Redis 的常用的用途:
- 缓存高频次访问的数据,降低数据库IO
- 分布式架构,做session共享
- 利用zset类型可以存储排行榜
- 利用list做简易MQ或存储最新的n个数据
5 种基础数据结构
Redis 有5种数据结构,分别为:
-
- string(字符串)
- list(列表)
- hash(字典)
- set(集合)
- zset(有序集合)
String(字符串)
字符串 string 是 Redis 最简单的数据结构,它的内部表示就是一个字符数组。Redis 所有的数据结构都以唯一的key字符串作为名称,然后通过这个唯一key值来获取相应的value数据。不同类型的数据结构的差异就在于 value 的结构不一样。
字符串结构使用非常广泛,一个常见的用途就是缓存用户信息。我们将用户信息结构体使用 JSON 序列化成字符串,然后将序列化的字符串塞进Redis来缓存。同样,取用户信息会经过一次反序列化的过程。
Redis 的字符串是简单动态字符串(Simple Dynamic String),是可以修改的字符串,内部结构的实现类似于 Java 的 ArrayList ,采用预分配冗余的方式来减少内存的频繁分配。内部为当前字符串分配的实际空间 capacity 一般要高于实际字符串长度len。当字符串长度小于1MB时,扩容都是加倍现有的空间。如果字符串长度超过1MB,扩容时一次只会扩容1MB的空间。需要注意的是字符串的最大长度是 512 MB。
list(列表)
Redis 的列表相当于Java语言里面的 LinkedList,注意它是链表而不是数组。这意味着list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n)。列表中的每个元素都使用双向指针顺序,串起来可以同时支持前向后向遍历。
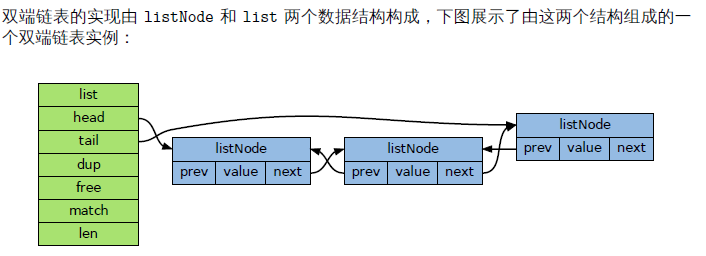
当列表弹出了最后一个元素后,该数据结构被自动删除,内存被自动回收。
Redis 的列表结构常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串,塞进Redis的列表,另一个线程从这个列表中轮询数据进行处理。
右边进左边出:队列
队列是先进先出的数据结构,常用于消息队列和异步逻辑处理,它会确保元素的访问顺序性。
127.0.0.1:6379> rpush books Python Java Go (integer) 3 127.0.0.1:6379> llen books (integer) 3 127.0.0.1:6379> lpop books "Python" 127.0.0.1:6379> lpop books "Java" 127.0.0.1:6379> lpop books "Go" 127.0.0.1:6379> lpop books (nil) 127.0.0.1:6379>
右边进右边出:栈
栈是先进后出的数据结构,跟队列正好相反。拿Redis的列表数据结构来做栈使用的业务场景并不多。
127.0.0.1:6379> rpush books Python C++ Java (integer) 3 127.0.0.1:6379> rpop books "Java" 127.0.0.1:6379> rpop books "C++" 127.0.0.1:6379> rpop books "Python" 127.0.0.1:6379> rpop books (nil) 127.0.0.1:6379>
慢操作
lindex 相当于Java 链表的 get(int index)方法,它需要对链表进行遍历,性能随着参数 index 增大而变差。
ltrim和字面的含义不太一样,ltrim的两个参数 start_index 和 end_index 定义了一个区间,在这个区间内的值,ltrim要保存,区间之外的则统统砍掉。我们可以通过ltrim 来实现一个特定长度的链表。
127.0.0.1:6379> rpush books python cobol php (integer) 3 127.0.0.1:6379> lindex books 1 # O(n) 慎用 "cobol" 127.0.0.1:6379> lrange books 0 -1 # 获取所有元素,O(n) 慎用 1) "python" 2) "cobol" 3) "php" 127.0.0.1:6379> ltrim books 1 -1 # O(n) 慎用 OK 127.0.0.1:6379> lrange books 0 -1 1) "cobol" 2) "php" 127.0.0.1:6379> ltrim books 1 0 # 这其实是清空了整个列表,因为区间范围长度为负 OK 127.0.0.1:6379> llen books (integer) 0 127.0.0.1:6379>
快速列表
如果再深入一点,你会发现Redis底层存储的不是一个简单的 linkedlist,而是称之为 “快速链表” (quicklist) 的一个结构。
首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是 ziplist,即压缩列表。它将所有的元素彼此紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。因为普通的链表需要的附加指针空间太大,会浪费空间,还会加重内存的碎片化,比如某普通链表里存的只是 int 类型的数据,结构上还需要两个额外的指针 prev 和 next。所以Redis 将链表和 ziplist 结合起来组成了 quicklist,也就是将多个 ziplist 使用 双向 指针串起来使用。quicklist 既满足了快速的插入删除性能,又不会出现太大的空间冗余。
hash(字典)
Redis 的字典相当于 Java 语言里面的 HashMap,它是无序字典,内部存储了很多键值对。实际结构上与 Java 的 HashMap 也是一样的,都是 “数组+链表”二维结构。
不同的是,Redis 的字典的值只能是字符串,另外它们rehash 的方式不一样,因为 Java 的 HashMap 在字典很大时,rehash 是个耗时的操作,需要一次性全部 rehash。
Redis 为了追求高性能,不能堵塞服务,所以采用了渐进式 rehash 策略。
渐进式 rehash会在 rehash 的同时,保留新旧两个 hash 结构,查询时会同时查询两个 hash 结构,然后在后续的定时任务以及hash操作指令中,循序渐进地将旧 hash 的内容一点点地迁移到新的 hash 结构中。当迁移完成了,就会使用新的 hash 结构取而代之。
当 hash 移除了最后一个元素之后,该数据结构被自动删除,内存被回收。
hash 结构也可以来存储用户信息,与字符串需要一次性全部序列化整个对象不同,hash 可以对用户结构中的每个字段单独存储。这样当我们需要获取用户信息时可以进行部分获取。而以整个字符串的形式去保存用户信息的话,就只能一次性全部读取,这样就会浪费网络流量。
hash也有缺点,hash结构的存储消耗要高于单个字符串。到底该使用 hash 还是 字符串,需要根据实际情况再三权衡。
127.0.0.1:6379> hset books java "think in java" # 命令行的字符串如果包含空格,要用引号括起来 (integer) 1 127.0.0.1:6379> hset books go "concurrency in go" (integer) 1 127.0.0.1:6379> hset books python "python cookbook" (integer) 1 127.0.0.1:6379> hgetall books # entries(), key 和 value 间隔出现 1) "java" 2) "think in java" 3) "go" 4) "concurrency in go" 5) "python" 6) "python cookbook" 127.0.0.1:6379> hlen books (integer) 3 127.0.0.1:6379> hget books java "think in java" 127.0.0.1:6379> hset books go "learning go programming" # 更新操作,所以返回 0 (integer) 0 127.0.0.1:6379> hget books go "learning go programming" 127.0.0.1:6379> hmset books java "effective java" python "learning python" go "modern go programming" # 批量 set OK 127.0.0.1:6379>
同字符串一样,hash结构中的单个子 key 也可以进行计数,它对应的指令是 hincrby,和 incr 的使用方法基本一样。
127.0.0.1:6379> hset employee salary 15000 (integer) 1 127.0.0.1:6379> hincrby employee salary 3000 (integer) 18000 127.0.0.1:6379>
set (集合)
Redis的集合相当于 Java 语言里面的 HashSet,它内部的键值对是无序的、唯一的。它的内部实现相当于一个特殊的字典,字典中所有的value 都是一个值 NULL。
当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
set 结构可以用来存储在某活动中中奖的用户ID,因为有去重功能,可以保证一个用户不会中奖两次。
127.0.0.1:6379> clear 127.0.0.1:6379> sadd books python (integer) 1 127.0.0.1:6379> sadd books python # 重复 (integer) 0 127.0.0.1:6379> sadd books java go (integer) 2 127.0.0.1:6379> smembers books # 注意顺序,和插入的顺序不一致,因为 set 是无序的 1) "java" 2) "go" 3) "python" 127.0.0.1:6379> sismember books java # 查询某个 value 是否存在,相对于 contains(o) (integer) 1 127.0.0.1:6379> sismember books rust (integer) 0 127.0.0.1:6379> scard books # 获取长度相当于 count() (integer) 3 127.0.0.1:6379> spop books # 弹出一个 "go" 127.0.0.1:6379>
zset (有序列表)
zset 可能是 Redis 提供的最有特色的数据结构,它也是在面试中面试官最爱问的数据结构。
它类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面他是一个set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。它的内部实现用的是一种叫做 “跳跃列表” 的数据结构。
zset 中的最后一个 value 被移除后,数据类型被自动删除,内存被回收。
zset 可以用来存储粉丝列表,value 值是粉丝的用户 ID,score 是关注时间。我们可以对粉丝列表按关注时间进行排序。
zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们对成绩按分数进行排序就可以得到他的名次。
127.0.0.1:6379> zadd books 9.0 "think in java" (integer) 1 127.0.0.1:6379> zadd books 8.9 "java concurrency" (integer) 1 127.0.0.1:6379> zadd books 8.6 "java cookbook" (integer) 1 127.0.0.1:6379> zrange books 0 -1 # 按 score 排序列出,参数区间为排名范围 1) "java cookbook" 2) "java concurrency" 3) "think in java" 127.0.0.1:6379> 127.0.0.1:6379> zrevrange books 0 -1 # 按 score 逆序列出,参数区间为排名范围 1) "think in java" 2) "java concurrency" 3) "java cookbook" 127.0.0.1:6379> zcard books # 相当于 count() (integer) 3 127.0.0.1:6379> zscore books "java concurrency" # 获取指定 value 的 score "8.9000000000000004" # 内部 score 使用 double 类型进行存储,所有存在小数点精度问题 127.0.0.1:6379> zrank books "java cookbook" # 排名 (integer) 0 127.0.0.1:6379> zrangebyscore books 0 8.91 # 根据分值区间遍历 1) "java cookbook" 2) "java concurrency" 127.0.0.1:6379> # 根据分值区间 (-inf, 8.91] 遍历 zset, 同时返回分值。inf 代表 infinite,无穷大的意思 127.0.0.1:6379> zrangebyscore books -inf 8.91 withscores 1) "java cookbook" 2) "8.5999999999999996" 3) "java concurrency" 4) "8.9000000000000004" 127.0.0.1:6379> zrem books "java concurrency" # 删除 value (integer) 1 127.0.0.1:6379> zrange books 0 -1 1) "java cookbook" 2) "think in java" 127.0.0.1:6379>
跳跃列表
zset 内部的排序功能是通过 “跳跃列表” 数据结构来实现的,它的数据结构非常特殊,也比较复杂。
因为 zset 要支持随机的插入和删除,所以它不宜使用数组来表示。
我们先看一个普通的链表的数据结构,我们需要这个链表按照 score 值进行排序。这意味着当有新元素需要插入时,要定位到指定位置的插入点,这样才可以继续保证链表是有序的。通常我们会通过二分查找来找到插入点,但是二分查找的对象必须是数组,只有数组才可以支持快速为位置定位,链表做不到,那该怎么办?
假设一家创业公司,刚开始只有几个人,团队成员之间人人平等,都是联合创始人。随着公司的成长,人数渐渐变多,团队沟通成本随之增加。这时候就会引入组长制,对团队进行划分。每个团队会有一个组长。开会的时候分团队进行,多个组长之间还会有自己的会议安排。当公司规模进一步扩展,需要再增加一个层级-----部门,每个部门会从组长列表中再推出一个代表作为部长。部长之间还会有自己的高层会议安排。
跳跃列表就类似于这种层级制,最下面一层所有的元素都会串起来。然后每隔几个元素挑选出一个代表,再将这几个代表使用另外一级指针串起来。然后在这些代表里再挑出二级代表,再串起来。最终形成了金字塔结构。
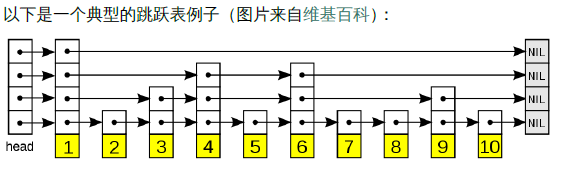
“跳跃列表” 之所以 “跳跃”,是因为内部的元素可能 “身兼数职”。
定位插入点时,先在顶层进行定位,然后下潜到下一级定位,一直下潜到最底层找到合适的位置,将新元素插进去。你也许会问,那新插入的元素如何才有机会 “身兼数职”呢?
跳跃列表采取了一个随机策略来决定新元素可以兼职到第几层。