一、泛映射类型
1、标准库里的映射类型都是dict来实现的,它们有个共同的限制,只有可散列的数据才能作为映射里的键;
2、如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的。并且这个对象需要实现__hash__方法,
包含__qe__方法。原子不可变数据类型(str,bytes和数值类型)都是可散列的,frozenset也是可散列的。当一个元组所包含的所
有元素都是可散列的,它才是散列的。
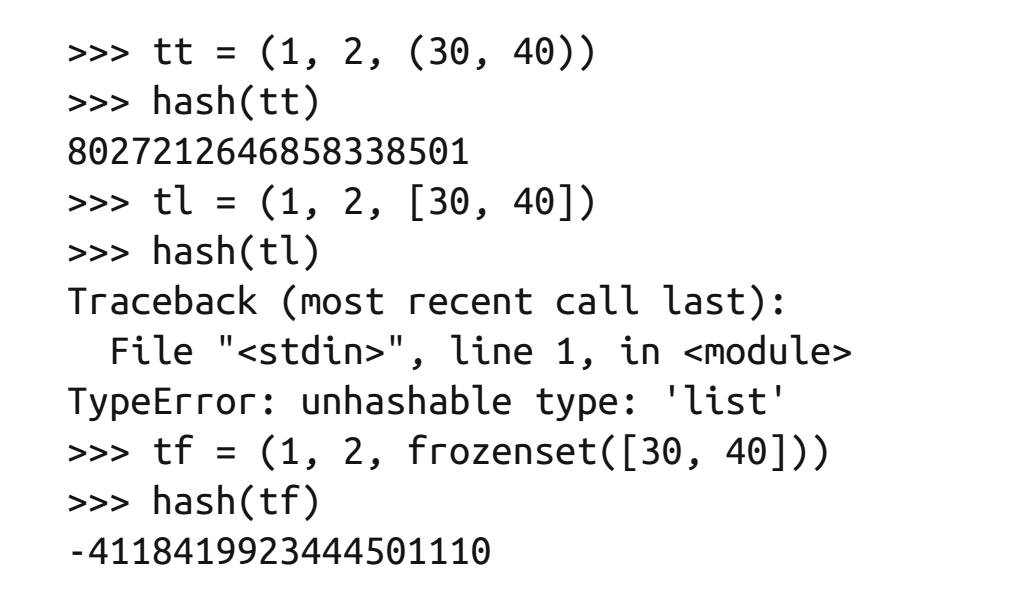
3、一般用户自定义的类型都是可散列的,散列值是其id值,
4、创建字典的方式

二、字典推导


三、常见的映射方法
1、用setdefault处理找不到的键
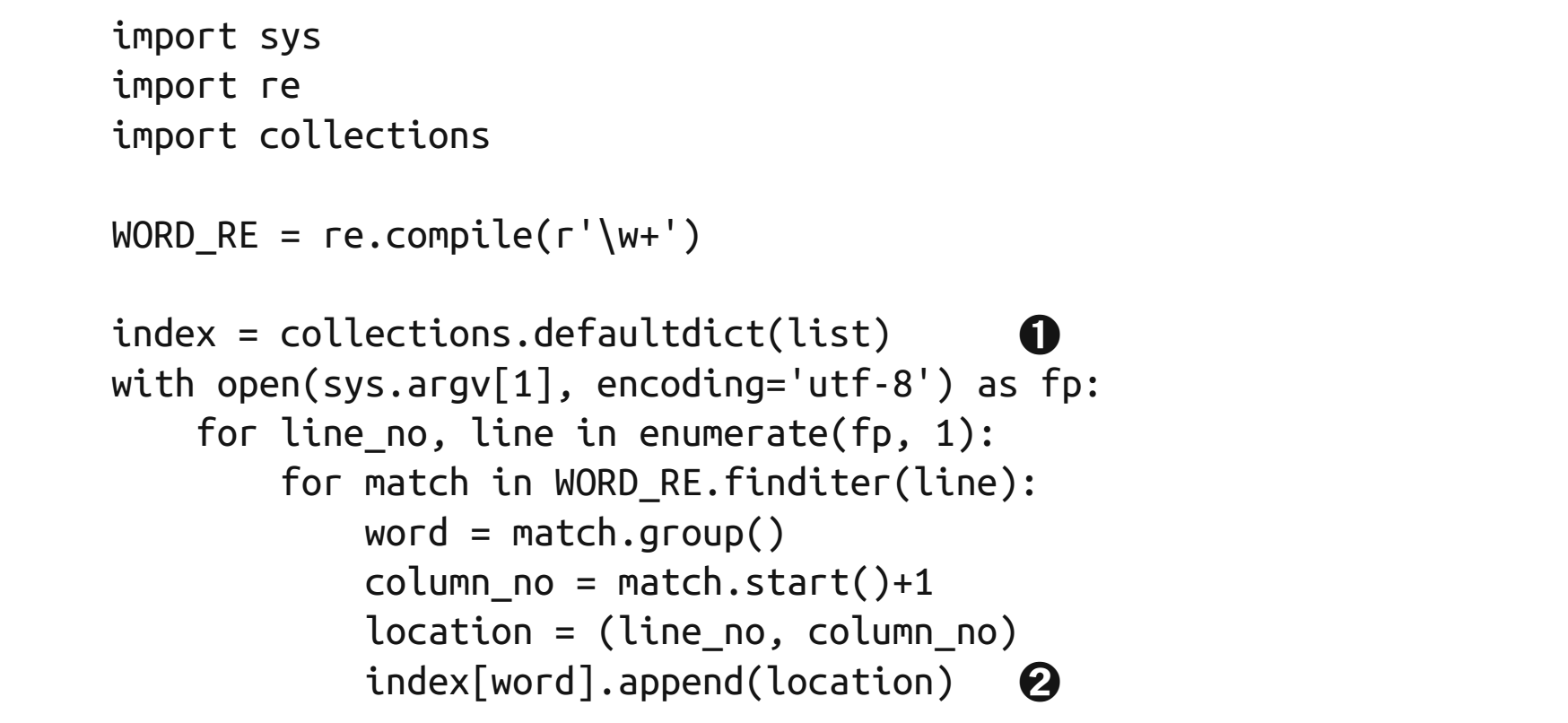
当d[k]查找不到正确的键时,会抛出异常,可以用d.get(key,default)来替代d[k]。如下为统计某元素出现的位置。

用setdefault简化代码,只需要查询一次,上面至少需要2次(不存在时需要3次)

三、映射的弹性键查询
1、 当找不到键时,另一个选择是defaultdict,返回某种默认值。如下返回空列表。
注:这种方法只会在__getitem__调用时发挥作用,即dd[k]时有效,使用dd.get(k)则会返回None。
2、特殊方法__missing__
在映射类型中,在__getitem__找不到键的时候,会自动调用__missing__方法。其中2中的isinstance是必需的,当键不存在时,防止递归调用;__contains__方法也是必需的,当调用k in d时会调用它,
但并没有用k in dict来判断键的存在,因为也会导致__contains__被递归调用,因此采用的是显式的调用self.keys();在python3中,dict.keys()返回的是视图,查找元素速度快。在python2中返回的是列表,当
对象体积较大时,效率不高,因为需要扫描整个列表。


四、字典的变种
除了defaultdict的其他映射
OrderDict:添加键的时候会保持顺序。
ChainMap: 容纳数个不同的映射对象。
Counter: 计数

五、子类化UserDict
自定义映射时,以UserDict为基类,比以dict为基类更方便。UserDictr 的data属性,是dict的实例。

六、不可变映射类型
types模块中引入一个MappingProxyType模块


七、集合论
1、 set或frozenset。set类型本身是不可散列的,但是frozenset可以,因此可以创建一个包含不同frozenset的set。
使用set的某些操作可以提高速度

2、集合的创建
(1)集合字面量{1},{1,2}。空集合set()({}为空字典)。
(2){1,2,3}字面量句法相比于set([1,2,3])更快。
(3)集合推导跟列表推导类似,不过将方括号换成了{}
七、dict和set背后
1、查找时,dict和set的速度要快于列表;
2、字典中的散列表。散列表是稀疏数组(总有空白元素),导致字典会占用较大空间。当存放数量巨大的记录时,放在元组或具名元组构成的列表中会是较好的选择。
3、键查询很快
4、键的次序取决于添加顺序
5、往字典里添加新键,可能会改变已有键的顺序:当添加新键时,可能会为字典扩容,需要新建一个更大的散列表,这个过程可能会出现冲突。
6、由5知,不要同时对字典时行扫描和修改,最好分成两步:扫描字典,放到一个新字典里;修改原字典。
7、上述特点对集合同样适用。