本文来自公众号“AI大道理”。
作为传统语音识别神器,kaldi拥有自己一套独特的输入输出机制。
先来感受一下吧。
feats="ark,s,cs:apply-cmvn $cmvn_opts --utt2spk=ark:$sdata/JOB/utt2spk scp:$sdata/JOB/cmvn.scp scp:$sdata/JOB/feats.scp ark:- | add-deltas $delta_opts ark:- ark:- |"
咋一看,这是什么鸟语?花香!
1 文件I/O机制
Kaldi采用一种扩展的文件名进行输入输出。
读取文件的文件名称为rxfilename,写入的文件名称为wxfilename。
xfilenames,是一个字符串,表示由Input类进行解析的扩展文件名称,代表读。
wxfilenames,是一个字符串,表示由Ouput类进行解析的扩展文件名称,代表写。
特点:
-
在rxfilename/wxfilename 处采用“-”来表示标准输入输出。
-
rxfilename/wxfilename可以使用管道命令,比如先用gunzip将压缩文件解压,再输入到Kaldi程序中,即可在文件输入路径处填入“gunzip -c foo.gz|”。
-
rxfilename/wxfilename后可以通过“:”来描述偏移量,如“foo:1045” 表示从foo文件偏移1045个字节开始读取。
-
使用–binary=true/false来控制是否使用二进制输出。默认是true。


文件读写机制
文件的读写采用 Input/Output 类。

![]()
2 表格I/O机制
对于一系列数据的集合,Kaldi 采用表格形式来表示。
表格中,以没有空格的字符串为索引。
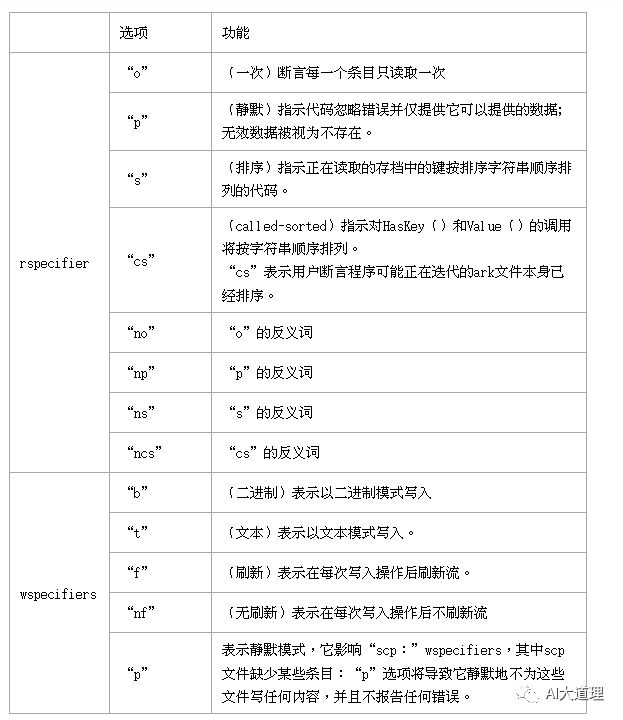
Kaldi 中,称从表格文件中读取的一个字符串为 rspecifier, 写入表格文件的一个字符串为wspecifier。
Table类需要一个传递给构造函数或Open方法的字符串。如果传递给TableWriter类,则此字符串称为wspecifier。
传递给RandomAccessTableReader或SequentialTableReader类,则称为rspecifier。
有两种表格文件格式:archive (.ark)和 script (.scp)。
其中:

![]()
rspecifier和wspecifiers的选项说明
![]()
![]()
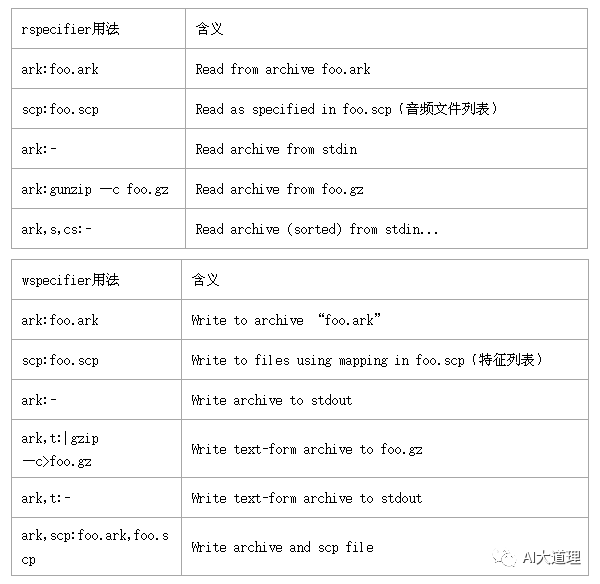
表格(Table)读写
对于表格文件(scp,ark),Kaldi 定义了专门的表格读写器。
表格读写器是关于 Holder 类的模板类。
Holder 是一些辅助类,负责告诉表格读写器,对象的类型是什么,应该如何读写。
表格读写器有四个类:RandomAccessTableReader 、 SequentialTableReader 、
TableWriter 、 RandomAccessTableReaderMapped 。
Sequential 表示序列化访问,即支持使用迭代器遍历;Random 表示随机访问某几个。
读写的时候,需要提供 wspecifiers/rspecifiers 给读写器。
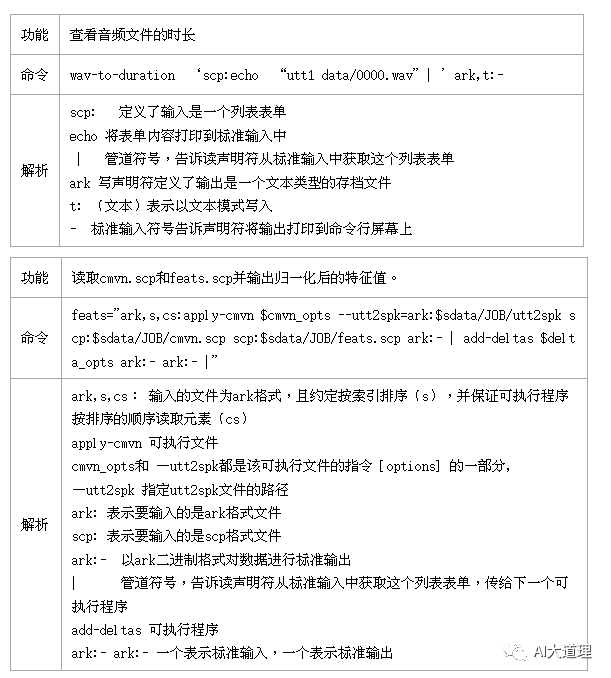
3 命令行I/O机制
命令行 I/O 是指在 shell 上调用编译好的 Kaldi 工具的方法。
命令行I/O机制实例
![]()
4 代码级I/O机制
/kaldi-trunk/src/util文件夹下的kaldi-io.h 是Kaldi的I/O机制相关类的声明。
对象(Object)读写机制
Kaldi中定义的类有一个通用的I/O接口。
标准的接口如下:

![]()
注解:
返回的是void类型,不能接一连串的istream或者ostream。
binary参数是一个标志位,表明要读写的是binary数据还是text数据。
Kaldi进行读操作的代码需要知道用哪种模式(binary mode 和 text mode)。不需要准确地追溯一个文件到底是binary的还是text的。
一个binary的Kaldi文件以字符串"�B"开头,而text文件不需要文件头(header)。
典型的读写过程如下:

![]()
包含Kaldi对象的文件需要声明它们是包含二进制数据还是文本数据。
二进制Kaldi文件将以字符串“ 0B”开头;由于文本文件不能包含“ 0”,因此它们不需要标题。
5 总结
了解了kaldi的输入输出机制后,开始进行数据准备工作。

![]()
下期预告
AIBigKaldi(三)| Kaldi数据准备
往期精选
AI大语音(十四)——区分性训练
AI大语音(十三)——DNN-HMM
AI大语音(十二)——WFST解码器(下)
AI大语音(十一)——WFST解码器(上)
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

![]()

![]()
—————————————————————