人工智能-机器学习-深度学习
他们之间是有区别的
先来一张图做一下解释

从发展历史上来看
AI:让机器展现出人类智力
回到1956年夏天,在当时的会议上,AI先驱的梦想是建造一台复杂的机器(让当时刚出现的计算机驱动),然后让机器呈现出人类智力的特征。
这一概念就是我们所说的“强人工智能(General AI)”,也就是打造一台超棒的机器,让它拥有人类的所有感知,甚至还可以超越人类感知,它可以像人一样思考。在电影中我们经常会看到这种机器,比如 C-3PO、终结者。
还有一个概念是“弱人工智能(Narrow AI)”。简单来讲,“弱人工智能”可以像人类一样完成某些具体任务,有可能比人类做得更好,例如,Pinterest服务用AI给图片分类,Facebook用AI识别脸部,这就是“弱人工智能”。
上述例子是“弱人工智能”实际使用的案例,这些应用已经体现了一些人类智力的特点。怎样实现的?这些智力来自何处?带着问题我们深入理解,就来到下一个圆圈,它就是机器学习。
机器学习:抵达AI目标的一条路径
大体来讲,机器学习就是用算法真正解析数据,不断学习,然后对世界中发生的事做出判断和预测。此时,研究人员不会亲手编写软件、确定特殊指令集、然后让程序完成特殊任务,相反,研究人员会用大量数据和算法“训练”机器,让机器学会如何执行任务。
机器学习这个概念是早期的AI研究者提出的,在过去几年里,机器学习出现了许多算法方法,包括决策树学习、归纳逻辑程序设计、聚类分析(Clustering)、强化学习、贝叶斯网络等。正如大家所知的,没有人真正达到“强人工智能”的终极目标,采用早期机器学习方法,我们连“弱人工智能”的目标也远没有达到。
在过去许多年里,机器学习的最佳应用案例是“计算机视觉”,要实现计算机视觉,研究人员仍然需要手动编写大量代码才能完成任务。研究人员手动编写分级器,比如边缘检测滤波器,只有这样程序才能确定对象从哪里开始,到哪里结束;形状侦测可以确定对象是否有8条边;分类器可以识别字符“S-T-O-P”。通过手动编写的分组器,研究人员可以开发出算法识别有意义的形象,然后学会下判断,确定它不是一个停止标志。
这种办法可以用,但并不是很好。如果是在雾天,当标志的能见度比较低,或者一棵树挡住了标志的一部分,它的识别能力就会下降。直到不久之前,计算机视觉和图像侦测技术还与人类的能力相去甚远,因为它太容易出错了。
深度学习:实现机器学习的技术
“人工神经网络(Artificial Neural Networks)”是另一种算法方法,它也是早期机器学习专家提出的,存在已经几十年了。神经网络(Neural Networks)的构想源自于我们对人类大脑的理解——神经元的彼此联系。二者也有不同之处,人类大脑的神经元按特定的物理距离连接的,人工神经网络有独立的层、连接,还有数据传播方向。
例如,你可能会抽取一张图片,将它剪成许多块,然后植入到神经网络的第一层。第一层独立神经元会将数据传输到第二层,第二层神经元也有自己的使命,一直持续下去,直到最后一层,并生成最终结果。
每一个神经元会对输入的信息进行权衡,确定权重,搞清它与所执行任务的关系,比如有多正确或者多么不正确。最终的结果由所有权重来决定。以停止标志为例,我们会将停止标志图片切割,让神经元检测,比如它的八角形形状、红色、与众不同的字符、交通标志尺寸、手势等。
神经网络的任务就是给出结论:它到底是不是停止标志。神经网络会给出一个“概率向量”,它依赖于有根据的推测和权重。在该案例中,系统有86%的信心确定图片是停止标志,7%的信心确定它是限速标志,有5%的信心确定它是一支风筝卡在树上,等等。然后网络架构会告诉神经网络它的判断是否正确。
即使只是这么简单的一件事也是很超前的,不久前,AI研究社区还在回避神经网络。在AI发展初期就已经存在神经网络,但是它并没有形成多少“智力”。问题在于即使只是基本的神经网络,它对计算量的要求也很高,因此无法成为一种实际的方法。尽管如此,还是有少数研究团队勇往直前,比如多伦多大学Geoffrey Hinton所领导的团队,他们将算法平行放进超级电脑,验证自己的概念,直到GPU开始广泛采用我们才真正看到希望。
回到识别停止标志的例子,如果我们对网络进行训练,用大量的错误答案训练网络,调整网络,结果就会更好。研究人员需要做的就是训练,他们要收集几万张、甚至几百万张图片,直到人工神经元输入的权重高度精准,让每一次判断都正确为止——不管是有雾还是没雾,是阳光明媚还是下雨都不受影响。这时神经网络就可以自己“教”自己,搞清停止标志的到底是怎样的;它还可以识别Facebook的人脸图像,可以识别猫——吴恩达(Andrew Ng)2012年在谷歌做的事情就是让神经网络识别猫。
吴恩达的突破之处在于:让神经网络变得无比巨大,不断增加层数和神经元数量,让系统运行大量数据,训练它。吴恩达的项目从1000万段YouTube视频调用图片,他真正让深度学习有了“深度”。
到了今天,在某些场景中,经过深度学习技术训练的机器在识别图像时比人类更好,比如识别猫、识别血液中的癌细胞特征、识别MRI扫描图片中的肿瘤。谷歌AlphaGo学习围棋,它自己与自己不断下围棋并从中学习。
机器学习和深度学习的对比:
数据依赖性
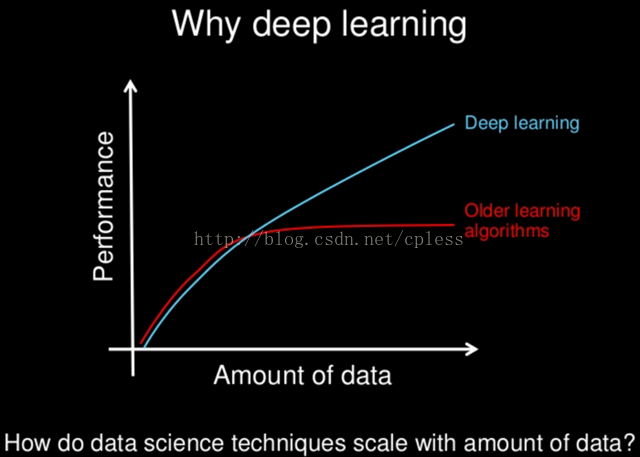
深度学习与传统的机器学习最主要的区别在于随着数据规模的增加其性能也不断增长。当数据很少时,深度学习算法的性能并不好。这是因为深度学习算法需要大量的数据来完美地理解它。另一方面,在这种情况下,传统的机器学习算法使用制定的规则,性能会比较好。下图总结了这一事实。
硬件依赖
深度学习算法需要进行大量的矩阵运算,GPU 主要用来高效优化矩阵运算,所以 GPU 是深度学习正常工作的必须硬件。与传统机器学习算法相比,深度学习更依赖安装 GPU 的高端机器。
特征处理
特征处理是将领域知识放入特征提取器里面来减少数据的复杂度并生成使学习算法工作的更好的模式的过程。特征处理过程很耗时而且需要专业知识。
在机器学习中,大多数应用的特征都需要专家确定然后编码为一种数据类型。
特征可以使像素值、形状、纹理、位置和方向。大多数机器学习算法的性能依赖于所提取的特征的准确度。
深度学习尝试从数据中直接获取高等级的特征,这是深度学习与传统机器学习算法的主要的不同。基于此,深度学习削减了对每一个问题设计特征提取器的工作。例如,卷积神经网络尝试在前边的层学习低等级的特征(边界,线条),然后学习部分人脸,然后是高级的人脸的描述。
问题解决方式
当应用传统机器学习算法解决问题的时候,传统机器学习通常会将问题分解为多个子问题并逐个子问题解决最后结合所有子问题的结果获得最终结果。相反,深度学习提倡直接的端到端的解决问题。
执行时间
通常情况下,训练一个深度学习算法需要很长的时间。这是因为深度学习算法中参数很多,因此训练算法需要消耗更长的时间。最先进的深度学习算法 ResNet完整地训练一次需要消耗两周的时间,而机器学习的训练会消耗的时间相对较少,只需要几秒钟到几小时的时间。
但两者测试的时间上是完全相反。深度学习算法在测试时只需要很少的时间去运行。如果跟 k-nearest neighbors(一种机器学习算法)相比较,测试时间会随着数据量的提升而增加。不过这不适用于所有的机器学习算法,因为有些机器学习算法的测试时间也很短。
可解释性
至关重要的一点,我们把可解释性作为比较机器学习和深度学习的一个因素。
我们看个例子。假设我们适用深度学习去自动为文章评分。深度学习可以达到接近人的标准,这是相当惊人的性能表现。但是这仍然有个问题。深度学习算法不会告诉你为什么它会给出这个分数。当然,在数学的角度上,你可以找出来哪一个深度神经网络节点被激活了。但是我们不知道神经元应该是什么模型,我们也不知道这些神经单元层要共同做什么。所以无法解释结果是如何产生的。
另一方面,为了解释为什么算法这样选择,像决策树(decision trees)这样机器学习算法给出了明确的规则,所以解释决策背后的推理是很容易的。因此,决策树和线性/逻辑回归这样的算法主要用于工业上的可解释性。