数据库是mongdb
数据是58同城上发的转手记录
一 为了保证数据安全,对需要进行处理的数据进行拷贝。
> db.createCollection('test') { "ok" : 1 } > show collections base_url detail_info detail_url test > db.detail_info.copyTo('test') WARNING: db.eval is deprecated 1650
二 对数据库中的数据进行处理
不要想着将数据拿出来,处理完后,在一一对应放到数据库中!
原本数据库中的地址存储的格式是:北京-昌平,北京-通州,需要拿到具体的某个区。
在jupyter notebook中进行操作。
这用到了update方法和$set 操作符。update方法的调用者是 col ,表。
for i in col.find(): zone_l = (i['zone'].split('-')) if len(zone_l)>1: new_zone = zone_l[1] else: new_zone = '不明' col.update({'_id':i['_id']},{'$set':{'zone':new_zone}})
三 从数据库中读到 地址,对地址进行整理。
这里用到了set集合,和列表的count方法,内置函数zip()。很关键
zones = [] for i in col.find(): zone.append(i['zone'])
single_zone = list(set(zones))
num = [zones.count(i) for i in single_zone ]
构建charts要求格式的数据。
def foo(): l = [] for zone,n in zip(single_zone,num): Data={ 'name':zone, 'data':[n], 'type':'column', } l.append(Data) return l
PS.
这里实际上可以用生成器,节省内存。
def foo(): for zone,n in zip(single_zone,num): Data={ 'name':zone, 'data':[n], 'type':'column', } yield Data l = [ i for i in foo() ]
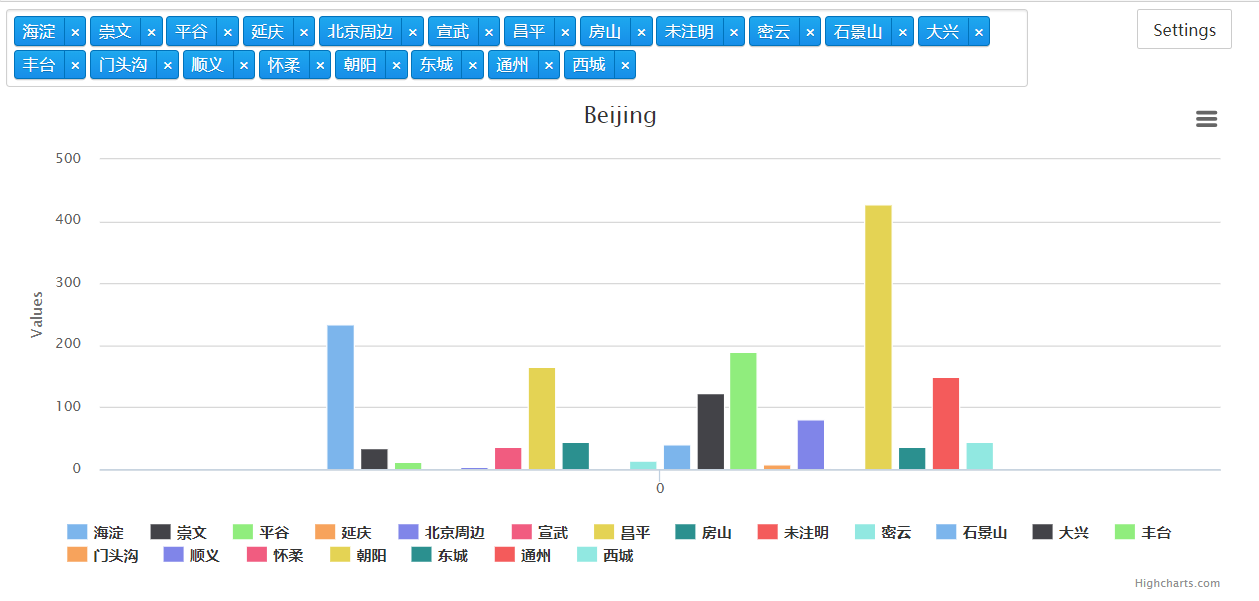
四 调用charts.plot方法。
依照固定格式传参
l = foo() charts.plot(l,show='inline',options=dict(title=dict(text='Beijing')))
最终现实结果:
示例二: 使用aggregate(),管道函数比find()快很多。
import charts import pymongo client = pymongo.MongoClient('localhost',27017) db = client['ganji'] col = db['test'] for i in col.find().limit(10): print(i)
输出:
{'_id': ObjectId('5698f524a98063dbe9e91ca8'), 'pub_date': '2016-01-12', 'look': '-', 'area': '朝阳', 'title': '【图】95成新小冰柜转让 - 朝阳高碑店二手家电 - 北京58同城', 'url': 'http://bj.58.com/jiadian/24541664530488x.shtml', 'cates': ['北京58同城', '北京二手市场', '北京二手家电', '北京二手冰柜'], 'price': '450 元'}
{'_id': ObjectId('5698f525a98063dbe4e91ca8'), 'pub_date': '2016-01-14', 'look': '-', 'area': '朝阳', 'title': '【图】洗衣机,小冰箱,小冰柜,冷饮机 - 朝阳定福庄二手家电 - 北京58同城', 'url': 'http://bj.58.com/jiadian/24349380911041x.shtml', 'cates': ['北京58同城', '北京二手市场', '北京二手家电', '北京二手洗衣机'], 'price': '1500 元'}
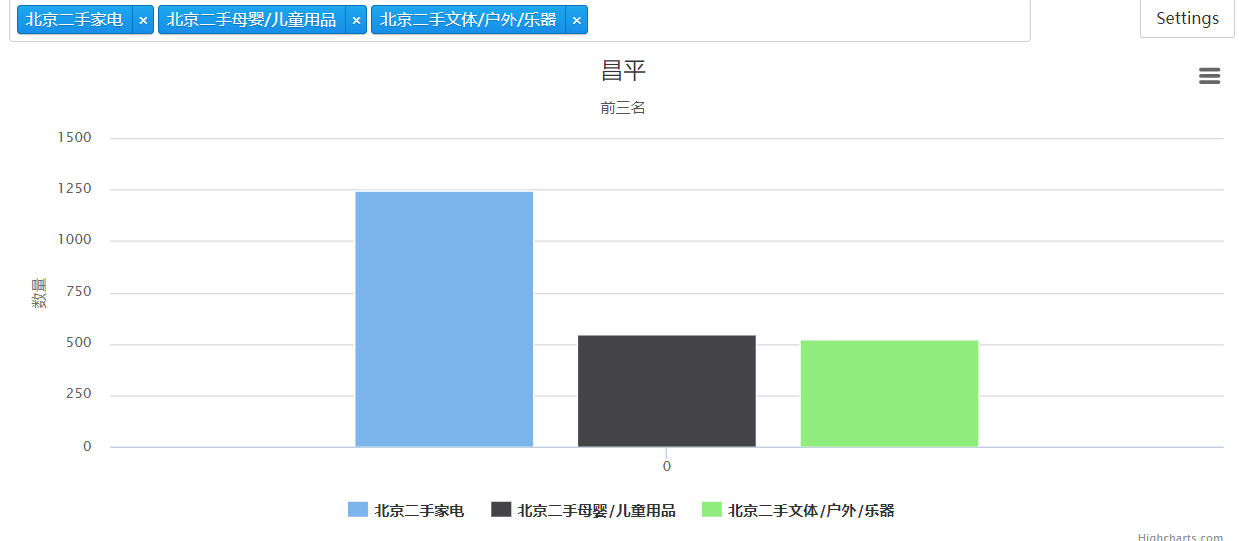
aggregate()
pipeline = [ {'$match':{'area':'昌平'}}, {'$group':{'_id':{'$slice':['$cates',2,1]},'count':{'$sum':1}}}, {'$sort':{'count':-1}}, {'$limit':3}, ]
def get_one_area(area): pipeline = [ {'$match':{'area':area}}, {'$group':{'_id':{'$slice':['$cates',2,1]},'count':{'$sum':1}}}, {'$sort':{'count':-1}}, {'$limit':3}, ] for i in col.aggregate(pipeline): Data = { 'name':i['_id'], 'data':[i['count']], 'type':'column' } yield Data
l = [i for i in get_one_area('昌平')] import charts options = { 'title':{ 'text':'昌平' }, 'subtitle':{ 'text':'前三名' }, 'yAxis':{ 'title':{ 'text':'数量' } } } charts.plot(l,show='inline',options=options)
输出: