最近在做ctf的时候,碰见了好几次关于php伪协议的妙用,所以通过学习整理出相关知识
文档:http://cn2.php.net/manual/zh/wrappers.php.php#refsect2-wrappers.php-unknown-descriptioo
php伪协议,事实上是其支持的协议与封装协议
支持的种类有这12种
* file:// — 访问本地文件系统
* http:// — 访问 HTTP(s) 网址
* ftp:// — 访问 FTP(s) URLs
* php:// — 访问各个输入/输出流(I/O streams)
* zlib:// — 压缩流
* data:// — 数据(RFC 2397)
* glob:// — 查找匹配的文件路径模式
* phar:// — PHP 归档
* ssh2:// — Secure Shell 2
* rar:// — RAR
* ogg:// — 音频流
* expect:// — 处理交互式的流
先整理一下关于php://的用法
php://
PHP 提供了一些杂项输入/输出(IO)流,允许访问 PHP 的输入输出流、标准输入输出和错误描述符, 内存中、磁盘备份的临时文件流以及可以操作其他读取写入文件资源的过滤器。
php://stdin, php://stdout 和 php://stderr
php://stdin、php://stdout 和 php://stderr 允许直接访问 PHP 进程相应的输入或者输出流。 数据流引用了复制的文件描述符,所以如果你打开php://stdin并在之后关了它, 仅是关闭了复制品,真正被引用的 STDIN 并不受影响。 推荐简单使用常量 STDIN、 STDOUT 和 STDERR 来代替手工打开这些封装器。
php://stdin是只读的,php://stdout 和 php://stderr 是只写的。
举例:
php://stdin
1 <?php 2 while($line = fopen('php://stdin','r')) 3 {//open our file pointer to read from stdin 4 echo $line." "; 5 echo fgets($line);//读取 6 } 7 ?>
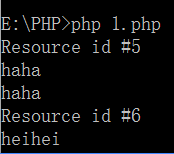
可以看到打开了一个文件指针进行读取
php://stdout
1 <?php 2 $fd = fopen('php://stdout', 'w'); 3 if ($fd) { 4 echo $fd." "; 5 fwrite($fd, "这是一个测试"); 6 fwrite($fd, " "); 7 fclose($fd); 8 } 9 ?>
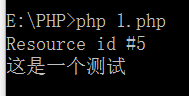
可以看到打开了一个文件指针进行写入
php://stderr
1 <?php 2 $stderr = fopen( 'php://stderr', 'w' ); 3 echo $stderr." "; 4 fwrite($stderr, "lalala" ); 5 fclose($stderr); 6 ?>

可以看到打开了一个文件指针进行写入
php://input
php://input 是个可以访问请求的原始数据的只读流。因为它不依赖于特定的 php.ini 指令。
注:enctype=”multipart/form-data” 的时候 php://input 是无效的。
举例:
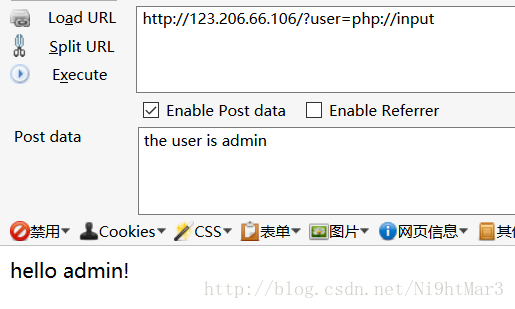
就拿最近的HBCTF的一道题吧
相关源码:
1 <!-- 2 $user = $_GET["user"]; 3 $file = $_GET["file"]; 4 $pass = $_GET["pass"]; 5 6 if(isset($user)&&(file_get_contents($user,'r')==="the user is admin")){ 7 echo "hello admin!<br>"; 8 include($file); //class.php 9 }else{ 10 echo "you are not admin ! "; 11 }
php://output
php://output 是一个只写的数据流, 允许你以 print 和 echo 一样的方式 写入到输出缓冲区。
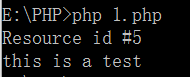
举例:
1 <?php 2 $out=fopen("php://stdout", 'w'); 3 echo $out." "; 4 fwrite($out , "this is a test"); 5 fclose($out); 6 ?>
php://fd
php://fd 允许直接访问指定的文件描述符。 例如 php://fd/3 引用了文件描述符 3。
php://memory 和 php://temp
php://memory 和 php://temp 是一个类似文件 包装器的数据流,允许读写临时数据。 两者的唯一区别是 php://memory 总是把数据储存在内存中, 而 php://temp 会在内存量达到预定义的限制后(默认是 2MB)存入临时文件中。 临时文件位置的决定和 sys_get_temp_dir() 的方式一致。
php://temp 的内存限制可通过添加 /maxmemory:NN 来控制,NN 是以字节为单位、保留在内存的最大数据量,超过则使用临时文件。
php://filter
可以说这是最常使用的一个伪协议,一般可以利用进行任意文件读取。
php://filter 是一种元封装器, 设计用于数据流打开时的筛选过滤应用。 这对于一体式(all-in-one)的文件函数非常有用,类似 readfile()、 file() 和 file_get_contents(), 在数据流内容读取之前没有机会应用其他过滤器。
php://filter 参数

封装协议摘要(针对 php://filter,参考被筛选的封装器。)

举例:
依旧拿HBCTF举例好啦

明显将class.php的代码以base64的形式输出,当然也可以试试字符转成rot13形式

这就涉及过滤器的灵活使用
php://filter/read=<读链需要应用的过滤器列表>
这个参数采用一个或以管道符 | 分隔的多个过滤器名称。

过滤器
过滤器有很多种,有字符串过滤器、转换过滤器、压缩过滤器、加密过滤器
字符串过滤器
- string.rot13
-
进行rot13转换
string.toupper
将字符全部大写
string.tolower
将字符全部小写
string.strip_tags
去除空字符、HTML 和 PHP 标记后的结果
着重介绍一下这个,功能类似于strip_tags()函数,若不想某些字符不被消除,后面跟上字符,可利用字符串或是数组两种方式
举例
1 <?php 2 $fp = fopen('php://output', 'w'); 3 stream_filter_append($fp, 'string.rot13'); 4 echo "rot13:"; 5 fwrite($fp, "This is a test. "); 6 fclose($fp); 7 8 $fp = fopen('php://output', 'w'); 9 stream_filter_append($fp, 'string.toupper'); 10 echo "Upper:"; 11 fwrite($fp, "This is a test. "); 12 fclose($fp); 13 14 $fp = fopen('php://output', 'w'); 15 stream_filter_append($fp, 'string.tolower'); 16 echo "Lower:"; 17 fwrite($fp, "This is a test. "); 18 fclose($fp); 19 20 $fp = fopen('php://output', 'w'); 21 echo "Del1:"; 22 stream_filter_append($fp, 'string.strip_tags', STREAM_FILTER_WRITE); 23 fwrite($fp, "<b>This is a test.</b>!!!!<h1>~~~~</h1> "); 24 fclose($fp); 25 26 $fp = fopen('php://output', 'w'); 27 echo "Del2:"; 28 stream_filter_append($fp, 'string.strip_tags', STREAM_FILTER_WRITE, "<b>"); 29 fwrite($fp, "<b>This is a test.</b>!!!!<h1>~~~~</h1> "); 30 fclose($fp); 31 32 $fp = fopen('php://output', 'w'); 33 stream_filter_append($fp, 'string.strip_tags', STREAM_FILTER_WRITE, array('b','h1')); 34 echo "Del3:"; 35 fwrite($fp, "<b>This is a test.</b>!!!!<h1>~~~~</h1> "); 36 fclose($fp); 37 ?>

转换过滤器
- convert.base64-encode & convert.base64-decode
base64 编码解码
convert.base64-encode和convert.base64-decode使用这两个过滤器等同于分别用 base64_encode()和 base64_decode()函数处理所有的流数据。 convert.base64-encode支持以一个关联数组给出的参数。如果给出了line-length,base64 输出将被用 line-length个字符为长度而截成块。如果给出了* line-break-chars*,每块将被用给出的字符隔开。这些参数的效果和用 base64_encode()再加上 chunk_split()相同。
convert.quoted-printable-encode & convert.quoted-printable-decode
quoted-printable 编码解码
convert.quoted-printable-encode和 convert.quoted-printable-decode等同于用 quoted_printable_decode()函数处理所有的流数据。没有和* convert.quoted-printable-encode*相对应的函数。* convert.quoted-printable-encode*支持以一个关联数组给出的参数。除了支持和 convert.base64-encode一样的附加参数外,* convert.quoted-printable-encode*还支持布尔参数 binary和 force-encode-first。 convert.base64-decode只支持 line-break-chars参数作为从编码载荷中剥离的类型提示。
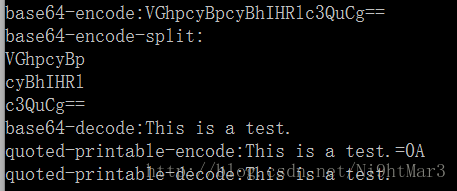
举例:
1 <?php 2 $fp = fopen('php://output', 'w'); 3 stream_filter_append($fp, 'convert.base64-encode'); 4 echo "base64-encode:"; 5 fwrite($fp, "This is a test. "); 6 fclose($fp); 7 8 $param = array('line-length' => 8, 'line-break-chars' => " "); 9 $fp = fopen('php://output', 'w'); 10 stream_filter_append($fp, 'convert.base64-encode', STREAM_FILTER_WRITE, $param); 11 echo " base64-encode-split: "; 12 fwrite($fp, "This is a test. "); 13 fclose($fp); 14 15 $fp = fopen('php://output', 'w'); 16 stream_filter_append($fp, 'convert.base64-decode'); 17 echo " base64-decode:"; 18 fwrite($fp, "VGhpcyBpcyBhIHRlc3QuCg== "); 19 fclose($fp); 20 21 $fp = fopen('php://output', 'w'); 22 stream_filter_append($fp, 'convert.quoted-printable-encode'); 23 echo "quoted-printable-encode:"; 24 fwrite($fp, "This is a test. "); 25 fclose($fp); 26 27 $fp = fopen('php://output', 'w'); 28 stream_filter_append($fp, 'convert.quoted-printable-decode'); 29 echo " quoted-printable-decode:"; 30 fwrite($fp, "This is a test.=0A"); 31 fclose($fp); 32 ?>
压缩过滤器
zlib.deflate和 zlib.inflate
zlib.deflate(压缩)和 zlib.inflate(解压)实现了定义与 » RFC 1951的压缩算法。 deflate过滤器可以接受以一个关联数组传递的最多三个参数。* level*定义了压缩强度(1-9)。数字更高通常会产生更小的载荷,但要消耗更多的处理时间。存在两个特殊压缩等级:0(完全不压缩)和 -1(zlib 内部默认值,目前是 6)。 window是压缩回溯窗口大小,以二的次方表示。更高的值(大到 15 —— 32768 字节)产生更好的压缩效果但消耗更多内存,低的值(低到 9 —— 512 字节)产生产生较差的压缩效果但内存消耗低。目前默认的 window大小是 15。 memory用来指示要分配多少工作内存。合法的数值范围是从 1(最小分配)到 9(最大分配)。内存分配仅影响速度,不会影响生成的载荷的大小。
Note: 因为最常用的参数是压缩等级,也可以提供一个整数值作为此参数(而不用数组)。
bzip2.compress和 bzip2.decompress
bzip2.compress过滤器接受以一个关联数组给出的最多两个参数:* blocks*是从 1 到 9 的整数值,指定分配多少个 100K 字节的内存块作为工作区。 work是 0 到 250 的整数值,指定在退回到一个慢一些,但更可靠的算法之前做多少次常规压缩算法的尝试。调整此参数仅影响到速度,压缩输出和内存使用都不受此设置的影响。将此参数设为 0 指示 bzip 库使用内部默认算法。 bzip2.decompress过滤器仅接受一个参数,可以用普通的布尔值传递,或者用一个关联数组中的* small*单元传递。当* small*设为&true; 值时,指示 bzip 库用最小的内存占用来执行解压缩,代价是速度会慢一些。
phper在进阶的时候总会遇到一些问题和瓶颈,业务代码写多了没有方向感,不知道该从那里入手去提升,对此我整理了一些资料,包括但不限于:分布式架构、高可扩展、高性能、高并发、服务器性能调优、TP6,laravel,YII2,Redis,Swoole、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等多个知识点高级进阶干货需要的可以免费分享给大家,需要的请点击(→)我的官方群
加密过滤器
_mcrypt.*_和 _mdecrypt.*_使用 libmcrypt 提供了对称的加密和解密。这两组过滤器都支持 mcrypt 扩展库中相同的算法,格式为_mcrypt.ciphername_,其中 ciphername是密码的名字,将被传递给 mcrypt_module_open()。有以下五个过滤器参数可用:
mcrypt 过滤器参数