最近出于某种不可描述的原因,需要爬一段数据,大概长这样:
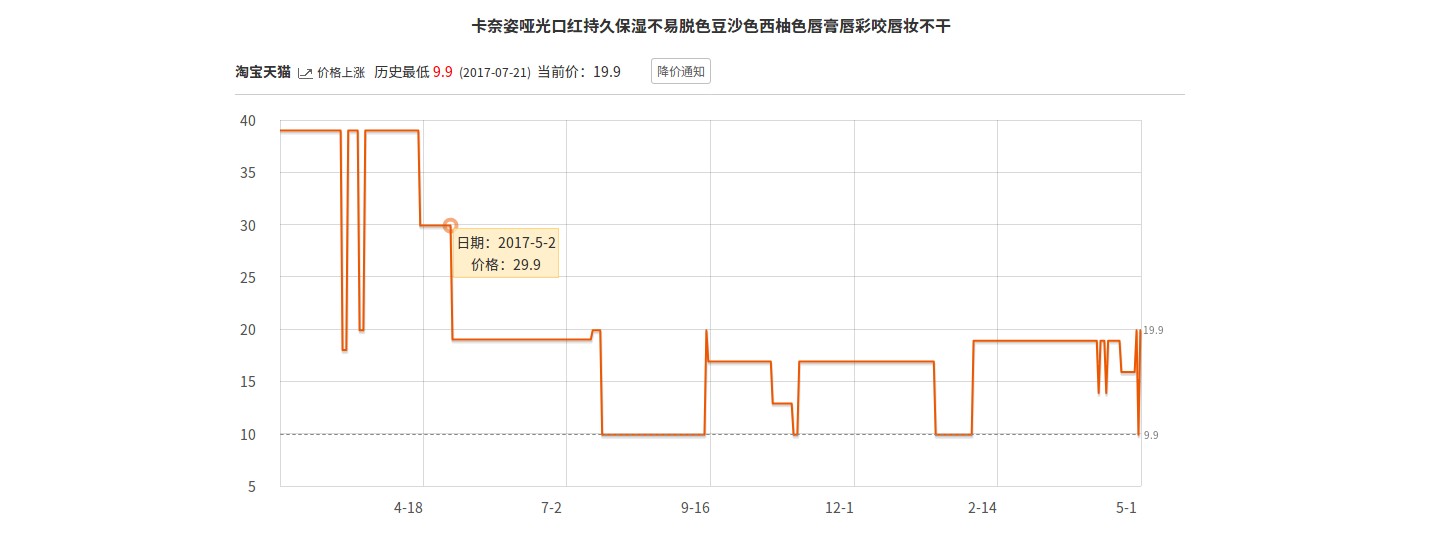
是一个价格走势图,鼠标移到上面会显示某个时刻的价格,需要爬下来日期和价格。
第一步肯定先看源代码,找到了这样一段:

历史记录应该是从这个iframe发过来的,点进去看看,找到这样一段:

可以大概看出来是通过get一个json文件来获取数据,我们要的东西应该就在这个json里面。打开浏览器的开发者工具(F12),一个个看发过来的json,发现这样一个:

打开看看:
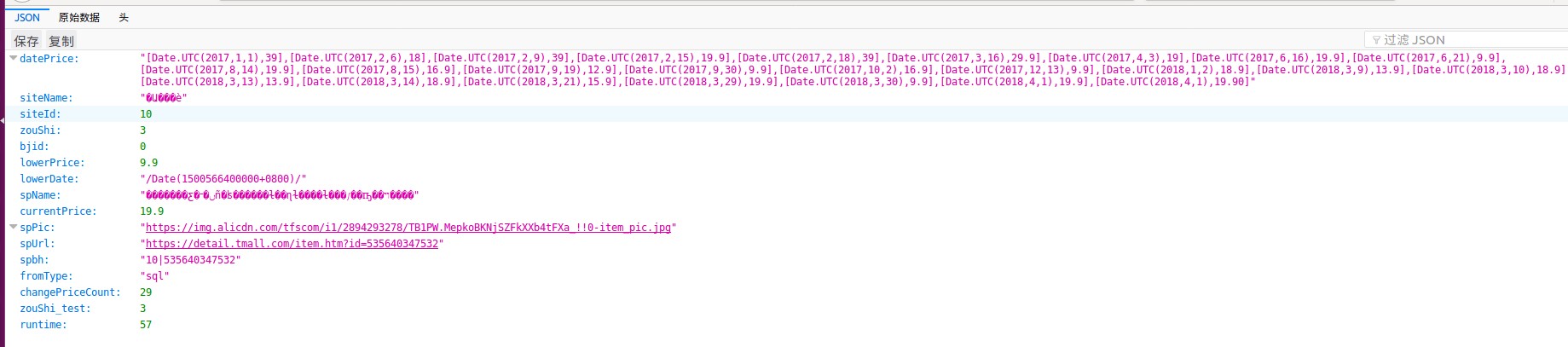
ok,我们找到了想要的东西了,接下来分析下这个url,发现一些规律,可以直接从第一页的url构造出来这个的url,除了一个token...从源代码里找到这玩意长这样...
菜鸡如我当然不知所措了...只能模拟浏览器抓包了...加载完从这个frame的src里可以找到这个token,问题解决,开爬!
以上部分的代码如下:
#coding=utf8 import urllib.request import json import requests import re from selenium import webdriver import time from bs4 import BeautifulSoup import requests import random import pytz import cv2 from matplotlib import pyplot as plt from PIL import Image, ImageEnhance import pytesseract from selenium.webdriver.common.keys import Keys import sys import numpy as np import gc def get_data_one_page(source, options, page): key1 = 'a href="http://tool.manmanbuy.com/historyLowest.aspx?.+" target' key2 = 'a href="http://www.manmanbuy.com/disSitePro.+" v' r = requests.get(source, headers=headers) pattern1 = re.compile(key1) pattern2 = re.compile(key2) html = r.text # 通过正则化匹配找到需要的url # 这里有多种情况,从源代码中发现 url = [] list1 = re.findall(pattern1, html) list2 = re.findall(pattern2, html) for i in list1: i = i.replace('a href="', '') i = i.replace('" target', '') url.append(i) for i in list2: i = i.replace('a href="', '') i = i.replace('" v', '') url.append(requests.get(i).url) cnt = 0 pattern_token = re.compile('token=.+') driver = webdriver.Firefox(firefox_options=options) # 设置超时 driver.set_page_load_timeout(8) i = -1 try_time = 3 while(i < len(url) - 1): i += 1 this_url = url[i] try: driver.get(this_url) except: if try_time: i -= 1 try_time -= 1 continue # get token # 找到需要的frame,获取url,从里面提取token ret = driver.find_element_by_id('iframeId').get_attribute('src') token = re.findall(pattern_token, ret) json_url = this_url.replace('http://tool.manmanbuy.com/historyLowest.aspx?', '') json_url = json_url.replace('item.tmall', 'detail.tmall') json_url = 'http://tool.manmanbuy.com/history.aspx?DA=1&action=gethistory&' + json_url + '&bjid=&spbh=&cxid=&zkid=&w=951&' + token[0] # 获取json文件,解析并写入文件 try: data = requests.get(json_url, proxies=proxy, headers=headers) data = json.loads(data.text) except: if try_time: i -= 1 try_time -= 1 continue if not ('spUrl' in data) or data['spUrl'] == 'https://detail.tmall.com/item.htm?id=544471454551': json_url = json_url.replace('detail.tmall', 'item.tmall') try: data = requests.get(json_url, proxies=proxy, headers=headers) data = json.loads(data.text) except: if try_time: i -= 1 try_time -= 1 continue if 'spName' in data: print(data['spName']) if not ('spUrl' in data) or data['spUrl'] == 'https://detail.tmall.com/item.htm?id=544471454551': if try_time: i -= 1 try_time -= 1 else: file = open('data/error_data_' + str(page) + '_' + str(cnt), 'w') file.write(json_url+' ') file.write(data['datePrice']+' ') file.close() continue else: file = open('data/data_' + str(page) + '_' + str(cnt), 'w') if 'spName' in data: file.write(data['spName']+' ') file.write(data['datePrice']+' ') file.close() cnt += 1 try_time = 3 # 关闭浏览器后记得手动释放内存 driver.quit() del driver gc.collect() def get_data(): print('firefox start') options = webdriver.FirefoxOptions() options.set_headless() source = 'http://s.manmanbuy.com/Default.aspx?key=%BF%DA%BA%EC&btnSearch=%CB%D1%CB%F7' driver = webdriver.Firefox(firefox_options=options) driver.get(source) print('pass') get_data_one_page(source, options, current_page) while(current_page <= 1200): current_page += 1 while (1): try: driver.get(source) except: time.sleep(2) continue break pagenum = driver.find_element_by_id('pagenum') pagenum.send_keys(current_page + 1) button = driver.find_element_by_xpath('/html/body/div[1]/div[5]/div[3]/div[5]/input[2]') button.click() get_data_one_page(source, options, current_page) driver.close() # if __name__ == '__main__': old = sys.stdout sys.stdout = open('log', 'r+') get_data()
然后就被封ip,出验证码 - -
封ip好说,搞个动态ip,爬几条换一个,至于ip怎么获取,花钱买几个会比较稳定,也有免费提供的,大多数不可用。
还有一个问题,上面没有改过header,也可能是被封的原因。
首先设置header
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Accept-Encoding': 'gzip, deflate',
'Accept- Language': 'en - US, en;q = 0.5'
}
具体内容可以通过正常访问去看看应该填什么。
然后在浏览器启动前加上:
agent = random.choice(user_agent) headers['User-Agent'] = random.choice(agent) # ip = ['183.159.82.25', '18118'] ip = random_ip() options.add_argument('user-agent="' + agent + '"') options.add_argument('--proxy-server=http://' + ip[0] + ':' + ip[1])
random_ip就是在可用的ip里随机取一个。
还有在requests.get前面加
proxy = {'https': 'https://' + ip[0] + ':' + ip[1]}
requests.get改为
data = requests.get(json_url, proxies=proxy, headers=headers)
就可以更改ip和header,骗过网站啦。当然对一些比较厉害的网站还是不行。。
接下来就是另一个问题了:每爬大概十条后会出现验证码,换ip后还在
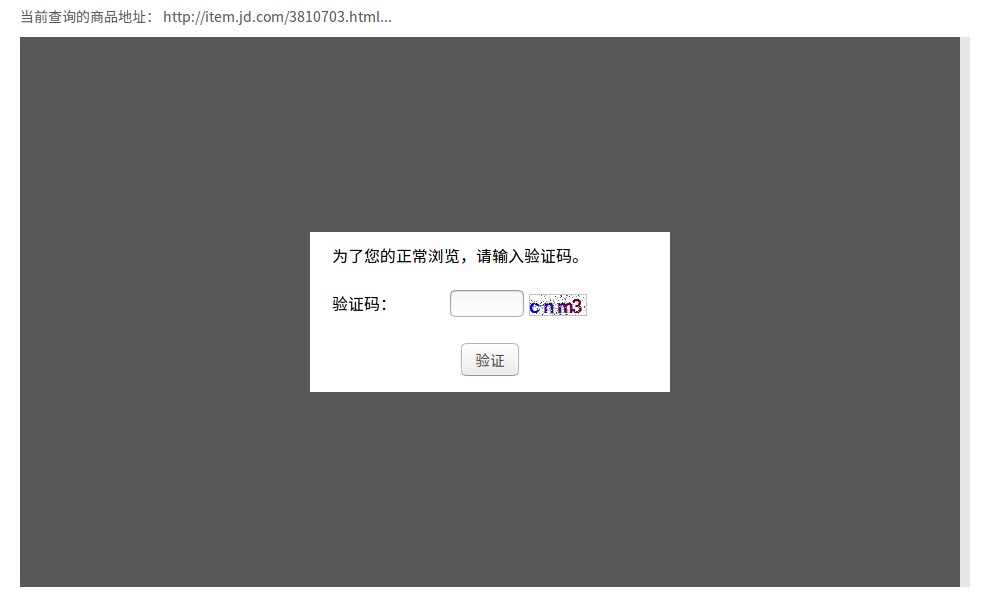
把它抓下来然后识别出来,send_key给那个框框就行了,至于怎么识别出来呢,显然这个网站的验证码非常naive,就是加了点椒盐噪点,中值滤波即可,当然图像增强和二值化是要的,然后丢给pytesseract识别就行了。
注意图像有边框,先去掉,当然加个分割效果应该会更好,但是我懒得写了...
由于识别准确率有限,认错了就再来一次,直到过了为止,代码如下:
def recognize_Captcha(driver): try: driver.switch_to.frame(driver.find_element_by_id('iframeId')) driver.switch_to.frame(driver.find_element_by_id('iframemain')) time.sleep(1) input_yanzheng = driver.find_element_by_id('txtyz') print('find Captcha') while (1): img_src = driver.find_element_by_id('ImageButton3').screenshot_as_png # img_gray = img_src.convert('L') # img_sharp = ImageEnhance.Contrast(img_gray).enhance(2.0) img_sharp = img_src # save Captcha file_img = open('yanzhengma.png', 'bw+') file_img.write(img_src) file_img.close() img = cv2.imread('yanzhengma.png') # get rid of frame img = img[1:20, 1:56] # get rid of noise img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img_gray = cv2.medianBlur(img_gray, 3) ret, img_binary = cv2.threshold(img_gray, 150, 255, cv2.THRESH_BINARY) cv2.imwrite('img_code.bmp', img_binary) # recognize code = pytesseract.image_to_string(Image.open('img_code.bmp'), lang='eng') code = code.replace(' ', '') print(code) input_yanzheng.send_keys(code) time.sleep(2) driver.find_element_by_name('yanzheng').send_keys(Keys.ENTER) time.sleep(2) try: input_yanzheng = driver.find_element_by_id('txtyz') except: driver.switch_to.default_content() break except: driver.switch_to.default_content()
至此,全部完成,可以开始爬了,boss说要2w条,慢慢爬呗...
坑爹的事情来了!!这个网站,从第十页往后,全部是一样的!!!也就是根本没有那么多记录!!
- - 白写了...
完整代码在我的github上面:https://github.com/KID-7391/crawler_Captcha ,里面的ip应该已经过期了。