数据分布
1、MySQL Cluster自动分区数据表(也可能使用用户自定义分区),将数据分布到分区中;
2、一个数据表被划分到多个Data Node分区中,数据在分区中被”striped”;
3、主键的 hashing 决定哪个分区拥有数据(自动分布);
4、对主键的一部分进行hashing也是可能的(适合sharding和数据局部性);
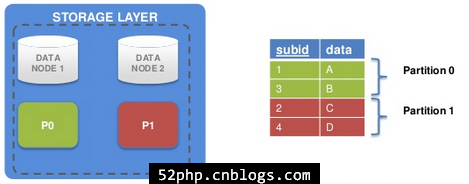
分区和数据分布
1、如果有两个数据节点(DATA NODE 1和DATA NODE 2),每个数据表都被分到两个分区中。
2、subid是主键,对主键subid进行的hashing决定分区。当然对主键的一分部分(part of PK)进行hashing也是可能的。
- -奇数主键(绿色部分)
- -偶数主键(红色部分)
副本(Replicas)
1、为了提供冗余和快速故障转移,分区之间是同步复制的;
2、最常用的是用两个副本(两份数据):
- - 使用1个,2个,3个,4个副本也都是可能的
- - NoOfReplicas=2


3、分区间的同步复制是从主分区(PRIMARY)到辅助分区(SECONDARY)
- - 当有一个变更(下图实体圆心表示变更)发生在P0的时候,它将同步复制到S0
- - 这个变更在事务commit的时候被持久化
- - P0或S0将被更新,或什么都不做

数据分布 – 磁盘日志记录(disk logging)
1、数据在commit之后会在主内存中(main memory)
(1).但是改变(changes)是REDO日志记录的(REDO LOGGED),而REDO日志是每N毫秒(推荐1000ms)刷新到磁盘
由TimeBetweenGlobalCheckpoints参数控制
类似innodb-flush-log-at-trx_commit=2
(2).数据同时被checkpoint到磁盘
2、磁盘日志记录使得恢复一个完全失败的cluster成为可能
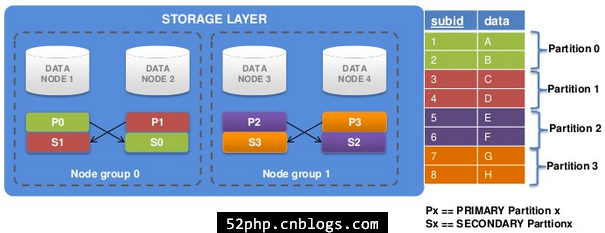
节点组(Node groups)
1、共享同样数据的节点属于同一个节点组
2、一个节点组包含节点数等于副本数。(下图使用NoOfReplicas=2)

3、两个副本-四个数据节点
(1).四个数据节点-四个分区-两个副本
(2).四个节点和两个副本–>两个节点组
- 节点组数目 = 总节点数 / 副本数
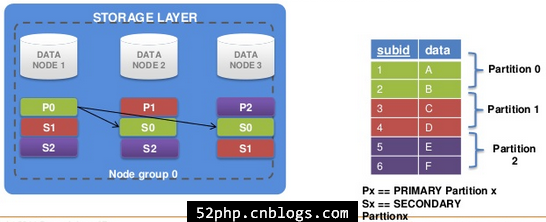
4、三个副本-三个数据节点
(1).三个数据节点-三个分区
- 更多的副本,“写”更慢
(2).三个节点和三个副本–>一个节点组(这种方式不常用)
- 两个副本是惯例
5、副本使用建议
(1).推荐使用两个副本- 性能和可用性是最好的折衷
(2).三个或四个副本写比较慢,使用这种方式部署相对更少
(3).“写”成本
- 1个副本(没冗余): cost X
- 2个副本: cost 2X
- 三个副本: cost 3X
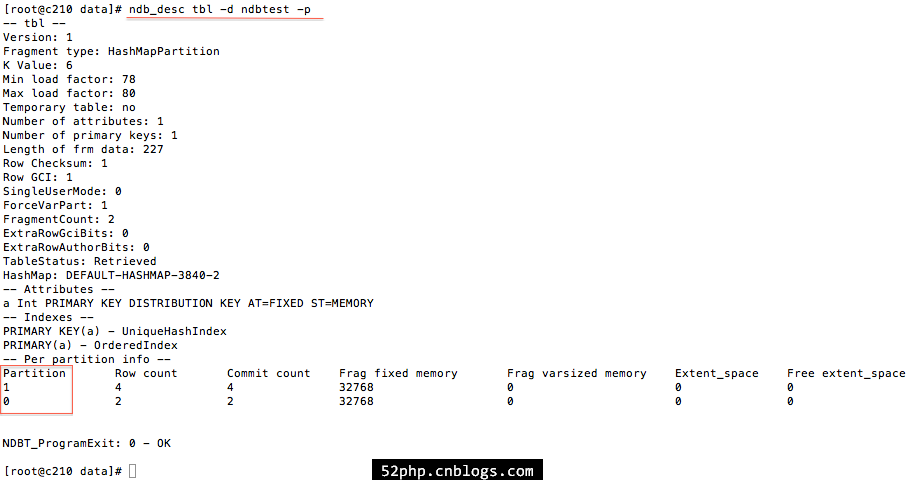
验证数据分布
用法:
ndb_desc -c connect_string tbl_name -d db_name [-p]
mysql> select * from ndbtest.tbl; +---+ | a | +---+ | 3 | | 6 | | 5 | | 1 | | 2 | | 4 | +---+ 6 rows in set (0.01 sec) mysql>
参考: