1 概述
Hadoop在大数据技术体系中极为重要,被誉为是改变世界的7个Java项目之一(剩下6个是Junit、Eclipse、Spring、Solr、HudsonAndJenkins、Android),本篇文章以Hadoop 3.3.0官方文档为基础,首先会介绍Hadoop相关术语,包括HDFS,MapReduce等,接着会完整描述Hadoop的搭建过程,包括本地以及分布式集群的搭建。
2 术语介绍
Hadoop:Hadoop是Apache开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储HDFS:全称Hadoop Distributed File System,Hadoop分布式文件系统,被设计成适合运行在通用硬件上的分布式文件系统,具有高度容错性的特点,能提供高吞吐量的数据访问MapReduce:一个编程模型,用于大规模数据集的并行运算,是面向大数据并行处理的计算模型、架构以及平台。平台指的是允许使用普通商用服务器构成一个包含数十甚至数千个节点的分布和并行计算集群。架构指的是MapReduce提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务。模型指的是借助于函数式编程语言的设计思想,提供了一种简便的并行程序设计方法YARN:YARN是Hadoop的一种资源管理器,一个通用的资源管理系统,可以为上层应用提供统一的资源管理以及调度,基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离
3 环境
- 操作环境:
Manjaro 20.0.3 - 虚拟机环境:
VirtualBox 6.1.10+CentOS-8.2.2004-x86_64-minimal× 3 Hadoop 3.3.0(aarch64+x86_64)OpenJDK 11(aarch64+x86_64)- 服务器:
CentOS 8× 3(aarch64× 1 +x86_64× 2)
4 Hadoop部署模式
首先来看一下Hadoop支持的部署模式,Hadoop集群搭建支持以下三种模式:

- 本地模式:默认模式,运行在单一Java进程中
- 伪分布模式:运行在一个节点中但是在不同的Java进程中
- 完全分布模式:运行在不同机器上的标准集群模式,利用多台主机部署
Hadoop
5 安装前准备
5.1 Hadoop
官网下载戳这里,本文采用目前最新的3.3.0版本,注意如果服务器的架构为aarch64需要下载对应版本。
5.2 JDK
关于JDK的选择,参考文末的链接:
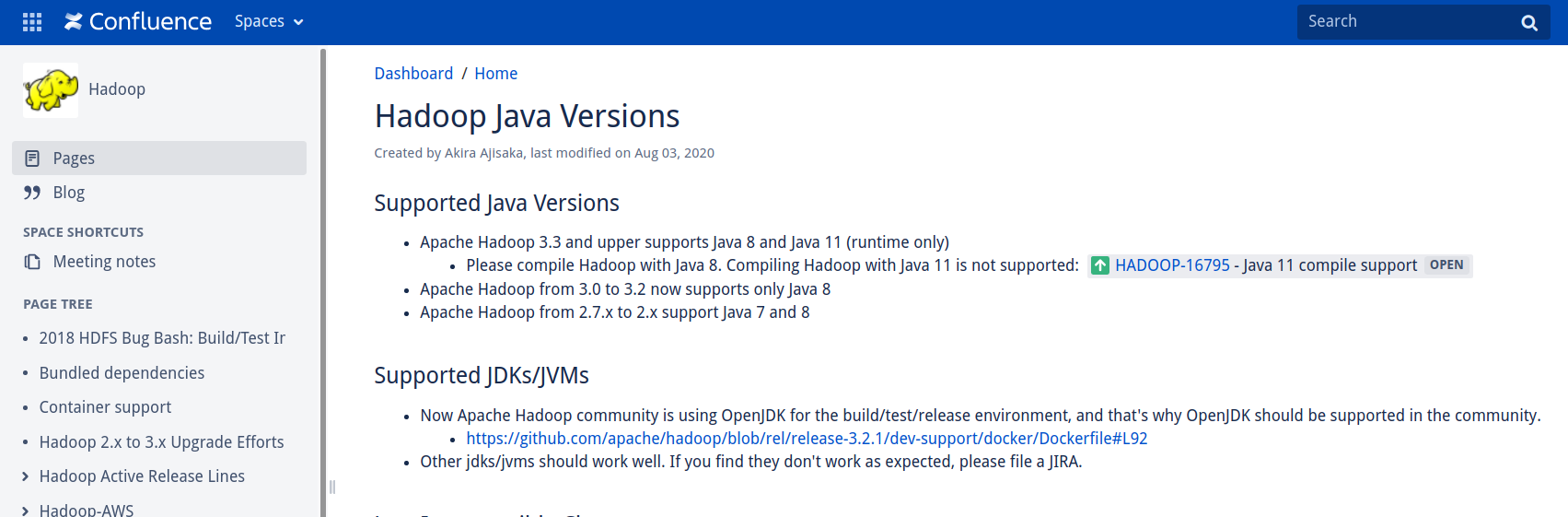
3.3版本在运行时支持Java11,3.2(包括3.2)以下只支持Java8,另外也提到了现在Hadoop使用OpenJDK作为构建/测试以及发布的JDK,因此这里使用OpenJDK11,戳这里下载,如果服务器架构为aarch64可以使用yum install安装。
5.3 虚拟机
虚拟机用的是Virtual Box,6.1.10版本。
使用虚拟机是为了模拟搭建集群,就算有真实服务器也建议先在虚拟机上跑一遍大概流程。
5.4 服务器
部署Hadoop的真实服务器,这里使用了三台服务器进行搭建集群。
6 动手吧!
准备工作做好后就开始动手吧!
由于篇幅略长所以分成了四篇文章方便查看:
7 结语
本文讲述了搭建Hadoop集群的三种方式,如无意外就可以搭建一个基本的Hadoop集群了。
但是,一般来说,并不能直接投入生产环境中使用,因为需要配合ZooKeeper搭建HA(高可用)集群,本文限于篇幅就不再叙述了。本文的初衷是教会读者如何搭建,至于ZooKeeper,网上有不少文章可以参考。最后希望读者看完之后能够对Hadoop有一个大概的认识,了解Hadoop的组成部分以及基本工作原理。
8 参考
如果觉得文章好看,欢迎点赞。
同时欢迎关注微信公众号:氷泠之路。
