一、正则表达式的创建方式:
var reg = /pattern/flags
// 字面量创建方式
var reg = new RegExp(pattern,flags);
//实例创建方式
其中:
pattern:正则表达式
flags:标识(修饰符)
标识主要包括:
1. i 忽略大小写匹配
2. m 多行匹配,即在到达一行文本末尾时还会继续寻常下一行中是否与正则匹配的项
3. g 全局匹配 模式应用于所有字符串,而非在找到第一个匹配项时停止
二、元字符(代表字母和数字不能匹配的(元义字符)):
代表特殊含义的元字符
d : 0-9之间的任意一个数字 d只占一个位置
w : 数字,字母 ,下划线 0-9 a-z A-Z _
s : 空格或者空白等
D : 除了d
W : 除了w
S : 除了s
. : 除了
之外的任意一个字符
: 转义字符
| : 或者
() : 分组
n : 匹配换行符
b : 匹配边界 字符串的开头和结尾 空格的两边都是边界 => 不占用字符串位数
^ : 限定开始位置 => 本身不占位置
$ : 限定结束位置 => 本身不占位置
[a-z] : 任意字母 []中的表示任意一个都可以
[^a-z] : 非字母 []中^代表除了
[abc] : abc三个字母中的任何一个 [^abc]除了这三个字母中的任何一个字符代表次数的量词元字符
* : 0到多个
+ : 1到多个
? : 0次或1次 可有可无
{n} : 正好n次;
{n,} : n到多次
{n,m} : n次到m次
1、字符类
●匹配字符:
1.一个字符匹配 字符 eg:ab → ab(tab键)
2.一类字符匹配(有类其中一个即可) [ ] eg:[abc] → 有abc中一个即可。


2、范围类

匹配大小写字母

匹配-

3、.边界和预定于类


eg:
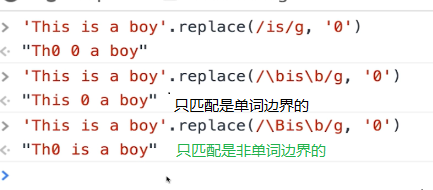
4、量词

五、贪婪模式与非贪婪模式
贪婪模式:尽可能的匹配多的次数

六、test和exec


七、字符串对象方法


