一、操作数据库读书笔记
SQLite是一种嵌入式数据库,它的数据库就是一个文件。由于SQLite本身是C写的,而且体积很小,所以,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成。Python就内置了SQLite3,所以,在Python中使用SQLite,不需要安装任何东西,直接使用。
1、在使用SQLite前,我们先要搞清楚几个概念:
(1)表是数据库中存放关系数据的集合,一个数据库里面通常都包含多个表,表和表之间通过外键关联。
(2)要操作关系数据库,首先需要连接到数据库,一个数据库连接称为Connection;
(3)连接到数据库后,需要打开游标,称之为Cursor,游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联。因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。游标对象有以下的操作:
execute() – 执行sql语句
executemany() – 执行多条sql语句
close() – 关闭游标
fetchone() – 从结果中取一条记录,并将游标指向下一条记录
fetchmany() – 从结果中取多条记录
scroll() – 游标滚动
根据上周作业,制作了2015年大学排名的csv文件,下面的操作都将基于该csv文件进行。
• 将csv文件写入数据库
代码如下:
1 # -*- coding: utf-8 -*-
2 """
3 Created on Fri May 31 12:33:56 2019
4
5 @author: Regan_White_Lin 12
6 """
7
8 import pandas
9 import sqlite3
10 conn= sqlite3.connect("2015大学排名(12).db")
11 k = pandas.read_csv('2015中国大学排名爬虫.csv',encoding='gbk')
12 k.to_sql('University', conn, if_exists='append', index=False)
13 print('success')
14 conn = sqlite3.connect('2015大学排名(12).db')
15 cur = conn.cursor()
16 cur.execute('SELECT * FROM University')
17 li = cur.fetchall()
18 i=0
19 for line in li:
20 i+=1
21 for item in line:
22 print(item, end=' ')
23 print()
24 if i==192:
25 break
26 conn.close()
输出结果:

查询本校排名及得分
代码如下:
1 # -*- coding: utf-8 -*-
2 """
3 Created on Fri May 31 12:54:03 2019
4
5 @author: Regan_White_Lin 12
6 """
7
8 import sqlite3
9 conn= sqlite3.connect("2015大学排名(12).db")
10 cur = conn.cursor()
11 cur.execute('SELECT * FROM University')
12 li = cur.fetchall() #返回所有查询结果
13 for line in li:
14 if "广东技术师范大学" in line:
15 print(line)
16 break
17 else:
18 print("查无该校数据")
19 conn.close()
输出结果:
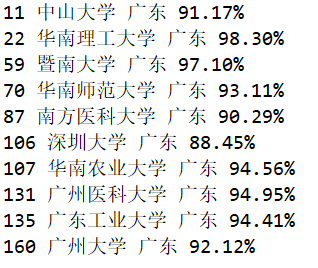
后来我自己自行在该csv文件中寻找“广东技术师范大学”,真的没有发现排名,为了确定是真的没有而非程序本身问题,我再查询了一下中山大学,得到的结果是这样的:

看来程序本身没有问题,确实可以查找学校数据。
• 查询并显示广东省学校的排名及得分
代码如下:
1 # -*- coding: utf-8 -*-
2 """
3 Created on Fri May 31 13:07:46 2019
4
5 @author: Regan_White_Lin 12
6 """
7
8 import sqlite3
9 conn= sqlite3.connect("2015大学排名(12).db")
10 cur = conn.cursor()
11 cur.execute('SELECT * FROM University')
12 li = cur.fetchall() #返回所有查询结果
13 for line in li:
14 if "广东" in line:
15 print("{} {} {} {}".format(line[0],line[1],line[2],line[5]))
16 conn.close()
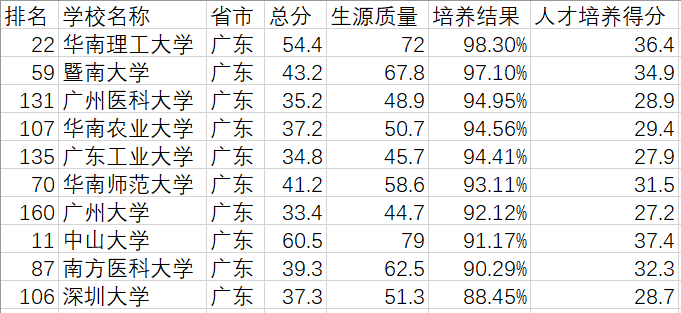
输出结果:
三、对广东省内大学的排名
在上面,我们已经输出了广东省内大学的名单,但是它们的排序方式仍然是原始的综合排名,而我们想要让名单根据某一特定方式排序(即根据各项数据进行权重分配,权重大的优先排序,次者次排序以此类推),首先将得到的名单先输出为csv文件格式,再将它写入数据库的一个新表中。
代码(输出为csv格式文件)如下:
1 # -*- coding: utf-8 -*-
2 """
3 Created on Fri May 31 13:07:46 2019
4
5 @author: Regan_White_Lin 12
6 """
7
8 import sqlite3
9 import pandas
10 def saveAsCsv(filename, tabel_list):
11 FormData = pandas.DataFrame(tabel_list)
12 FormData.columns = ["排名","学校名称","省市","总分","生源质量","培养结果","人才培养得分"]
13 FormData.to_csv(filename,encoding="gbk")
14
15 conn= sqlite3.connect("2015大学排名(12).db")
16 cur = conn.cursor()
17 cur.execute('SELECT * FROM University')
18 li = cur.fetchall()
19 #返回所有查询结果
20 list=[]
21 for line in li:
22 if "广东" in line:
23 list.append(line)
24 print("{} {} {} {}".format(line[0],line[1],line[2],line[5]))
25 saveAsCsv("2015广东大学排名爬虫.csv", list)
26 conn.close()
代码(将数据写入数据库的新表)如下:
1 # -*- coding: utf-8 -*-
2 """
3 Created on Fri May 31 12:33:56 2019
4
5 @author: Regan_White_Lin 12
6 """
7
8 import pandas
9 import sqlite3
10 conn= sqlite3.connect("2015大学排名(12).db")
11 k = pandas.read_csv('2015广东大学排名爬虫.csv',encoding='gbk')
12 k.to_sql('Guangdong', conn, if_exists='append', index=False)
13 print('success')
14 conn = sqlite3.connect('2015大学排名(12).db')
15 cur = conn.cursor()
16 cur.execute('SELECT * FROM Guangdong')
17 li = cur.fetchall()
18 i=0
19 for line in li:
20 i+=1
21 for item in line:
22 print(item, end=' ')
23 print()
24 if i==10:
25 break
26 conn.close()
效果如下:
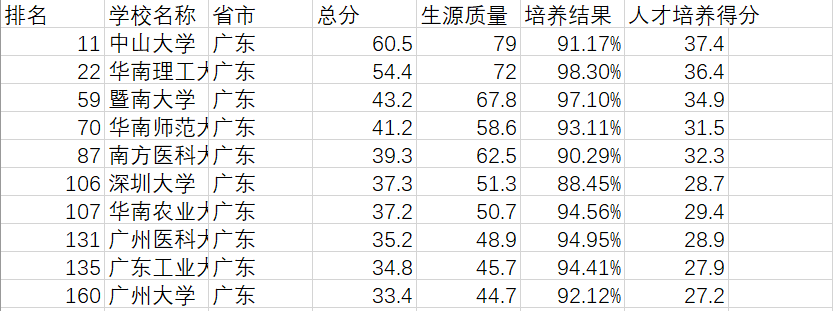
根据培养结果,从高到低排序结果如下: