背景:前几天复习Java的时候看到URL类,当时就想写个小程序试试,迫于考试没有动手,今天写了下,感觉还不错
内容1. 抓取网页中的URL
知识点:Java URL+ 正则表达式
1 import java.io.BufferedReader; 2 import java.io.InputStreamReader; 3 import java.net.URL; 4 import java.util.regex.Matcher; 5 import java.util.regex.Pattern; 6 7 public class URLReader { 8 public static void main(String[] args) throws Exception { 9 System.out.println("开始!"); 10 Pattern pattern = Pattern.compile("http(s)?://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?"); 11 URL baidu = new URL("http://www.cnblogs.com/A--Q/"); 12 BufferedReader br = new BufferedReader(new InputStreamReader(baidu.openStream(), "utf-8")); 13 String inputLine; 14 while ((inputLine = br.readLine()) != null) { 15 Matcher matcher = pattern.matcher(inputLine); 16 while (matcher.find()) { 17 System.out.println(matcher.group(0)); 18 } 19 } 20 br.close(); 21 System.out.println("程序执行结束!"); 22 } 23 }
效果:
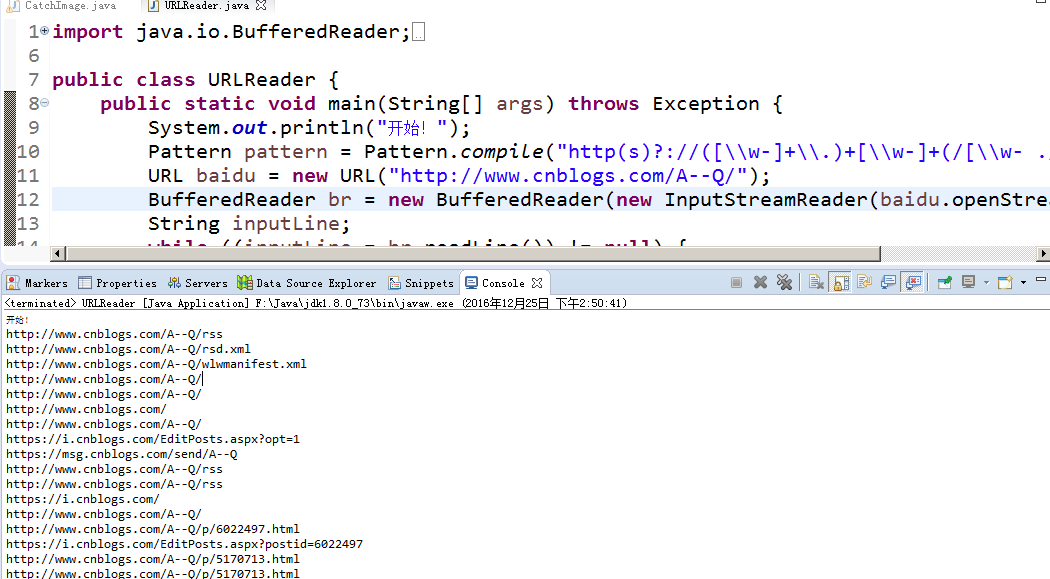
内容2. 抓取网页中的图片


1 import java.io.File; 2 import java.io.FileOutputStream; 3 import java.io.InputStream; 4 import java.net.URL; 5 import java.net.URLConnection; 6 import java.util.ArrayList; 7 import java.util.List; 8 import java.util.regex.Matcher; 9 import java.util.regex.Pattern; 10 11 public class CatchImage { 12 13 private static final String URL = "http://www.cnblogs.com/A--Q/p/5170713.html"; 14 private static final String ECODING = "UTF-8"; 15 private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>"; 16 private static final String IMGSRC_REG = "http:"?(.*?)("|>|\s+)"; 17 18 public static void main(String[] args) throws Exception { 19 System.out.println("start"); 20 CatchImage cm = new CatchImage(); 21 String HTML = cm.getHTML(URL); 22 List<String> imgUrl = cm.getImageUrl(HTML); 23 List<String> imgSrc = cm.getImageSrc(imgUrl); 24 cm.Download(imgSrc); 25 System.out.println("END"); 26 } 27 28 private String getHTML(String url) throws Exception { 29 URL uri = new URL(url); 30 URLConnection connection = uri.openConnection(); 31 InputStream in = connection.getInputStream(); 32 byte[] buf = new byte[1024]; 33 int length = 0; 34 StringBuffer sb = new StringBuffer(); 35 while ((length = in.read(buf, 0, buf.length)) > 0) { 36 sb.append(new String(buf, ECODING)); 37 } 38 in.close(); 39 return sb.toString(); 40 } 41 42 private List<String> getImageUrl(String HTML) { 43 Matcher matcher = Pattern.compile(IMGURL_REG).matcher(HTML); 44 List<String> listImgUrl = new ArrayList<String>(); 45 while (matcher.find()) { 46 listImgUrl.add(matcher.group()); 47 } 48 return listImgUrl; 49 } 50 51 private List<String> getImageSrc(List<String> listImageUrl) { 52 List<String> listImgSrc = new ArrayList<String>(); 53 for (String image : listImageUrl) { 54 Matcher matcher = Pattern.compile(IMGSRC_REG).matcher(image); 55 while (matcher.find()) { 56 listImgSrc.add(matcher.group().substring(0, matcher.group().length() - 1)); 57 } 58 } 59 return listImgSrc; 60 } 61 62 private void Download(List<String> listImgSrc) { 63 try { 64 for (String url : listImgSrc) { 65 String imageName = url.substring(url.lastIndexOf("/") + 1, url.length()); 66 URL uri = new URL(url); 67 InputStream in = uri.openStream(); 68 FileOutputStream fo = new FileOutputStream(new File(imageName)); 69 byte[] buf = new byte[1024]; 70 int length = 0; 71 System.out.println("开始下载:" + url); 72 while ((length = in.read(buf, 0, buf.length)) != -1) { 73 fo.write(buf, 0, length); 74 } 75 in.close(); 76 fo.close(); 77 System.out.println(imageName + "下载完成"); 78 } 79 } catch (Exception e) { 80 System.out.println("下载失败"); 81 } 82 } 83 84 }