需准备的前提条件:
1. 安装JDK(自行安装)
2. 关闭防火墙(centos):
systemctl stop firewalld.service
systemctl disable firewalld.service
编辑 vim /etc/selinux/config文件,修改为:
SELINUX=disabled
源码包下载:
http://archive.apache.org/dist/hadoop/common/
集群环境:
master 192.168.1.99 slave1 192.168.1.100 slave2 192.168.1.101
下载安装包:
# Mater
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz -C /usr/local/src tar -zxvf hadoop-2.7.5.tar.gz mv hadoop-2.7.5 /usr/local/hadoop
配置主机
1、编辑/etc/hostname文件
分别配置主机名为master slave1 slave2
2、编辑/etc/hosts,添加对应的域名和ip
cat /etc/hosts 192.168.1.99 master 192.168.1.100 slave1 192.168.1.101 slave2
3. 配置ssh(自行操作,我这边配置的用户是hadoop)
修改配置文件:
cd /usr/local/hadoop/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_91
vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_91
vim slaves
slave1
slave2
vim core-site.xml
<configuration>
<property>
<!--指定namenode的地址-->
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.99:9000</value>
</property>
<property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<!--读写缓存size设定,默认为64M-->
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<!--指定hdfs中namenode的存储位置-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<!--指定hdfs中datanode的存储位置-->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<!--指定hdfs保存数据的副本数量-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--为secondary指定访问ip:port-->
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.99:9001</value>
</property>
<property>
<!--设置为True就可以直接用namenode的ip:port进行访问,不需要指定端口-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.99:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.99:19888</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<!--nomenodeManager获取数据的方式是shuffle-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--客户端对ResourceManager主机通过 host:port 提交作业-->
<name>yarn.resourcemanager.address</name>
<value>192.168.1.99:8032</value>
</property>
<property>
<!--ApplicationMasters 通过ResourceManager主机访问host:port跟踪调度程序获资源-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.99:8030</value>
</property>
<property>
<!--NodeManagers通过ResourceManager主机访问host:port-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.99:8035</value>
</property>
<property>
<!--管理命令通过ResourceManager主机访问host:port-->
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.99:8033</value>
</property>
<property>
<!--ResourceManager web页面host:port.-->
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.99:8088</value>
</property>
<!--我们可以指定yarn的master为哪台机器,与namenode分布在不同的机器上面 -->
<!-- <property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.100</value>
</property>
-->
</configuration>
说明:启动Hadoop2.0之后,默认scheduler为capacity scheduler,如果想修改为fair scheduler,则在yarn-site.xml中加入:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
#创建临时目录和文件目录
mkdir /usr/local/hadoop/tmp mkdir -p /usr/local/hadoop/dfs/name mkdir -p /usr/local/hadoop/dfs/data
配置环境变量:
#Master slave1 slave2
vim ~/.bashrc HADOOP_HOME=/usr/local/hadoop PATH=$PATH:$HADOOP_HOME/bin
#刷新环境变量
source ~/.bashrc
修改启动脚本保存pid的路径
目的:因为存放pid的路径为/tmp,/tmp是临时目录,系统会定时清理该目录中的文件,所以我们需要修改存放pid的路径
mkdir /usr/local/hadoop/pid
cd /usr/local/hadoop/sbin
sed -i 's/tmp/usr/local/hadoop/pid/g' hadoop-daemon.sh
sed -i 's/tmp/usr/local/hadoop/pid/g' yarn-daemon.sh
拷贝安装包:
# 我用的hadoop用户,需先在从主机上面创建/usr/local/hadoop目录,设置权限chown -R hadoop:hadoop /usr/local/hadoop rsync -av /usr/local/hadoop/ slave1:/usr/local/hadoop/ rsync -av /usr/local/hadoop/ slave2:/usr/local/hadoop/
启动集群(主机时间需同步):
#初始化Namenode
hadoop namenode -format
#启动集群
./sbin/start-all.sh
集群状态:
#Master

#Slave1
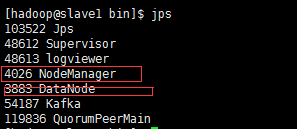
#Slave2

监控网页:
http://master:8088

关闭集群:
./sbin/hadoop stop-all.sh