MySQL 8.0窗口函数 https://www.cnblogs.com/DataArt/p/9961676.html
窗口函数和聚合函数区别: 对于每个组返回多行,而聚合函数对于每个组只返回一行 专用窗口函数--排序: RANK(): 相同排序跳序号位 DENSE_RANK() 相同排序不跳序号位(允许并排次序) ROW_NUMBER() 不存在重复的序号位 窗口函数只能使用于selete / update中的set / order by 子句
窗口聚合函数与分组聚合函数的功能是相同的;唯一不同的是,分组聚合函数通过分组查询来进行,而窗口聚合函数通过OVER子句定义的窗口来进行。
什么叫窗口?
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有的函数随着
记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数和普通聚合函数也很容易混淆,二者区别如下:
聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
聚合函数也可以用于窗口函数中,这个后面会举例说明。


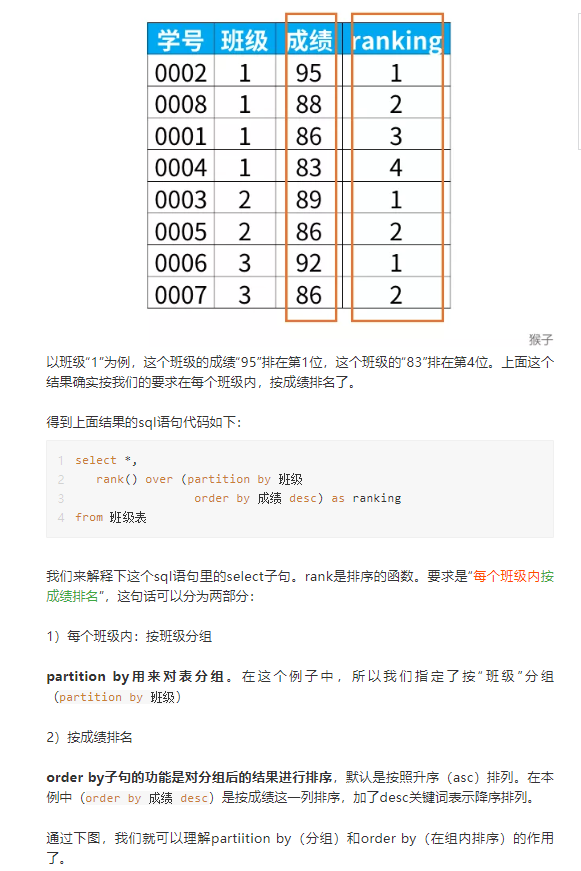


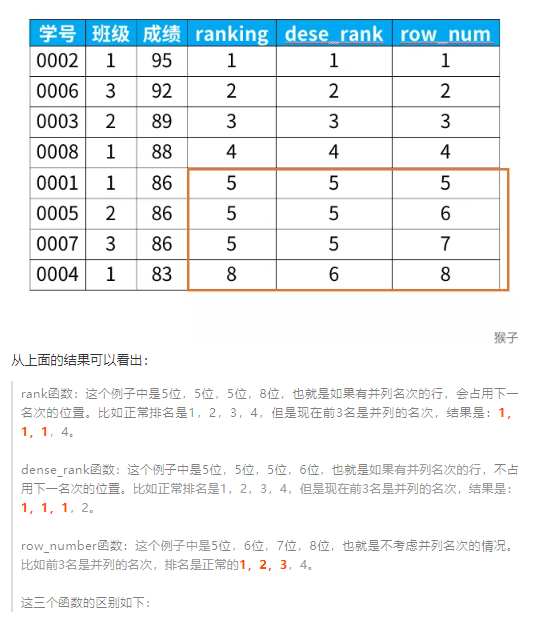


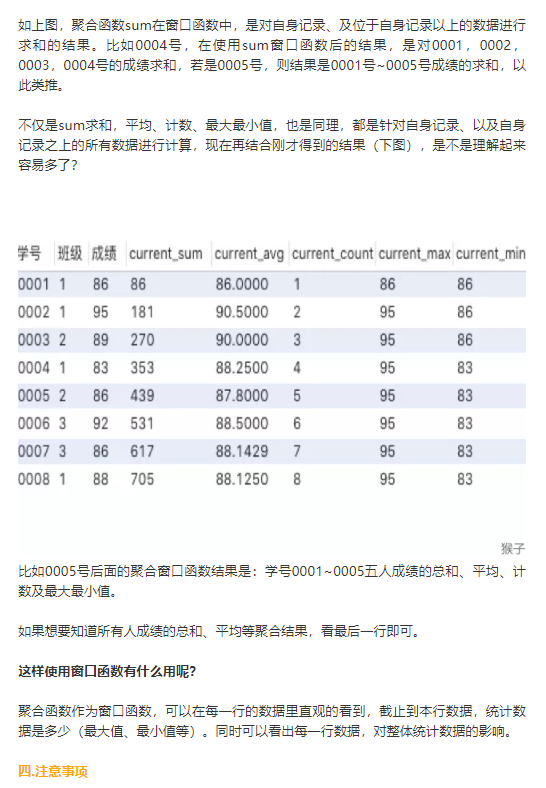
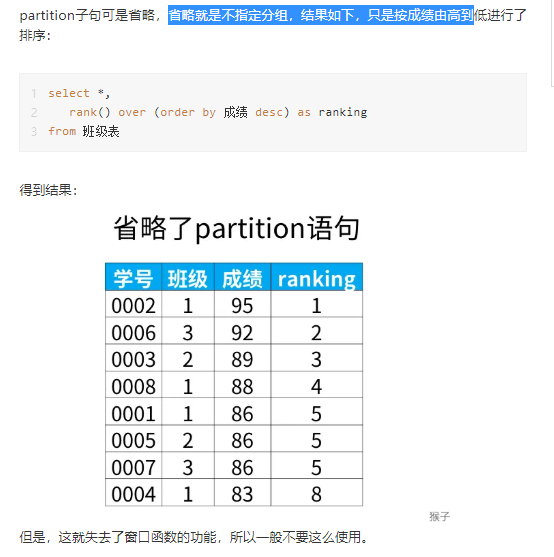

SELECT user_name,rank() OVER (order by amount desc) AS r FROM trade_2017; 窗口函数分为 累计计算窗口函数,分区排序窗口函数,分组排序窗口函数,偏移分析窗口函数。 累计计算窗口函数 sum 是接收参数的呀,sum 默认是降序,over()需指定升序 累计计算窗口函数 AVG/SUM/MAX/MIN rows between unbounded preceding and current rows ---包含本行和之前所有的行 rows between current row and unbounded following ---包含本行和之后所有的行 rows between 3 preceding and current row ---包含本行在内和前三行 rows between 3 preceding and 1 following ---从前三行到下一行,一共5行。 典型场景:sum() 每个月的支付总额和当年累积支付总额 avg() 移动平均 注:接收参数,参数为表中有具体值的字段。 见例2。 分区排序窗口函数 row_number() over() rank() over() dense_rank() over() 典型场景:排名,TOP3,第10名,第20名 注:不需要传参 和sum好像有点不一样,见例4。 分组排序窗口函数 ntile(n) over(PARTITION BY,ORDER BY) 典型应用场景:前10% 前25%
注:一般不需要 PARTITION BY,用 ORDER BY,就可实现按字段分组。 偏移分析窗口函数 lag() over() lead() over() 典型场景:支付时间超过100天
查询上一个订单和当前订单时间间隔 2017-2018年每月的支付总额和当年累积支付总额 1 SELECT a.year,a.month,a.sp,sum(a.sp) over(PARTITION BY a.year ORDER BY a.month) as sump FROM (SELECT 2017 as year,month(dt) month,sum(pay_amount) sp FROM user_trade WHERE year(dt)=2017 GROUP BY month(dt) UNION ALL SELECT 2018 as year, month(dt) month,sum(pay_amount) sp FROM user_trade WHERE year(dt)=2018 GROUP BY month(dt) )a ; 1的优化版 1) 年月连起来区分的时候 GROUP BY year,month. 2) 活用 in () 成员运算符。 SELECT a.year, a.month, a.sp, sum(a.sp) over(PARTITION BY a.year ORDER BY a.month) as sump FROM (SELECT year(dt) year, month(dt) month, sum(pay_amount) sp FROM user_trade WHERE year(dt) in (2017,2018) GROUP BY year(dt),month(dt) )a; 2 2018年每个月的近三个月移动平均支付金额 SELECT month(dt) month,avg(pay_amount) OVER(rows between 3 preceding and current row) FROM user_trade WHERE year(dt)=2018 GROUP BY month(dt); 这样是错误的。需要理解窗口的概念,窗口的概念是记录集合。这里还没与记录呢,无法直接应用 窗口函数吧,目前的理解。 SELECT a.month,avg(a.sp) OVER(ORDER BY a.month rows between 3 preceding and current row) FROM (SELECT month(dt) month,sum(pay_amount) sp FROM user_trade WHERE year(dt)=2018 GROUP BY month(dt))a ; 3 2019年1月,用户购买商品品类数量的排名 SELECT a.goods_category,a.cp,rank() over(order by a.cp) FROM (SELECT goods_category,count(piece) cp FROM user_trade where year(dt)=2019 GROUP BY goods_category)a; 4 选出2019年支付金额排名在第10,第20,第30名的用户 SELECT b.user_name FROM (SELECT a.user_name,a.sp,rank() over (order by a.sp) as r FROM (SELECT user_name,sum(pay_amount) as sp FROM user_trade WHERE year(dt)=2019 AND month(dt)=1 GROUP BY user_name)a)b WHERE b.r in (10,20,30) ; 嵌套了两个子查询,不推荐 rank 可以嵌套sum? SELECT a.user_name FROM (SELECT user_name,sum(pay_amount) sp,rank() over(ORDER BY sum(pay_amount)) r --> ORDER BY 不能使用 sum(pay_amount)的别名 FROM user_trade WHERE year(dt)=2019 AND month(dt)=1 GROUP BY user_name)a WHERE a.r in (10,20,30) ; 5 将2019年1月的支付用户,按照支付金额分成5组 SELECT user_name,sum(pay_amount) sp,ntile(5) over(order by sum(pay_amount) desc) --> 我自己用的是 PARTITION BY,结果全是1 FROM user_trade WHERE year(dt)=2019 AND month(dt)=1 GROUP BY user_name ; 6 选出2019年退款金额排名前10%的用户 SELECT a.user_name,a.sr,a.nt FROM (SELECT user_name,sum(refund_amount) sr,ntile(10) OVER(ORDER BY sum(refund_amount) desc) nt FROM user_refund WHERE year(dt)=2019 GROUP BY user_name)a WHERE a.nt=1 ; 7 支付时间间隔超过100天的用户数 SELECT user_name,lag(pay_time,1,pay_time) over(PARTITION BY user_name,ORDER BY pay_time)--> 有 PARTITION BY FROM user_trade GROUP BY user_name ; 写不下去了 SELECT count(a.user_name) FROM (SELECT user_name,dt,lag(dt) over(PARTITION BY user_name,ORDER BY dt) as ld FROM user_trade WHERE dt>'0')a WHERE a.ld is not null AND datediff(a.dt,a.ld) > 100' ; 8 每个城市,不同性别,2018年支付金额最高的TOP3用户 SELECT c.city,c.sex,c.user_name FROM (SELECT a.city,a.sex,a.user_name,rank() OVER(PARTITION by a.city,a.sex ORDER BY b.ap DESC) as nr FROM (SELECT DISTINCT user_name,sex,city FROM user_info)a JOIN (SELECT user_name,sum(pay_amount) ap FROM user_trade WHERE year(dt)=2018 GROUP BY user_name)b ON a.user_name=b.user_name)c WHERE c.nr in (1,2,3) ; 9 每个手机品牌退款金额前25%的yoghurt SELECT c.user_name FROM (SELECT a.user_name,a.phone,b.sr,ntile(4) OVER(PARTITION BY a.phone ORDER BY b.sr DESC) as nt FROM (SELECT user_name,extra2['phonebrand'] phone FROM user_info)a JOIN (SELECT user_name,sum(refund_amount) sr FROM user_refund WHERE year(dt) in (2017,2018,2019) GROUP BY user_name)b)c WHERE c.nt=1 ;
退款时间间隔最长的用户 SELECT b.user_name, FROM (SELECT a.user_name,datediff(a.dt,a.dl) dd,row_number() over(ORDER BY datediff(a.dt,a.dl) DESC) rank FROM (SELECT user_name,dt,lag(dt,1,dt) over(PARTITION by user_name) dl FROM user_refund WHERE dt>'0')a)b WHERE b.rank=1 ;
lag感觉和分组关系密切,毕竟偏移分析,不能随便偏移,随便偏移有什么意义呢?要分门别类的偏移。
写sql语句的时候 注意先别group by。
常用技巧 GROUPING SETS 自由组合 https://blog.csdn.net/weixin_37536446/article/details/88552305 SELECT age,city,level,count(user_id) FROM user_info GROUP BY age,city,level GROUPING SETS(age,(city,level)) ; WITH ROLLUP https://blog.csdn.net/id19870510/article/details/6254358 最左边列自动求和 SELECT year(dt) y,month(dt) m,sum(pay_amount) sp FROM user_trade WHERE dt>'0' GROUP by year(dt),month(dt) WITH ROLLUP ; 表连接优化 小表在前,大表在后 使用相同的连接键 尽早的过滤数据
LATERAL VIEW
EXPLODE 行转列
CONCAT_WS 列转行
SELECT a.user_name,b.cd FROM user_goods_category a LATERAL VIEW explode(split(category_detail,','))b as cd ;