1、什么是爬虫?
答:请求网站并提取数据的自动化程序

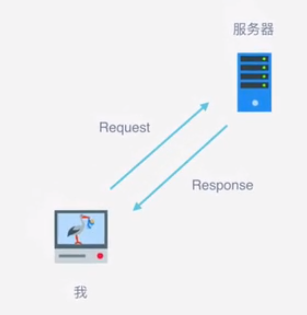
2、爬虫的基本流程
(1)、发送请求:
通过Http库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应
(2)、获取响应内容
如服务器正常响应,即返回一个Response对象,其内容即为所要获取的页面内容,但其类型可能是HTML,JSON字符串。二进制数据(包含图片/视频)等类型
(3)、解析内容
对于返回的response为HTML,我们可以使用正则表达式、网页解析库进行解析;对于JSON字符串,我们将其转为Json对象进行解析;对于二进制数据,我们需对其进行进一步处理
(4)、保存数据
这里我们需对等到的数据进行结构化的存储,可以存为文本、可以存到数据库、或者存为你想保存的数据类型,方便进一步操作
3、Request详解
(1)、请求方式:
主要为GET、POST两种类型,其他的小伙伴们了解即可(打开Chrome 浏览一个网页--右击检查开启开发者工具--单击Network选项卡找到Headers --General中的Request Method :即可查看请求方式 );GET请求特点:请求参数都在url中 /POST请求特点:Headers中多了form data ,另外url中不包含一些请求参数
(2)、请求URL(统一资源定位符,如一个网页文档、图片等具有唯一的url进行定位)
(3)、请求头(包含配置信息)【User-Agent ; Referer ;Cookies这三个为重要配置信息】
配置信息作用:服务器会根据请求头中的信息,来判断请求是否合法,决定是否返回response

(4)、请求体(只用于post请求)
4、Response详解
(1)、响应状态(200--表示成功,其他数字请参考:http://tool.oschina.net/commons?type=5)
(2)、响应头(Response Headers)
(3)、响应体(包含网页的源代码、图片、视频、二进制数据等)
5、爬虫能爬什么信息????
答:
(1)网页文本,如HTML文档、Json格式文本
(2)、图片、视频等(二进制流)
6、解析方式详解(获取响应后我们需进行解析)
(1)、直接处理(针对返回的是字符串的网页)
(2)、json解析(针对Ajax加载的数据)
(3)、正则表达式
(4)、BeautifulSoup
(5)、PyQuery
(6)、Xpath 或Css
7、解决JavaScript渲染问题
(1)、分析Ajax请求
(2)、Selenium/WebDriver
(3)、Splash
(4)、PyV8Ghost.py
8.保存数据
(1)、文本(纯文本、json、xml等)
(2)、关系型数据库(mysql oracle sql server)存为结构化的数据
(3)、非关系型数据库(mongodb redis)存为KEY-VALUE形式
(4)、二进制文件(图片、视频、音频等)
总结:小伙伴们是不是对爬虫的整个流程有了宏观的认识了!(下面让我们开始练习吧)
