1.1 AI Studio
AI Studio是百度推出的一站式开发平台,其中囊括了AI教程、代码环境,算法算力、数据集,并提供免费的在线云计算一体化编程环境。它是一个基于PadddlePaddle的集成了大量数据集、经典样例项目及比赛项目的云计算建模平台,也是一个机器学习、深度学习的交流社区,在云端集成计算资源、项目管理、代码管理,比赛等多种功能。
1.1.1 AI Studio功能
AI Studio主要功能项目类(包括项目大厅、创建项目等),有经典数据集合自定义数据集,还有各种精选项目课程,提供各种数据科学比赛报名通道。
- 项目类:项目大厅包含各种项目分享,其中也有细致的专题分类例如新手入门、进阶项目、高阶任务、飞桨模型等;同时也包含自我创建项目,自我的项目管理。AI Studio是以项目为核心,以技术及资源输出帮助个人开发者,中小企业快速拥有AI能力以更好的服务自身业务。
- 数据集:AI Studio平台汇集海量开放数据,链接真实业务场景。其中公开数据集包含有房价预测、人流密度预测数据集等,用户也可上传自定义数据集进行模型开发。
- 课程:此平台提供有大量精选项目课程,详细教学深度学习和机器学习,飞桨深度学习学院提供有AI快车道助力企业开发者快速应用深度学习技术,提供有PaddleCamp一线讲师教学,支持中国科学院大学等高校开课,NURD等开课机构共同助力培养社会人才。PaddlePaddle不仅有机器学习、深度学习的视频公开课和教程文档,而且包含了大量的各个方向的深度学习实例。
- 比赛:为用户提供了各种比赛渠道(飞桨大赛、飞桨常规赛、新人练习赛)并且提供了云端训练平台,使得比赛者公平竞争。拥有详细的比赛介绍以及赛提说明,社区也相对活跃完善。
1.1.2 fork项目
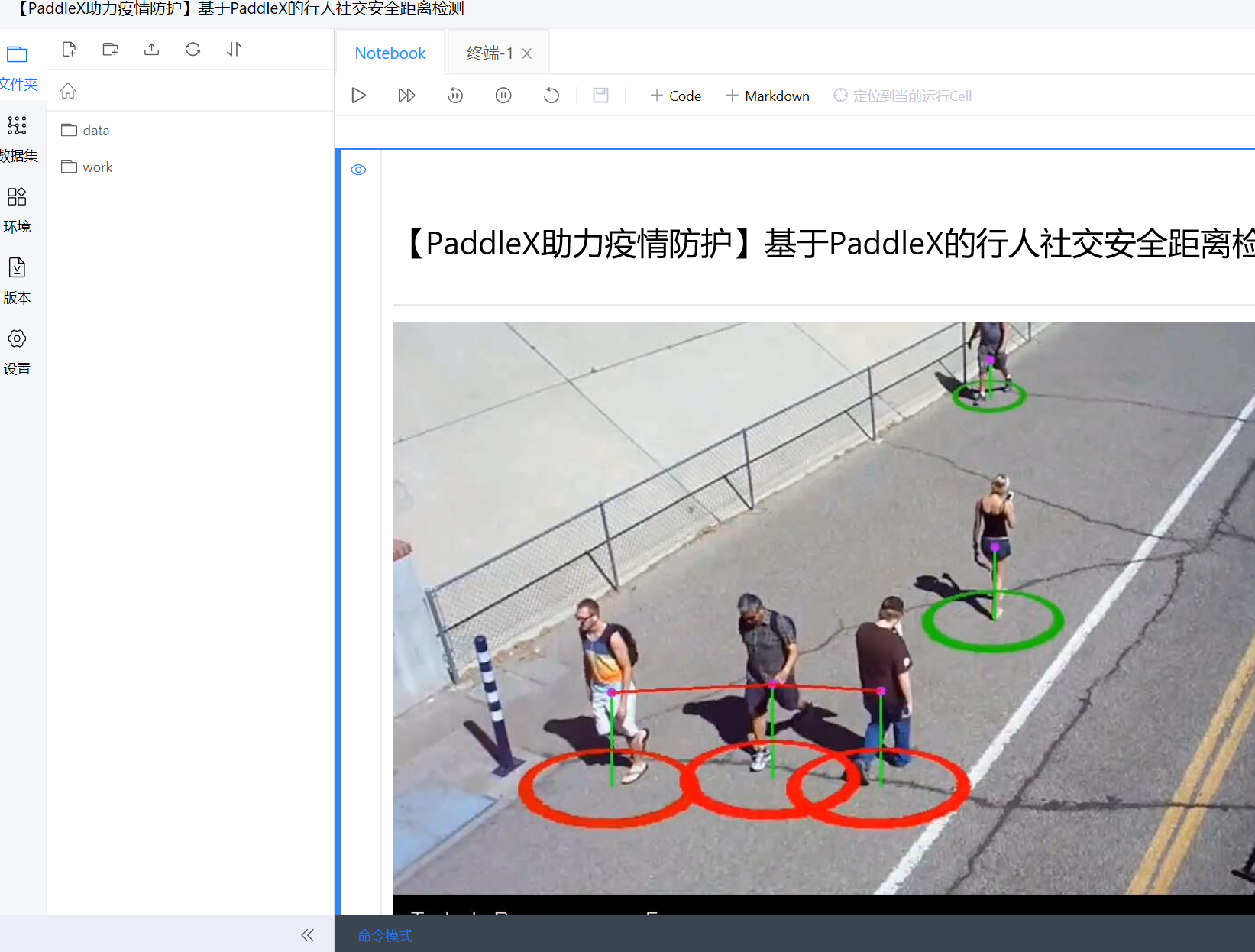
下图将fork“基于PaddleX的行人社交安全距离检测”项目。
2.1 Python
2.1.1 fork一个python基础语法项目

2.1.2 Python语法
1、变量与基本数据类型:每一个变量在使用前必须赋值,但变量赋值不需要数据类型的声明。
2、标识符:Python中,标识符由字母、数字、下划线组成,所有的标识符可以包括英文、数字和下划线,但是不能以数字开头。
3、数据类型
- 数字数据类型:int型(整型)、float型 (浮点型)、complex型(复数型)。
- 布尔类型:True和False。
4、基本运算 - 算术运算:算术运算符包括:+、-、*、/、//、%
- 比较运算:比较运算符包括:<、>、==、>=、<=、!=
- 赋值运算、逻辑运算
5、List列表、Tuple元组、Set集合、Dictionary字典 - List列表:列表是Python中使用最为频繁的数据类型,是写在[]之间,元素之间用逗号隔开。
- Tuple元组:元组与列表类似,不同点在于元组不可修改,元组写在小括号里(),元素之间用逗号分隔开。
- Set集合:集合是一个无序且不含重复元素的序列,主要用来进行成员关系测试和删除重复元素,可以使用大括号{}或者set()函数创建集合
- Dictionary字典:字典是一种映射类型,用"{}"表示,它是一个无序的键(key):值(value)对集合。
6、基本结构:三种基本结构,包括顺序、选择和循环。
3.1 Jupyter Notebook
Jupyter Notebook是一个开放源代码项目,定义的基于web的交互式编程方法已经逐渐成为全球数据科学、机器学习、深度学习领域的前端标准。AI studio Notebook是在Jupyter Notebook基础上开发的。通过AI Studio Notebook,可以使用Jupyter Notebook,完全不需要在自己的计算机上下载、安装或运行任何内容,只要有浏览器就可以使用。它支持超过40种编程语言,包括PYTHON、Julia等;能够分享笔记本,可以使用电子邮件、Dropbox、GitHub和Jupyter Notebook Viewer与他人共享;可以做到交互式输出,代码可以生成丰富的交互式输出,包括HTML、图像、视频等;可以大数据整合,通过Python、R、Scala编程语言使用Apache Spark等大数据框架工具,支持使用pandas等来探索同一份数据。
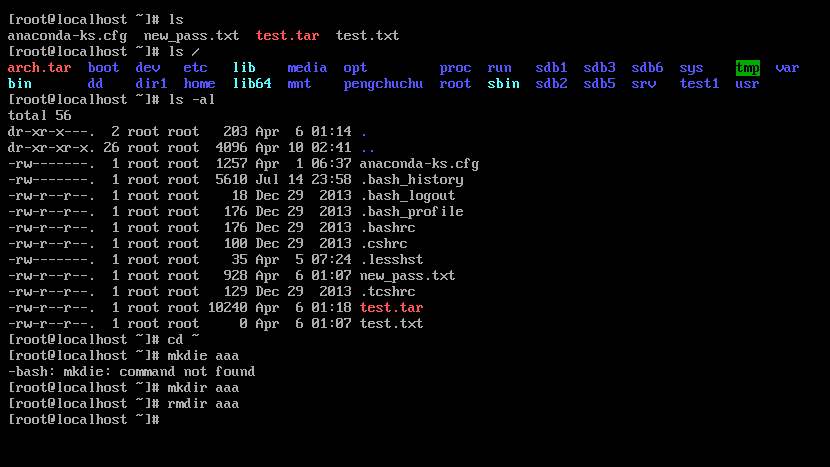
4.1 Linux基本命令

5.1 fork与课题有关的项目
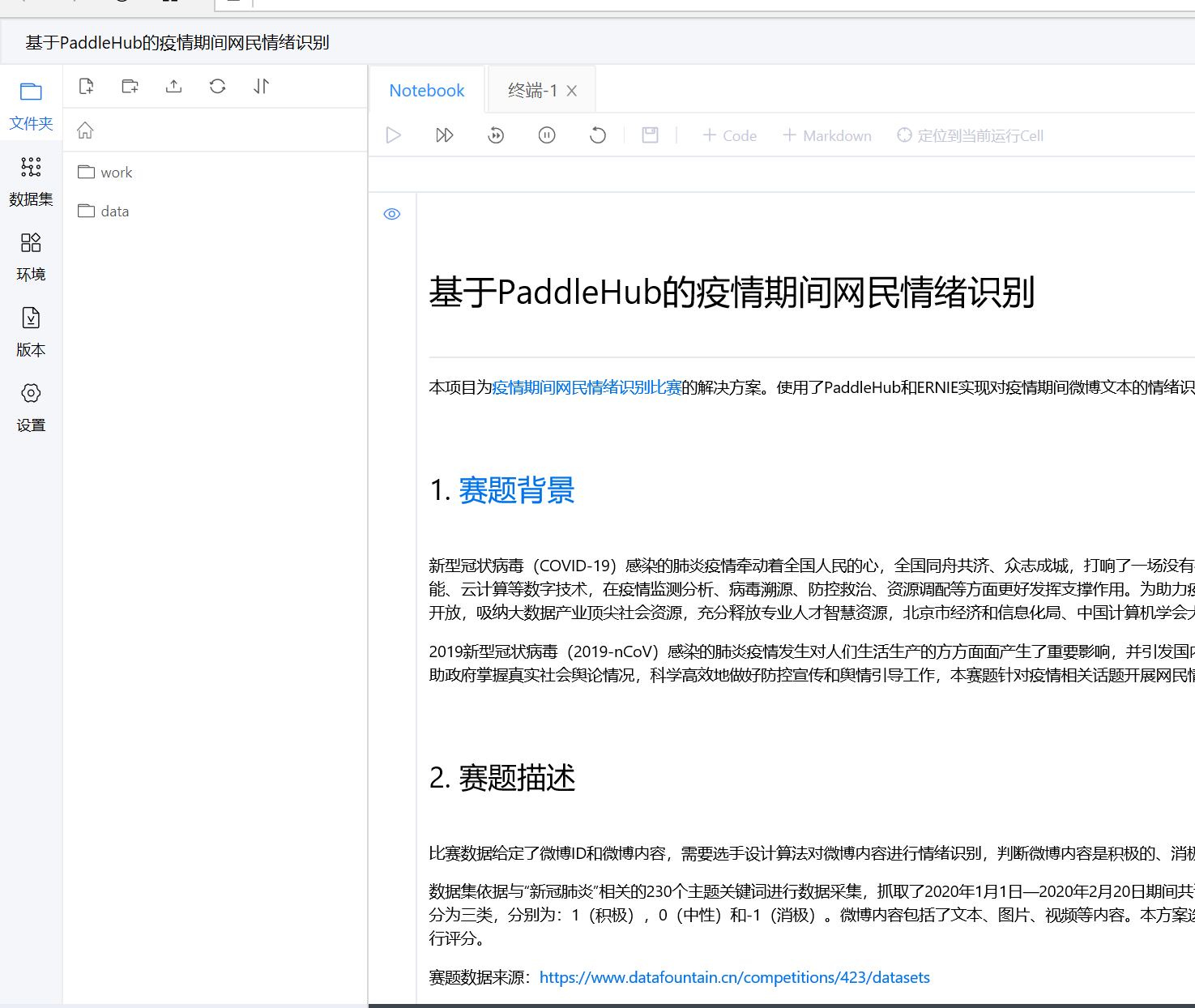
该项目首先进行数据整理,将数据划分为训练集和验证集;其次进行自定义数据加载,加载文本类自定义数据集,用户仅需继承基类BaseNLPDatast,修改数据集存放地址以及类别即可;然后加载模型;构建Reader,构建一个文本分类的reader;其次进行finetune策略,选择迁移优化策略;运行配置、开始finetune进行预测,最终生成结果。
在做该项目时,采用paddlehub预训练模型微调工具,快读构建比赛方案,不需要繁琐的代码就可以快速切换不同模型进行效果验证。