xpath
xpath的作用就是两个字“定位”,运用各种方法进行快速准确的定位,推荐两个非常有用的的firefox工具:firebug和xpath checker
使用介绍
定位
1.依靠自己属性,文本定位
//td[text()='xxx']
//div[contains(@class,'xxx')]
//div[@class='xxx' and @type='xxx']
2.依靠父节点定位
//div[@class='xxx']/div
//div[@id='xxx']/div
3.依靠子节点定位
//div[div[@id='xxx']]
//div[div[@name='xxx']]
4.混合型
//div[div[@name='xxx']]/img
//td[a/font[contains(text(),'xxx')]]//input[@type='xxx']
xpath的学习-拓展
1.following-sibling
following-sibling即为“选择当前节点之后的所有同级节点”,那么没有加上“sibling”关键字的,搜索的就是之上/之下的所有节点,忽略同级概念,例如:
<div>
<input id="123">
<input>
</div>
要定位第二个input://input[@id='123']/following-sibling::input
2.preceding-sibling
preceding-sibling的解释是“选取当前节点之前的所有同级节点”,那么没有加上“sibling”关键字的,搜索的就是之上/之下的所有节点,忽略同级概念, preceding-sibling和following-sibling是刚好相反的
<div>
<span>text</span>
<input id="123">
</div>
要定位第二个input://input[@id='123']/preceding-sibling::span
3.contains
和字面意思一样就是包含,例如://div[contains(@class,'xxx')]
4.starts-with
和字面意思一样就是以某某开头,例如://input[starts-with(@class,'xxx')]
5.not
就是否定的意思
比如找一个id不为123的input:input[not[id='123']]
又如找一个文本中不包含xxx字段的span://span[not(contains(text(),'xxx'))]
xpath的学习-补充
绝对路径 html/body/div/span[2]/input[2] 中间结构变化,就失效
相对路径 //开始,在整个html source里找,不管在什么位置
索引[x] //div/input[2] div下面第二个input
position()=2position()>3position()<3
例如html:<div id="positions">
<input>
<span>test position()1</span>
<span>test position()2</span>
<span>test position()3</span>
<span>test position()4</span>
<span>test position()5</span>
</input>
</div>
获取第一个span,可以是//div[@id='positions']/span[1],也可以是//div[@id='positions']/span[position()=1]
//div[@id='positions']/span[position()>3]就是定位了test position()4和test position()5
//div[@id='positions']/span[position()<3]就是定位了test position()1和test position()2
last()last()-1
以上面的html为例子,获取最后一个span://div[@id='positions']/span[last()]
以上面的html为例子,获取倒数第二个span://div[@id='positions']/span[last()-1]
属性定位@class //div[@class] 有class属性的div
属性值定位,前面已经讲过了 //div[@class='xxx']
功能关键字
1.常用
and/[][],比如://span[@name='xxx' and text()='xxx']也是可以写成//span[@name='xxx'][text()='xxx']
or,比如以上面html为例子,定位文本为test position()5和test position()4的span://div[@id='positions']/span[text()='test position()5' or text()='test position()4']
not,contains,starts-with
ends-with 在xpath中是没有这个的
2.不常用的
substring,substring-before,substing-after
sbustring(str,start-position,length) 比如html:
<div id="xxx">
<span name="?-xxxxx-09">text</span>
</div>
定位上面html中span://div[@id='xxx']/span[substring(@name,3,5)='xxxxx']
substring-before的用法,比如html
<div id="xxx">
<span class="spanclass1-789">text</span>
</div>
定位上面html中span://div[@id="xxx"]/span[sbustring-before(@class,"-")="spanclass1"]
substring-after的用法,比如html
<div id="xxx">
<span class="789-spanclass2">text</span>
</div>
定位上面html中span://div[@id="xxx"]/span[sbustring-after(@class,"-")="spanclass22"]
通配符 *
比如//span[@*="xxx"]指定位span中任意属性包含xxx的
比如//*[@*="xxx"]指定位页面中任意属性保护xxx的标签
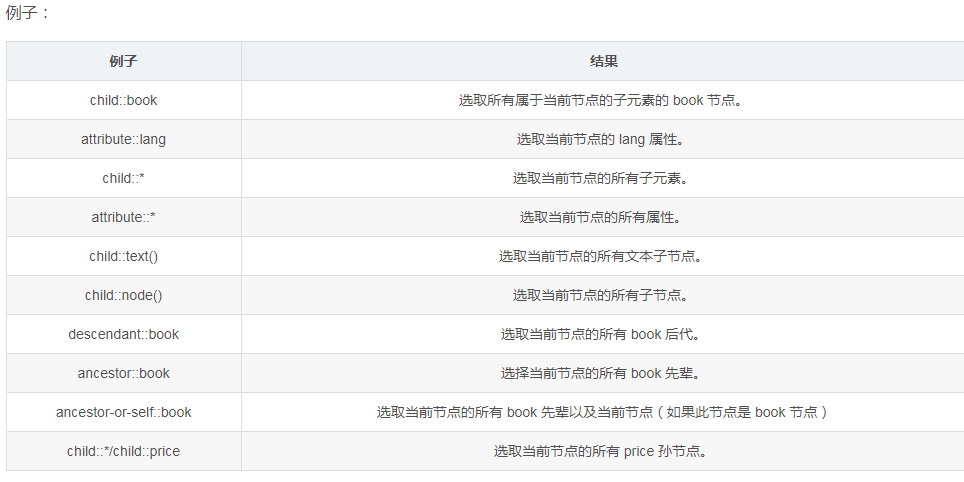
Axes 轴
parent 父节点
ancestor 祖先节点,包括父节点,一层一层向上
descendant 所有子孙节点找,不管什么位置,简写//,就是xpath中出现//的情况。。//div[@class="xxx"]//input
follwing-sibling 当前元素后面的兄弟姐妹
preceding-sibling 当前元素前面的兄弟姐妹
following 当前元素后面所有元素,一直到</html>
preceding 当前元素之前所有元素,一直到<html>
ancestor-or-self
descendant-or-self
使用的时候注意加上::
系统介绍
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
XPath 使用路径表达式在 XML 文档中进行导航
XPath 包含一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是一个 W3C 标准
节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。
二、xpath语法
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
例子
以下面这个xml为例子
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
xml.xpath(“bookstore”) 表示选取 bookstore 元素的所有子节点
xml.xpath(“/bookstore”) 表示选取根元素 bookstore。
xml.xpath(“bookstore/book”) 选取属于 bookstore 的子元素的所有 book 元素。
xml.xpath(“//book”) 选取所有 book 子元素,而不管它们在文档中的位置。
xml.xpath(“bookstore//book”) 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。
xml.xpath(“//@lang”) 选取名为 lang 的所有属性。
谓语
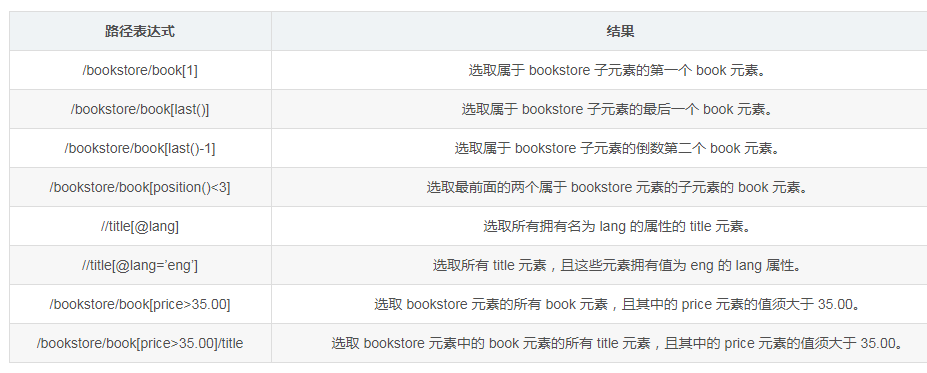

选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
//book/title | //book/price 选取 book 元素的所有 title 和 price 元素。
//title | //price 选取文档中的所有 title 和 price 元素。
/bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
三、轴

轴可定义相对于当前节点的节点集。
步的语法:
轴名称::节点测试[谓语]
四、一些函数
1. starts-with函数
获取以xxx开头的元素
例子:xpath(‘//div[stars-with(@class,”test”)]’)
2 contains函数
获取包含xxx的元素
例子:xpath(‘//div[contains(@id,”test”)]’)
3 and
与的关系
例子:xpath(‘//div[contains(@id,”test”) and contains(@id,”title”)]’)
4 text()函数
例子1:xpath(‘//div[contains(text(),”test”)]’)
例子2:xpath(‘//div[@id=”“test]/text()’)
参考:
https://blog.csdn.net/u013332124/article/details/80621638
https://www.cnblogs.com/xxyBlogs/p/4244073.html