hdfs在生产应用中主要是针对客户端的开发,从hdfs提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件。
搭建开发环境
方式一(windows环境下):
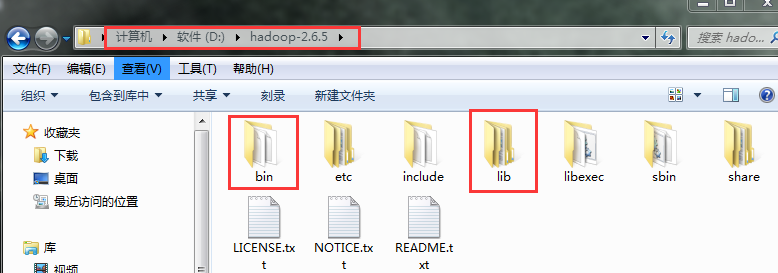
1、将官网下载的hadoop安装包解压,并记住下图所示的目录

2、创建java project,右键工程--->build path--->Configure build path
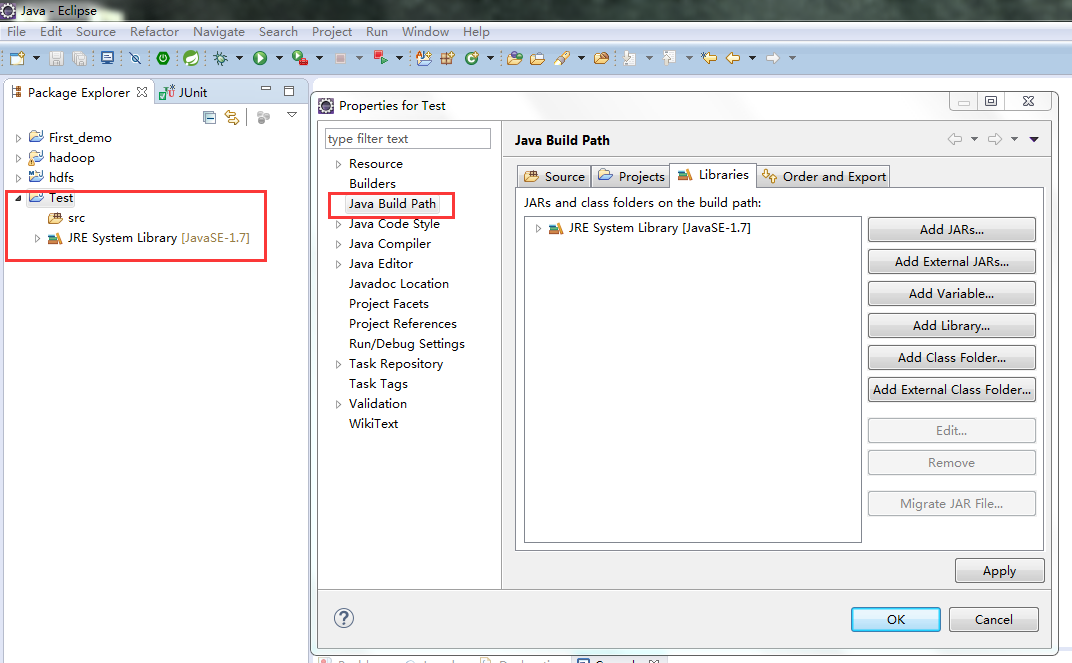
3、进行如下图操作

4、进行如下图操作
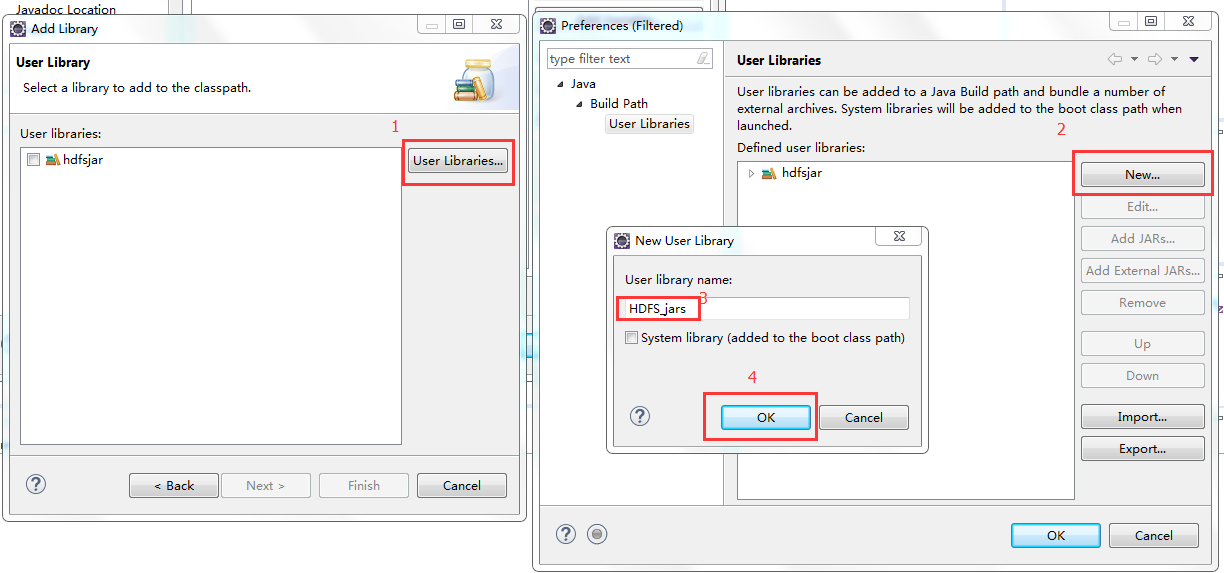
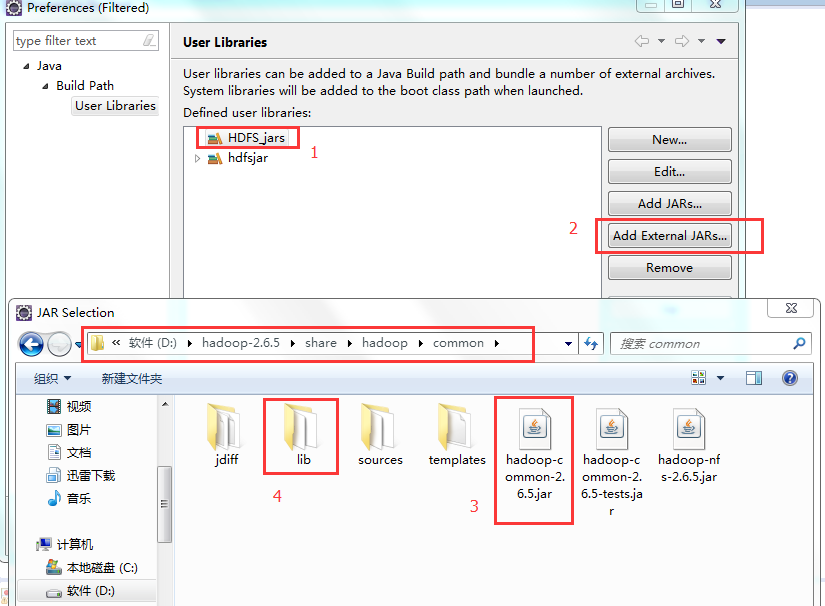
5、导入jar包(图示目录下的common包以及lib目录下的所有包 还有hdfs包以及其lib目录下的所有jar包)

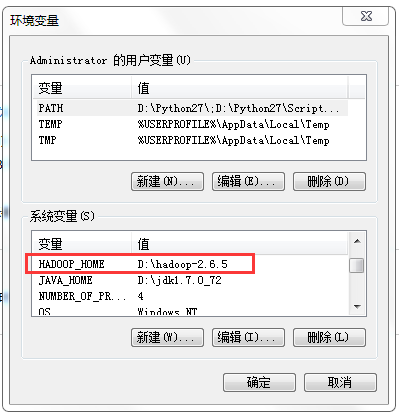
6、配置环境变量
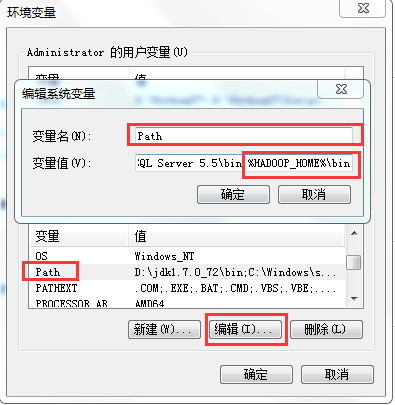
7、重要!重要!重要!!!
将安装包下的lib和bin目录用对应windows版本平台编译的本地库替换(编译源码包可自行百度一下相关步骤,或是直接下载别人编译好的bin和lib)
方式二:
1、创建maven项目
2、将maven项目的JRE换成自己机器上的1.7(默认是1.5的版本)

3、写入pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xiaojie</groupId>
<artifactId>hdfs</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<!-- <hadoop.version>2.6.5</hadoop.version> -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
</dependencies>
</project>
上传文件
package hadoop;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
import java.util.Iterator;
import java.util.Map.Entry;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsClientDemo {
FileSystem fs = null;
Configuration conf = null;
@Before
public void init() throws Exception{
// new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml
// 然后再加载classpath下的hdfs-site.xml
conf = new Configuration();
/* 如果我们的代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,
conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为:
file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象*/
// 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置
// 我们要访问的hdfs的URI
conf.set( "fs.defaultFS", "hdfs://192.168.25.13:9000");
// 获得hdfs文件系统实例对象,以root身份链接 java.net.URI
fs = FileSystem.get(new URI("hdfs://192.168.25.13:9000"),conf,"root");
}
// 上传文件
@Test
public void upload() throws Exception{
fs.copyFromLocalFile(new Path("c:/test.txt"), new Path("/"));
fs.close();
}
// 使用流的方式上传文件
@Test
public void upload() throws IllegalArgumentException, IOException{
// true表示是否覆盖原文件
FSDataOutputStream out = fs.create(new Path("/stream.tex"),true);
FileInputStream in = new FileInputStream("c:/test2.txt");
// org.apache.commons.io下的IOUtils
IOUtils.copy(in, out);
}
}
使用hdfs的web工具,查看是否上传成功
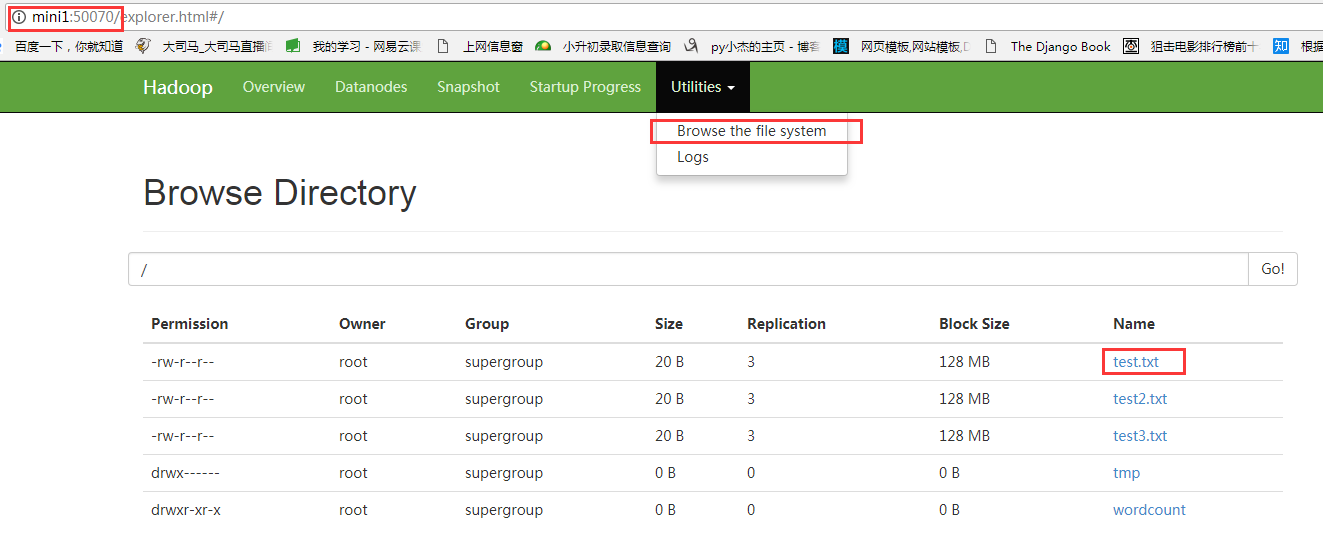
下载文件
注意:
若上面开发环境搭建过程中hadoop报下的bin包和lib包兼容有问题则download()方法会执行失败(linux下开发不会报错)。
解决方法1:在自己的windows电脑上编译hadoop源码,用编译后的bin和lib替换。
解决方法2:使用download2()的方法下载。
// 下载文件
@Test
public void download() throws Exception {
fs.copyToLocalFile(new Path("/test2.txt"), new Path("c:/t22.txt"));
fs.close();
}
// 下载文件兼容版
// 以流的方式下载
@Test
public void download2() throws Exception {
FSDataInputStream in = fs.open(new Path("/test2.txt"));
OutputStream out = new FileOutputStream("c:/t23.txt");
// org.apache.commons.io.IOUtils(common中的和hadoop中的IOUtils都可以,有点小差别)
IOUtils.copy(in, out);
}
// 可自定从哪里开始读以及读几个字节,以流的方式
@Test
public void diy() throws IllegalArgumentException, IOException{
FSDataInputStream in = fs.open(new Path("/test2.txt"));
// 指定从哪个字节开始读
in.seek(5);
FileOutputStream out = new FileOutputStream("c:/t22.txt");
IOUtils.copy(in, out);
// IOUtils.copyLarge(input, output, inputOffset, length)
}
// 指定打印到屏幕,以流的方式
@Test
public void diy2() throws IllegalArgumentException, IOException{
FSDataInputStream in = fs.open(new Path("/test2.txt"));
// 指定从哪个字节开始读
in.seek(5);
IOUtils.copy(in, System.out);
}
打印配置文件信息
// 打印配置文件
@Test
public void printtConf(){
Iterator<Entry<String, String>> it = conf.iterator();
while(it.hasNext()){
Entry<String, String> ent = it.next();
System.out.println(ent.getKey()+":"+ent.getValue());
}
}
创建目录
//创建目录
@Test
public void mkdir() throws IllegalArgumentException, IOException{
// 可递归创建目录,返回值表示是否创建成果
boolean b = fs.mkdirs(new Path("/mkdir"));
System.out.println(b);
}
删除目录或文件
// 删除目录或文件
@Test
public void delete() throws IllegalArgumentException, IOException{
// true表示递归删除,返回值表示是否删除成功
boolean b = fs.delete(new Path("/test"), true);
System.out.println(b);
}
打印指定路径下的文件信息(不含目录,可递归)
// 打印指定路径下的文件信息
@Test
public void listFile() throws FileNotFoundException, IllegalArgumentException, IOException{
// true表示是否递归 返回的是迭代器对象
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus file = listFiles.next();
System.out.println("owner:"+file.getOwner());
System.out.println("filename:"+file.getPath().getName());
System.out.println("blocksize:"+file.getBlockSize());
System.out.println("replication:"+file.getReplication());
System.out.println("permission:"+file.getPermission());
BlockLocation[] blockLocations = file.getBlockLocations();
for (BlockLocation b : blockLocations) {
System.out.println("块的起始偏移量:"+b.getOffset());
System.out.println("块的长度:"+b.getLength());
String[] hosts = b.getHosts();
for (String host : hosts) {
System.out.println("块所在的服务器:"+host);
}
}
System.out.println("=========================================");
}
}
打印指定路径下的目录或文件信息(不可递归)
// 打印指定路径下的文件或目录
@Test
public void list() throws FileNotFoundException, IllegalArgumentException, IOException{
// 返回的是数组,不能递归目录中的内容
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus fs: listStatus){
System.out.println((fs.isFile()?"file:":"directory:")+fs.getPath().getName());
}
}