>>>点击网址后,应用层的DNS协议会将网址解析为IP地址;
DNS查找过程:
1. 浏览器会检查缓存中有没有这个域名对应的解析过的IP地址,如果缓存中有,这个解析过程就将结束。
2. 如果用户的浏览器缓存中没有,浏览器会查找操作系统缓存(hosts文件)中是否有这个域名对应的DNS解析结果。
3. 若还没有,此时会发送一个数据包给DNS服务器,DNS服务器找到后将解析所得IP地址返回给用户。
>>>在应用层,浏览器会给web服务器发送一个HTTP请求;
请求头为:GET http://www.baidu.com/HTTP/1.1
>>>在传输层,(上层的传输数据流分段)HTTP数据包会嵌入在TCP报文段中;
TCP报文段需要设置端口,接收方(百度)的HTTP端口默认是80,本机的端口是一个1024-65535之间的随机整数,这里假设为1025,这样TCP报文段由TCP首部(包含发送方和接收方的端口信息)+ HTTP数据包组成。
>>>在网络层中,TCP报文段再嵌入IP数据包中;
IP数据包需要知道双方的IP地址,本机IP地址假定为192.168.1.5,接受方IP地址为220.181.111.147(百度),这样IP数据包由IP头部(IP地址信息)+TCP报文段组成。
>>> 在网络接口层,IP数据包嵌入到数据帧(以太网数据包)中在网络上传送;
数据帧中包含源MAC地址和目的MAC地址(通过ARP地址解析协议得到的)。这样数据帧由头部(MAC地址)+IP数据包组成。
>>>数据包经过多个网关的转发到达百度服务器,请求对应端口的服务;
服务接收到发送过来的以太网数据包开始解析请求信息,从以太网数据包中提取IP数据包—>TCP报文段—>HTTP数据包,并组装为有效数据交与对应线程池中分配的线程进行处理,在这个过程中,生成相应request、response对象。

>>>请求处理完成之后,服务器发回一个HTTP响应;
请求处理程序会阅读请求及它的参数和cookies。它会读取也可能更新一些数据,并将数据存储在服务器上。处理完毕后,数据通过response对象给客户输出信息,输出信息也需要拼接HTTP协议头部分,关闭后断开连接。断开后,服务器端自动注销request、response对象,并将释放对应线程的使用标识(一般一个请求单独由一个线程处理,部分特殊情况有一个线程处理多个请求的情况)。
响应头为:HTTP/1.1200 OK
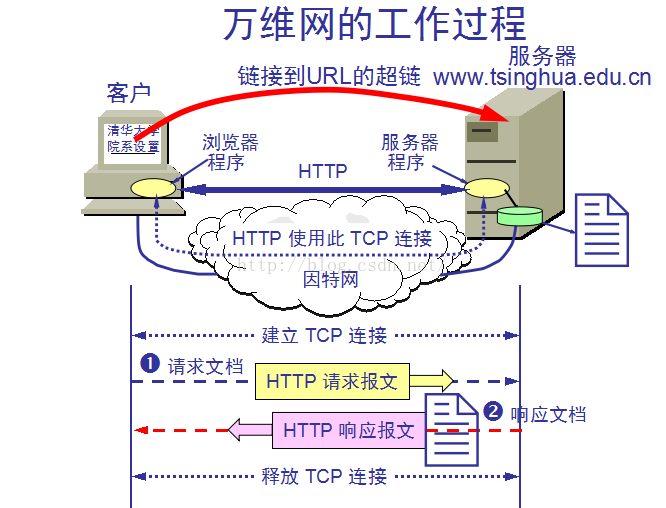
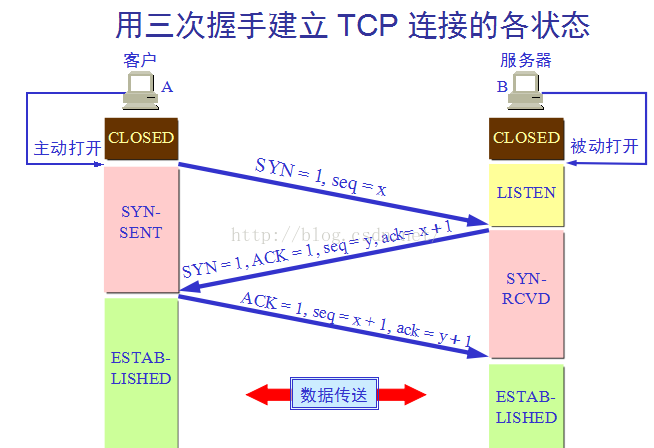
>>>浏览器以同样的过程读取到HTTP响应的内容(HTTP响应数据包),然后浏览器对接收到的HTML页面进行解析,把网页显示出来呈现给用户。
客户端接收到返回数据,去掉对应头信息,形成也可以被浏览器认识的页面HTML字符串信息,交与浏览器翻译为对应页面规则信息展示为页面内容。
