Rank
1.函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
2.数据准备(手巧时切记用tab分开,不要用空格,会报错0
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
3.需求
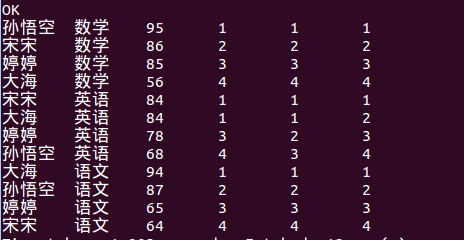
计算每门学科成绩排名。
4.数据导入
(1)数据导入hive数据库
//创建数据表
create table score( > > name string, > > subject string, > > score int) > > row format delimited fields terminated by " ";//一行中每列数据用 切分
load data local inpath '/home/hadoop/file/score' into table score;/home/hadoop/file/score是我的文件路径和文件名
5.查询语句
select name,subject,score, rank() over(partition by subject order by score desc) rp, dense_rank() over(partition by subject order by score desc) drp, row_number() over(partition by subject order by score desc) rmp from score;
6.结果显示