一、数据插入
INSERT是用来插入行到数据库表的。
插入可以用几种方式使用:插入完整的行;插入行的一部分;插入多行;插入某些查询的结果。
如果表的定义允许,则可以在INSERT操作中省略某些列。省略的列必须满足以下某个条件。该列定义为允许NULL值(无值或空值);在该表定义中给出默认值(这表示如果不给出值,将使用默认值)。
1、插入行
1 INSERT INTO customers VALUES( 2 NULL, 3 'Pep E. LaPew', 4 '100 Main Street', 5 'Los Angeles', 6 'CA', 7 '90046', 8 'USA', 9 NULL, 10 NULL 11 )

插入一个新用户到customers表中。存储到每个表列中的数据在VALUES子句给出,对每个列必须提供一个值。如果某个列没有值(如上面的cust_contact,cust_email),应该使用NULL值(假如表允许对该列指定空值)。各个列必须以它们在表定义中出现的次序填充。第一列cust_id也为NULL,这是因为每次插入一个新行时,该列由MySQL自动增量。你不想给出一个值,又不能省略此列,所以指定一个NULL值(它被MySQL忽略,MySQL在这里插入下一个可用的cust_id值)。
上面的SQL语句高度依赖于表中列的定义次序,并且还依赖于其次序容易获得的信息。即使可得到这种次序信息,也不能保证下一次表结构变动后各个列保持完全相同的次序。因此编写依赖于特定次序的SQL语句时很不安全的。
编写INSERT语句的更安全的写法如下:
1 INSERT INTO customers(cust_id,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country,cust_contact,cust_email) 2 VALUES( 3 NULL, 4 'Pep E. LaPew', 5 '100 Main Street', 6 'Los Angeles', 7 'CA', 8 '90046', 9 'USA', 10 NULL, 11 NULL 12 )
2、插入多个行
单条INSERT语句有多组值,每组值用一对圆括号括起来,用逗号分隔。
1 INSERT INTO customers(cust_id,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country,cust_contact,cust_email) 2 VALUES 3 ( 4 NULL, 5 'Pep E. LaPew', 6 '100 Main Street', 7 'Los Angeles', 8 'CA', 9 '90046', 10 'USA', 11 NULL, 12 NULL 13 ), 14 ( 15 NULL, 16 'M. Martian', 17 '42 Glaxy Way', 18 'Los Angeles', 19 'NY', 20 '233', 21 'USA', 22 NULL, 23 NULL 24 );
这种写法可以提高数据库处理性能,因为MySQL用单条INSERT语句处理多个插入比使用多条INSERT语句快。
3、插入某些查询的结果
INSERT SELECT可以用来将一条SELECT语句的结果插入表中。INSERT SELECT中SELECT语句课包含WHERE子句以过滤插入的数据。
1 INSERT INTO customers_new(cust_id,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country,cust_contact,cust_email) 2 SELECT cust_id,cust_name,cust_address,cust_city,cust_state,cust_zip,cust_country,cust_contact,cust_email FROM customers;
这个例子使用INSERT SELECT从customers中将所有数据导入customers_new中。为简单起见,这个例子在INSERT 和SELECT语句中使用了相同的别名。但是,不要求列名匹配。事实上,MySQL甚至不关心SELECT返回的列名。它使用的是列的位置,因此SELECT中的第一列(不管其列名)将用来填充表列中指定的第一个列,第二列将用来填充表列中指定的第二个列,如此等等。这对于从使用不同列名的表中导入数据时非常有用的。
二、更新数据
1、在更新多个列时,只需要使用单个SET命令,每个“列=值”对之间用逗号分隔。
1 UPDATE customers SET cust_name='The Fudds', cust_email='233@fudd.com' WHERE cust_id=10005;
2、如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出现一个错误,则整个UPDATE操作被取消(错误发生前更新的所有行被恢复到它们原来的值)。即使是发生错误,也继续更新,可使用IGNORE。UPDATE IGNORE table_name...
三、删除数据
使用DELETE语句。
如果想从表中删除所有行,不要使用DELETE。可使用TRUNCATE table_name语句,它完成相同的工作,但速度更快(TRUNCATE 实际上是删除原来的表并创建一个表,而不是逐行删除表中的数据)。
四、REPLACE INTO
1、REPLACE INTO跟INSERT INTO功能类似。不同点在于:REPLACE INTO 首先尝试插入数据到表中,如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据;如果表中没有此行数据,则直接插入新数据。
2、待插入数据的表必须有主键或者唯一索引,否则REPLACE INTO直接插入数据,将导致表中出现重复数据;如果表存在外键约束,则语句会执行错误。
3、例子
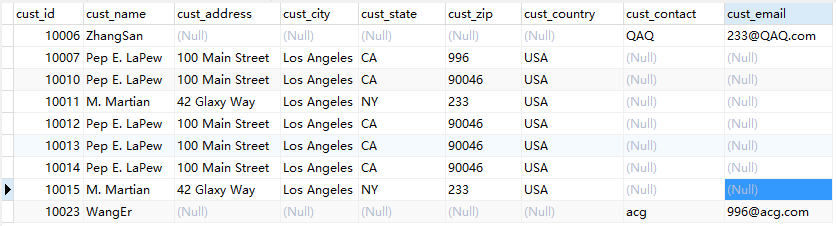
执行前:
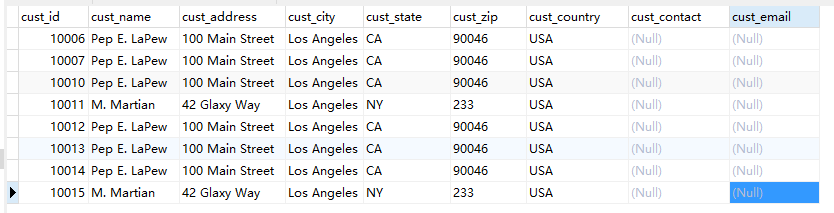
执行语句:
1 REPLACE INTO customers(cust_id,cust_name,cust_contact,cust_email) VALUES(10006,'ZhangSan','QAQ','233@QAQ.com');
执行结果:
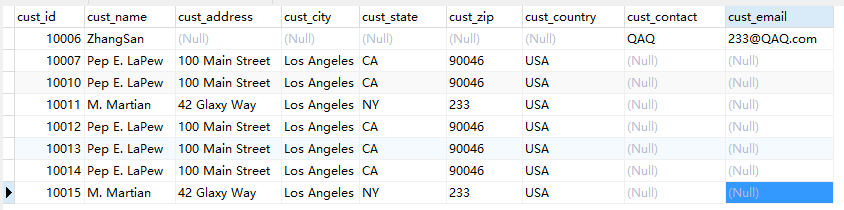
五、ON DUPLICATE KEY UPDATE
在MySQL数据库中,如果在INSERT语句后面带上ON DUPLICATE KEY UPDATE 子句,如果要插入的行与表中现有记录的惟一索引或主键产生重复值,那么就会发生旧行的更新(即执行UPDATE后面的操作);如果插入的行数据与现有表中记录的唯一索引或者主键不重复,则执行新记录插入操作(即执行INSERT的操作)。
执行前:
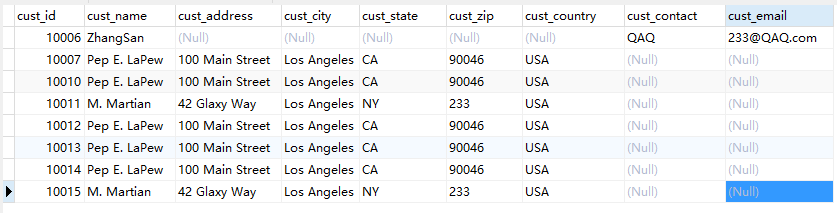
执行语句:
1 INSERT INTO customers(cust_id,cust_name,cust_contact,cust_email) VALUES(10007,'WangEr','acg','996@acg.com') 2 ON DUPLICATE KEY UPDATE cust_zip=996;
执行结果:
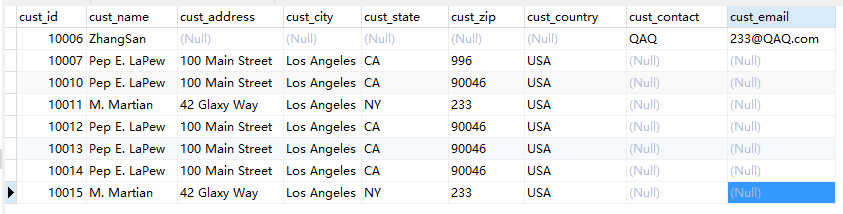
执行语句:
INSERT INTO customers(cust_id,cust_name,cust_contact,cust_email) VALUES(10023,'WangEr','acg','996@acg.com') ON DUPLICATE KEY UPDATE cust_zip=996;
执行结果: