Redis为什么这么快
redis表现突出的原因: 1、在内存中进行操作 2、高效的数据结构。
一方面,这是因为它是内存数据库,所有操作都在内存上完成,内存的访问速度本身就很快。
另一方面,这要归功于它的数据结构。这是因为,键值对是按一定的数据结构来组织的,操作键值对最终就是对数据结构进行增删改查操作,所以高效的数据结构是 Redis 快速处理数据的基础。
==================================================
Redis的数据类型及其数据结构
Redis 键值对中值的数据类型,也就是数据的保存形式:String(字符串)、List(列表)、Hash(哈希)、Set(集合)和 Sorted Set(有序集合)。
数据结构
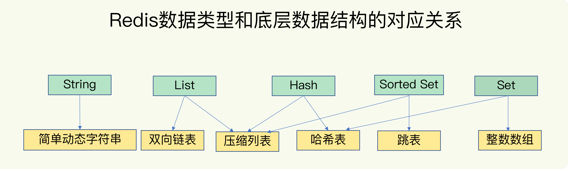
可以看到,String 类型的底层实现只有一种数据结构,也就是简单动态字符串。
而 List、Hash、Set 和 Sorted Set 这四种数据类型,都有两种底层实现结构。通常情况下,我们会把这四种类型称为集合类型,它们的特点是一个键对应了一个集合的数据。
1、简单动态字符串
简单动态字符串(Simple dynamic String,SDS)用作Redis的默认字符串表示。
SDS定义

1、SDS可通过len属性直接获取本身长度。
2、不会造成缓冲区溢出。SDS的空间分配策略会自动对缓冲区进行扩容处理。
3、SDS通过空间预分配以及惰性空间释放来减少修改字符串时带来的内存重分配次数
a、空间预分配:对SDS修改后,如果SDS长度将小于1MB,那么程序将会分配和len属性同样大小的未使用空间;如果长度将大于1MB时,那么程序将会分配1MB的未使用空间。
b、惰性空间释放:当SDS需要缩短SDS保存的字符串时,程序并不会立即使用内存重分配来回缩后多出来的字节,而是使用free属性讲这些字节的数量记录下来,并等待将来使用。
4、二进制安全。
Redis的键和值的结构组织
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。
一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。每个哈希桶中保存了键值对数据。哈希桶中的元素保存的并不是值本身,而是指向具体值的指针。
在下图中,可以看到,哈希桶中的 entry 元素中保存了*key和*value指针,分别指向了实际的键和值,这样一来,即使值是一个集合,也可以通过*value指针被查找到。
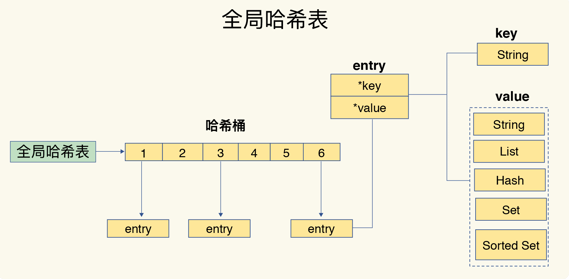
O(1) 的时间复杂度来快速查找到键值对。
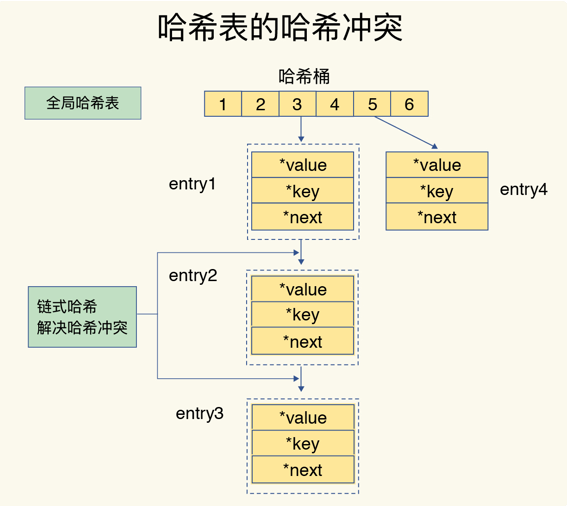
hash冲突
hash冲突解决方式---链式哈希:指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。如图:
rehash操作
当哈希桶的链表过长时,也会导致查询效率低下,这个时候需要rehash。
为了使 rehash 操作更高效,Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
1、给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
2、把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
3、释放哈希表 1 的空间。
为了解决第2步可能带来的Resid阻塞,Redis 采用了渐进式 rehash。
简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。如下图所示:
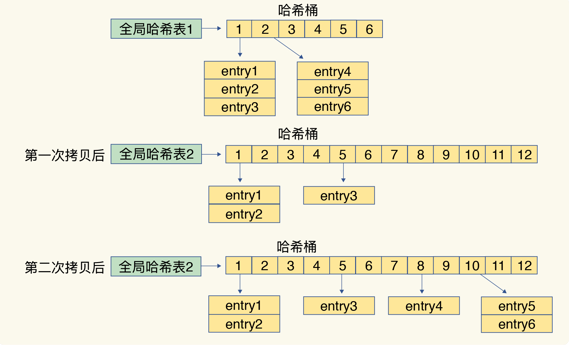
渐进式rehash执行时,除了根据键值对的操作来进行数据迁移,Redis本身还会有一个定时任务在执行rehash,如果没有键值对操作时,这个定时任务会周期性地(例如每100ms一次)搬移一些数据到新的哈希表中,这样可以缩短整个rehash的过程。
集合类型的数据操作效率
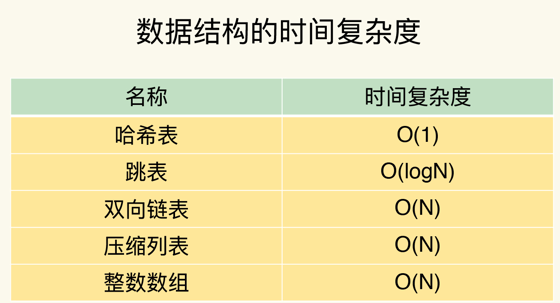
集合类型的底层数据结构主要有 5 种:整数数组、双向链表、哈希表、压缩列表和跳表。
整数数组和双向链表也很常见,它们的操作特征都是顺序读写,也就是通过数组下标或者链表的指针逐个元素访问,操作复杂度基本是 O(N),操作效率比较低;
五种数据形式的底层实现
a,string:简单动态字符串
b,list:双向链表,压缩列表
c,hash:压缩列表,哈希表
d,Sorted Set:压缩列表,跳表
e,set:哈希表,整数数组
压缩列表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
跳表
跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:
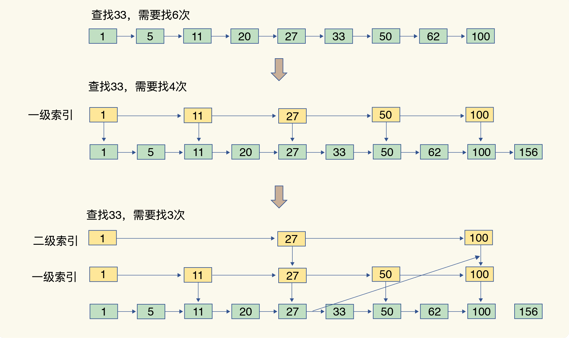
当数据量很大时,跳表的查找复杂度就是 O(logN)。
单元素操作是基础;
范围操作非常耗时;
统计操作通常高效;
例外情况只有几个。
单元素操作,是指每一种集合类型对单个数据实现的增删改查操作。例如,Hash 类型的 HGET、HSET 和 HDEL,Set 类型的 SADD、SREM、SRANDMEMBER 等。这些操作的复杂度由集合采用的数据结构决定,例如,HGET、HSET 和 HDEL 是对哈希表做操作,所以它们的复杂度都是 O(1);Set 类型用哈希表作为底层数据结构时,它的 SADD、SREM、SRANDMEMBER 复杂度也是 O(1)。
范围操作,是指集合类型中的遍历操作,可以返回集合中的所有数据,比如 Hash 类型的 HGETALL 和 Set 类型的 SMEMBERS,或者返回一个范围内的部分数据,比如 List 类型的 LRANGE 和 ZSet 类型的 ZRANGE。这类操作的复杂度一般是 O(N),比较耗时,我们应该尽量避免。 SCAN 系列操作(包括 HSCAN,SSCAN 和 ZSCAN),这类操作实现了渐进式遍历,每次只返回有限数量的数据,避免Redis 阻塞。
统计操作,是指集合类型对集合中所有元素个数的记录,例如 LLEN 和 SCARD。这类操作复杂度只有 O(1),这是因为当集合类型采用压缩列表、双向链表、整数数组这些数据结构时,这些结构中专门记录了元素的个数统计,因此可以高效地完成相关操作。
例外情况,是指某些数据结构的特殊记录,例如压缩列表和双向链表都会记录表头和表尾的偏移量。这样一来,对于 List 类型的 LPOP、RPOP、LPUSH、RPUSH 这四个操作来说,它们是在列表的头尾增删元素,这就可以通过偏移量直接定位,所以它们的复杂度也只有 O(1),可以实现快速操作。
问题:
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?
答:
1、内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
2、数组对CPU高速缓存支持更友好,所以Redis在设计时,集合数据元素较少情况下,默认采用内存紧凑排列的方式存储,同时利用CPU高速缓存不会降低访问速度。当数据元素超过设定阈值后,避免查询时间复杂度太高,转为哈希和跳表数据结构存储,保证查询效率。