要进行同步化。
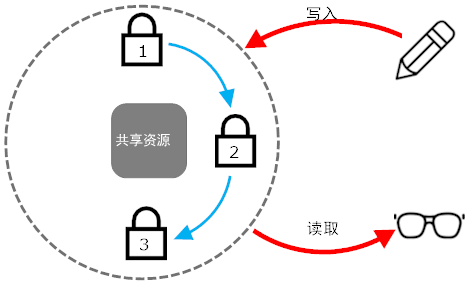
尽管问题得到初步解决,但内置锁在线程被阻塞后无法中断,造成线程假死,而且锁越多意味着死锁的风险也越大。于是引入可中断的锁、超时锁、条件变量等一些弥补机制。其中的条件变量condition机制,在Java 5.0和.NET 4.0之后的并发框架中得到了广泛应用。在引入Condition后,得到哲学家进餐问题的第二个版本:不再是每支筷子对应一把锁,而改为视整张餐桌为一把锁,再把左右哲学家进餐结束视作竞争条件。这样,当左右两边的哲学家进餐结束时,就意味着自己可以进餐了。
private void eat() {
// 先获取锁
table.lock();
try {
// 如果条件满足就解锁并await一直等待
while (left.eating || right.eating)
condition.await();
// 接收到其他线程通过signal()或signalAll()发出的信号
// 于是条件得以满足,加锁后访问共享资源
eating = true;
}
finally { table.unlock(); }
}
private void think() {
table.lock();
try {
eating = false;
left.condition.signal();
right.condition.signal();
}
finally { table.unlock(); }
}
然后是词频统计的第一个版本
拆解问题,可以得出统计需要三个步骤:用下载的XML文本构造出若干张Page,然后逐页分析每张Page里出现的单词Word,最后合计每个Word出现的次数。
在通常的串行化方案(逐行解析并统计)之后,依次给出了如下三个并发解决方案:
- 1个生产者-1个消费者:共享一个queue和map。注意使用blocking queue,在队列空或者满时发生阻塞,以避免生产与消费速度失配造成的影响。

- 1个生产者-N个消费者:共享一个queue和map,但使用的并发专用的ConcurrentHashMap以避免多个线程过度竞争map,提高消费速度。
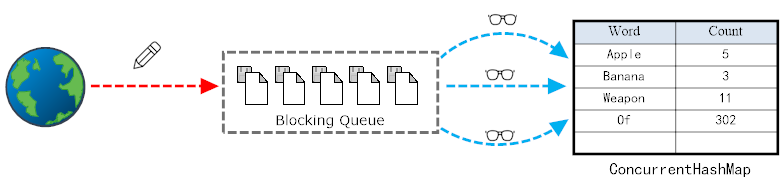
- 1个生产者-N个消费者:共享一个queue,每个消费者自己维护一个map,在消费者完成统计时再将统计结果汇总进共用的ConcurrentHashMap。这个就是Map-Reduce的基本原理了。

接着一脚跨入函数式编程
我对函数式编程FP的认识,就是y=f(x),对函数f给定x就一定得到y,不会因为f或者x持有其他的状态而产生不同于y的其他结果。而在FP的世界,除了常量与递归成为常态外,最常见的就是map、reduce、fold等一些映射与聚合函数了。我只想说,FP的实现代码真是简洁得可怕!
- 这是串行版本。
(defn get-words [text] (re-seq #"w+" text))
(defn count-words-sequential [pages]
(frequencies (mapcat get-words pages)))
- 接着是第一个并行版本。它每次会取一个Page交给get-words,然后利用merge-with产生的局部函数,交给pmap逐页进行结果合并。
(defn count-words-parallel [pages]
(reduce (partial merge-with +)
(pmap #(frequencies (get-words %)) pages)))
- 然后是对Page进行分组,按100页作为一个批次进行批处理的版本。这个出发点类似锁版本的第3个方案。每个批次先小计,最后再合计。
(defn count-words [pages]
(reduce (partial merge-with +)
(pmap count-words-sequential (partition-all 100 pages))))
- 最后用二分法的折叠fold进行的实现。这种情况下,整个汇总过程类似一棵Tree,上层的结点reduce产生统计结果后,才合并到下一层的结点,最后得到的根结点即为统计结果。用下面这个parallel-frequencies替换掉frequencies。
(defn parallel-frequencies [coll]
(r/fold
(partial merge-with +)
(fn [counts x] (assoc counts x (inc (get counts x 0))))
coll))
紧接着是Clojure的标识与状态分离
这部分多数涉及Clojure的框架,所以我只关注了与FP密切相关的『持久数据结构』。
理解持久数据结构,有点类似于理解『引用』与引用指向的『内存块』。而在FP里,纯粹的函数是不会修改既有结构的,因为它总是产生一个新的结果。
(def list_1 (1, 2, 3))
(def list_2 (cons 4 list_1))
(def list_3 (cons 5 (rest list_1)))
这段代码将产生下面这样的一个链表结构:

由此展示了CP与FP的一大重要区别:在CP中,一个变量既是标识Identity也是状态State,你在此时拿到某个列表是是(1,2,3),下一刻可能被别人改为(1,3,4,5),而在FP中则会始终是(1,2,3),这便是持久数据结构的本质。即一个标识,会对应多个版本、随时间变化的值。
到了我最感兴趣的Actor部分
“使用Actor就像租车——如果我们需要,可以快速便捷地租到一辆;如果车辆发生故障,也不需要自己修理,直接打电话给租车公司更换一辆即可。”
每个Actor,都是一个封闭的、有状态的、自带邮箱、通过消息与外界进行协作的并发实体。在Actors之间的消息发送、接收是并发的,但是在Actor内部,消息被邮箱存储后都是串行处理的。即Actor在同一时刻只会对一条 异步消息做出回应,从而回避锁策略。
使用Actor编程有个很不同寻常的编程思想——“任其崩溃”!这是因为每个Actor都被其监督者管理,这些不同层次的Actor及其监督者搭建成一棵完整的Actor模型树。这棵树的叶结点是各种Actor,非叶的结点则是监督者。当某个Actor出现错误而崩溃时,由其监督者采取重启、忽略错误、记录原因等措施。
消化掉以上两点,我就开始读《Reactive Messaging Patterns with the Actor Model》作为进阶了。最后,同样援引Smalltalk设计者、面向对象之父Alan Kay的一段话结束本节。好吧,我承认误入歧途了。
很久以前,我在描述“面向对象编程”时使用了“对象”这个概念。很抱歉,这个概念让许多人误入歧途,他们将学习重心放在了“对象”这个次要的方面。真正主要的方面是“消息”……创建一个规模宏大且可以生长的系统,关键在于其模块之间应如何交流,而不在于其内部的属性,以及行为应该如何表现。
再者是与Actor紧密联系的CSP
CSP(Communicating Sequential Process,通信顺序进程),和Actor比较类似。CSP不关心消息是谁发送的,只关心用于消息传递的那个通道Channel,我把这个Channel视作一个线程安全的消息队列,消息两端与消息队列本身是脱耦的。而在这方面,Actor模型中的消息两端是明确已知的,消息队列也是由Actor邮箱自带的。
CSP的执行体主要是各种Go块。这个Go块就当是一个状态机,这与C#中async和await的实现是一致的,具体参考《CLR via C#》第4版第649页『28.3 编译器如何将异步函数转换为状态机』。
GPU很闲,需要帮助吗
这部分主要围绕矩阵、向量等线性代数方面所需的大量数值计算,引入OpenCL驱动GPU进行并行计算。这方面我没什么研究,直接跳过了。
终于到了Lambda这个最终Boss
这章我只知道Map-Reduce是Lambda的主要基石,将问题分解为Map和Reduce两个部分是一切的关键。其中,Map负责把输入映射为若干对key-value,然后由Reduce负责聚合这些key-value,输出最终数据。
除了Map-Reduce,为了解决报表与分析等一些需要及时反馈的信息,又引入了流处理技术。我的理解,就是对原始数据进行一个合理的分片,再利用批处理生成一个与报表需求一致的中间结果批处理视图,最后再借由服务层按需拼凑成最终结果。这个部分,合理的分片和拼凑算法是关键。
如果及时响应的要求还要更高,那么还有个加速层的东西,根据最后一次生成批处理视图的原始数据,直接生成相应的派生信息。这个部分,决定哪些数据过期、如何让其过期是关键。
结语
分布式的世界,分布式的软件。