处理查询所涉及的最重要最复杂的组件是查询优化器,优化器的任务是为批处理或存储过程中的每个查询生成高效的执行计划,执行计划列出了sql server要执行查询所必须完成的步骤,并包含一些其它信息,如从查询中的每个表访问数据时使用的索引,执行计划还包含处理每个联接,聚合,排序和分区表。查询优化器会选择能最快把结果返回给用户且资源成本又比较合理的查询。例如,并行处理查询(使用多个CPU同时处理一个查询)通常比只使用一个CPU会消耗更多的资源。但并行执行查询要快得多。优化器主张使用并行计划返回结果,而且如果对该服务器上的负载不会产生负面影响,SQL Server将并行计划来执行。
优化本身包括几个步骤,细微优化计划:如果SQL SERVER通过分析该查询及相关的元数据得知该查询只有一种可行的计划,它就可以避免初始化和执行基于成本优化所需的大量工作。一个常见的例子是由带有VALUES子句的INSERT语句,这种情况只有一种可能的计划。另一个例子是不带索引不带GROUP BY 的SELECT查询。这两种情况下SQL SERVER只生成一个计划,不再尝试寻求更好的计划。
优化器简化,如果优化器没有找到细微计划,SQL SERVER将执行一些简化,在联接之前计算表的WHERE筛选器就是一个简化的例子,逻辑上筛选器应该在联接之后计算,但在联接之前计算筛选器也会得到正确,而且这样总是更高效,因为它在联接操作之前已经移除了不符合条件的行。简化的另一个例子是把外部联接转换成内部联接,通常外部联接将向内部联接的集添加行,如果有一些内部行不满足联接谓词,这些附加行在内部集的所有列上都是NULL。因此如果有一个对内部集的谓词来过滤这些行,外部联接的结果将与内部联接的结果相同,而且生成外部联接结果集的成本永远比内部联接高。因此SQL SERVER会在简化期间把这种外部链接改成内部联接。
如下SQL语句,LEFT OUTER JOIN,谓词products.unitprice>10过滤掉了所有outer join产生的额外行,因此outer join被简化为inner join
select productname,Products.ProductID
from dbo.[Order Details]
left outer join dbo.Products
on [Order Details].ProductID=Products.ProductID
where Products.UnitPrice>100;
执行后的结果如下:
SQL Server 2005可以生成三种不同格式的显示显示计划:图形、文本和XML。在计划的内容方面,SQL SERVER可以生成只包含运算符的计划,包含估计成本的计划,以及包含运行时信息的计划,下图概括了用于获取包含不同格式不同内容的查询计划的命令。
|
内容 |
格式 |
|||
|
文本 |
XML |
图形 |
||
|
运算符 |
SET SHOWPLAN_TEXT ON |
N/A |
N/A |
|
|
运算符和估计成本 |
SET SHOWPLAN_ALL_ON |
SET SHOWPAN_XML_ON |
在Manager Studio中显示估计的执行计划 |
|
|
运行时信息 |
SET STATISTICS PROFILE ON |
SET STATISTICS XML ON |
在Manager Studio中包含实际的执行计划 |
|
首先看一个运算符示例,使用命令SHOWPLAN_TEXT,该查询联接Northwind数据库的两个表
use Northwind
go
SET SHOWPLAN_text ON
go
select productname,Products.ProductID
from dbo.[Order Details]
left outer join dbo.Products
on [Order Details].ProductID=Products.ProductID
where Products.UnitPrice>100
go
SET SHOWPLAN_text off
go
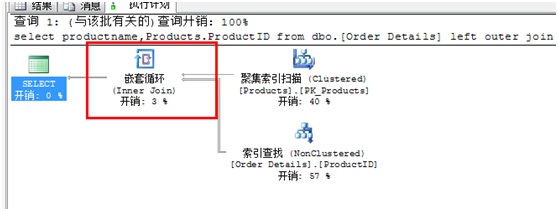
生成的查询计划如下图:

输出表明该查询计划由三个运算符组成:Nested Loops、Clustered Index Scan、Index Seek。Nested Loops对两个表执行内部联接。联接的外部表(执行内部联接时首先访问的表)是Products,SQL SERVER使用Clustered Index Scan访问物理数据。因为聚集索引包含了表中所有的数据,扫描聚集索引相当于扫描整个表。内部表是Order Details,它在ProductID列上有一个非聚集索引,使用到了Index Seek访问索引行。Index Seek运算符后面的Object引用 显示了索引的完整名称[Northwind].[dbo].[Orders Details].[ProductID]。在这个示例中索引名称和列名称相同,让人有点晕。所以不建议索引与列同名。
Object引用的后面是Seek 谓词。外部表的列值被用于对ProductID索引执行查找(Seek)
在查询之后还需使用SET SHOWPAN_TEXT OFF。否则无法显示查询结果。
XML格式的显示计划。一种是通过SET SHOWPLAN_XML ON得到的,包含估计的执行计划,另一种是由SET STATISTICS XML ON包含运行时信息
图形化的显示计划:SSMS有两个选项可以呈现图形化的显示计划:显示估计的执行计划和包括实际的执行计划,它们位于查询菜单和工具栏。

实际的执行计划比估计的执行计划呈现的信息更全

我们执行SET STATISTICS PROFILE ON显示实际的执行计划,Rows列包含每个运算符实际返回的行数。Excutes列处理一行或多行而初始化该运算符的次数。因为联接的外侧(product表的Clustered Index Scan)返回两行,我们必须执行联接的内侧操作(Index Seek)两次,因此输出中的Executed显示Index Seek是2。通过分析估计行数与实际行数之间的最大差异可以找出潜在问题,EstimateRows列是每次执行估计的输出行数,Rows是该运算符所有执行返回的累积行数,用EstimateRows乘以EstimateExcutions,再与Rows比较。差异大说明有潜在问题。


图形化的执行计划被广泛地应用于分析日常使用中,在SSMS中可以得到估计的执行计划和实际的执行计划。实际执行计划显示信息更多更全。为了演示图形化执行计划,使用下面语句:
select CustomerID,COUNT(*) from Orders
where OrderDate>'1998-01-01' and OrderDate<'1998-05-01'
group by CustomerID
生成执行如下:
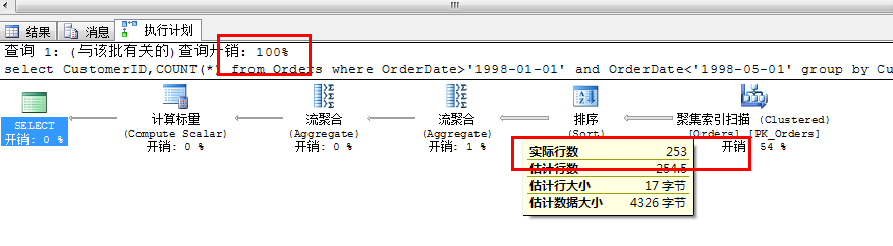
当把鼠标移到从运算符引出的箭头,可以得到估计的行数。使用箭头表示数据流的一个好处是它的粗细与源运算符返回的行数是成比例的。可以重点关注比较粗的箭头,它可能预示着性能问,数据流向是从右到左从上到下,生成的输出用于树中下一个运算符。每一个计划的顶部有一个百分比,表示该查询的估计成本占整个批处理总成本的百分比。如果占比过高则说明此处性能较慢需优化。
鼠标移到运算符上面,会显示包含运算符信息的黄色提示框,这个信息提示框提供了下列信息
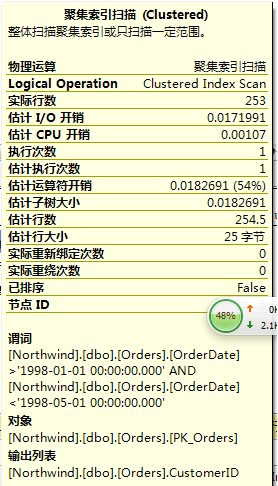
物理运算:将在引擎上发生的物理操作。
Logical Operation:基于微软查询处理概念模型的逻辑操作。例如联接运算符的物理运算属性表示联接算法(Nested Loops、Merge、Hash)、Logical Operation属性表示逻辑联接类型(Inner Join、Outer Join、Semi Join)等等。如果没有与该运算符联接的逻辑操作则这项值与物理运算属性相同。
实际行数:从该运算符实际返回的行数(只显示在实际的计划中)
估计IO开销和估计CPU开销:运算符在特定资源上的估计成本(I/O或CPU)。例如:Clustered Index Seek运算符主要与I/O有关,而Hash Math运算符主要与CPU有关。
估计运算符开销:执行该操作的成本
估计子树大小:到当前节点为止整个子树的累积成本
估计行数:该运算符预计返回的行数。在有些情况下能过观察实际行数和估计行数之间的差异,找出成本问题。
估计行大小:表中行的大小
实际绑定次数/实际重绕次数:这两个仅与作为Nested Loops联接内侧的运算符有关,在其它运算符中,Rebinds将显示1,Rewinds将显示为0。它们表示内部Init方法被调用的次数。实际绑定次数和实际重绕次数之和等于联接外侧所处理的行数。实际绑定意味着联接的一个或多个参数发生更改后,必须重新计划联接的内侧。实际重绕意味着任何相关参数都没有发生更改,可以重用之前的内侧结果集。(这一句没看懂,照搬书上一段话)
当分析查询性能时,有时需要清空缓存,SQL SERVER提供了用于从缓存中清除数据和执行计划的工具。
要从缓存中清空所有数据,使用下面的命令
DBCC DROPCLEANBUFFERS
要从缓存中清空执行计划,使用下面的命令
DBCC FREEPROCCACHE
注意不要在生产环境下使用这些命令,因为清空缓存将对整个系统的性能产生影响。清空数据缓存后,第一次访问数据时,SQL SERVER需要物理地从磁盘读取页。清空执行计划后,SQL SERVER需要为查询生成新的执行计划。即使在开发或测试环境下清空缓存也要清楚这样做的整体影响。
STATISTICS IO
STATISTICS IO 是一个会话选项,返回与运行的语句有关的IO信息。
SET STATISTICS IO ON
select OrderID,ProductID from [Order Details] where OrderID>2000
得到下面的输出(2155 行受影响)
表'Order Details'。扫描计数1,逻辑读取5 次,物理读取0 次,预读0 次,lob 逻辑读取0 次,lob 物理读取0 次,lob 预读0 次。
set statistics io off 关闭会话
STATISTICS TIME 是一个会话选项,它返回与运行语句相关的纯CPU时间和实耗时间信息,它返回分析和编译查询的时间以及执行查询的时间。示例如:
先清空缓存数据和执行计划
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
开始会话选项
SET STATISTICS TIME ON
select OrderID,ProductID from [Order Details] where OrderID>2000
SET STATISTICS TIME OFF
显示如下输出信息
SQL Server 分析和编译时间:
CPU 时间= 0 毫秒,占用时间= 0 毫秒。
(2155 行受影响)
SQL Server 执行时间:
CPU 时间= 0 毫秒,占用时间= 3 毫秒。